相似性搜索,第一部分:kNN和倒排文件索引
kNN与倒排索引加速相似性搜索的介绍。

相似性搜索是一个问题,给定一个查询,目标是在所有数据库文档中找到最相似的文档。
介绍
在数据科学中,相似性搜索经常出现在NLP领域、搜索引擎或推荐系统中,需要检索查询的最相关文档或项目。通常,文档或项目以文本或图像的形式表示。但是,机器学习算法不能直接处理原始文本或图像,因此文档和项目通常被预处理并存储为数字向量。
有时,向量的每个组件都可以存储语义含义。在这种情况下,这些表示也称为嵌入。这样的嵌入可以有数百个维度,数量可达数百万!由于这样的巨大数量,任何信息检索系统必须能够快速检测到相关文档。
- 揭示物理感知神经网络设计模式:第06部分
- 探索指令调整语言模型:见识 Tülu-一套经过微调的大型语言模型(LLMs)套件
- 认识Gorilla:加州大学伯克利分校和微软的API增强LLM表现优于GPT-4、Chat-GPT和Claude
在机器学习中,向量也被称为对象或点。
索引
为了加速搜索性能,在数据集嵌入之上构建了一个特殊的数据结构。这种数据结构称为索引。在这个领域有很多研究,许多类型的索引已经发展出来。在选择一个索引应用于某个任务之前,有必要了解它在背后是如何操作的,因为每个索引都有不同的目的和优缺点。
在本文中,我们将研究最朴素的方法——kNN。基于kNN,我们将切换到倒排索引——用于更可扩展的搜索,可以加速搜索过程数倍。
kNN
kNN是相似性搜索中最简单和最朴素的算法。考虑一个向量数据集和一个新的查询向量Q。我们想要找到与Q最相似的前k个数据集向量。首先要考虑的是如何衡量两个向量之间的相似度(距离)。实际上,有几种相似性度量可以做到这一点。其中一些在下面的图中说明。
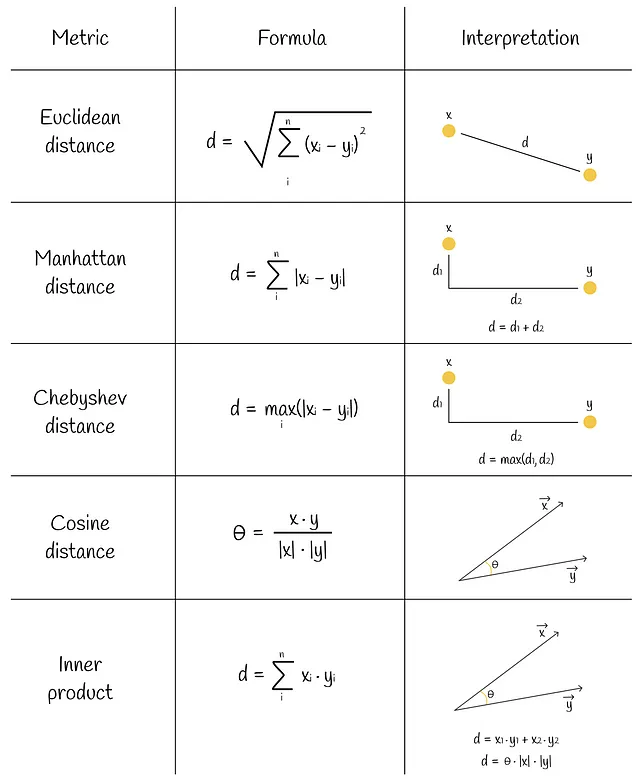
训练
kNN是机器学习中少数不需要训练阶段的算法之一。选择适当的度量后,我们可以直接进行预测。
推断
对于一个新对象,算法会耗费大量时间计算与所有其他对象的距离。之后,它会找到距离最小的k个对象,并将它们作为响应返回。

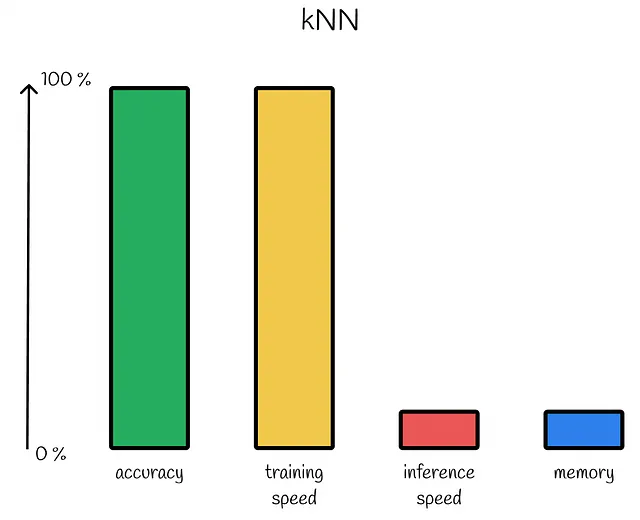
显然,通过检查到所有数据集向量的距离,kNN可以保证100%的准确结果。然而,这种暴力方法在时间性能方面非常低效。如果数据集由n个具有m个维度的向量组成,则对于每个n向量,需要O(m)时间来计算它与查询Q之间的距离,这导致了O(mn)的总时间复杂度。正如我们后面将要看到的,存在更有效的方法。
此外,原始向量没有压缩机制。想象一下一个包含数十亿个对象的数据集。可能无法将它们全部存储在RAM中!
应用场景
kNN 的应用范围有限,仅应用于以下两种场景之一:
- 数据集大小或嵌入维数相对较小。这方面可以确保算法仍然运行快速。
- 算法所需的准确性必须为100%。就准确性而言,没有其他最近邻居算法可以超越 kNN。
根据指纹识别,识别一个人的身份就是需要100%准确率的问题。如果这个人犯了罪并留下了他的指纹,那么只检索正确的结果非常重要。否则,如果系统不是100%可靠,那么另一个人可能会被错误地定罪,这是非常严重的错误。
基本上,有两种主要方法可以改进 kNN(我们将在后面讨论):
- 减少搜索范围。
- 降低向量维度。
使用这两种方法之一时,我们将不会再执行详尽的搜索。这类算法被称为近似最近邻(ANN),因为它们不能保证100%准确的结果。
倒排文件索引
**“倒排索引**(也称为倒排列表、倒排文件或倒排索引文件)是一种数据库索引,存储从内容(如单词或数字)到其在表格中、文档或一组文档中的位置的映射 – 维基百科
在执行查询时,计算查询的哈希函数并获取哈希表中的映射值。每个这些映射值都包含自己的一组潜在候选项,然后完全检查条件以成为查询的最近邻居。通过这样做,所有数据库向量的搜索范围都被减小。
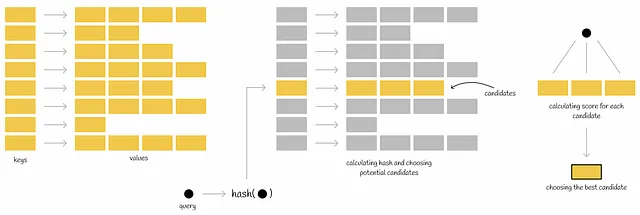
根据计算哈希函数的方式,有不同的实现方法。我们将要看的实现方法是使用沃罗诺伊图(或狄利克雷分割)的方法。
训练
算法的思想是创建几个不相交的区域,每个数据集点都将属于其中一个区域。每个区域都有自己的质心,指向该区域的中心。
有时沃罗诺伊区域也称为单元格或分区。

沃罗诺伊图的主要属性是,从质心到其区域中的任何点的距离都小于该点到另一个质心的距离。
推断
当给定一个新对象时,计算到沃罗诺伊分区的所有质心的距离。然后选择距离最近的质心,然后选取该分区中包含的向量作为候选项。
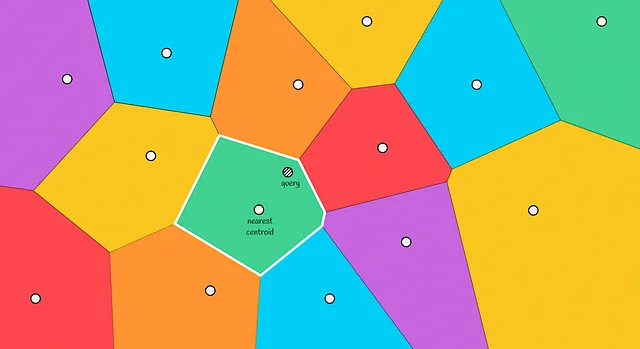
最终,通过计算到候选项的距离,并选择其中最接近的前k个,返回最终答案。
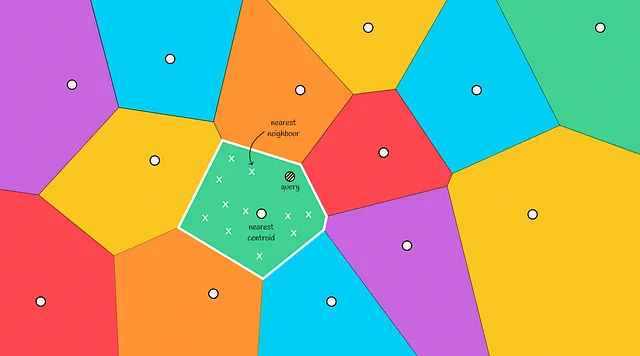
如您所见,这种方法比之前的方法快得多,因为我们不必浏览所有数据集向量。
边缘问题
随着搜索速度的增加,倒排文件也带来了一个缺点:它不能保证找到的对象总是最近的。
在下面的图中,我们可以看到这样的情况:实际上最近的邻居位于红色区域,但我们只从绿色区域选择候选项。这种情况被称为边缘问题。

当查询对象位于与另一个区域的边界附近时,通常会出现这种情况。为了减少这种情况下的错误数量,我们可以增加搜索范围并选择基于对象到顶部m个最近质心的几个区域来搜索候选项。
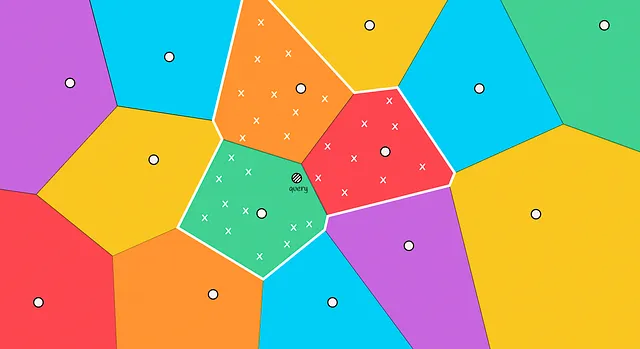
探索的区域越多,结果越准确,计算所需的时间就越长。
应用
尽管存在边缘问题,倒排文件在实践中显示出不错的结果。它非常适合在我们想要在几倍速度增长的情况下,将少量准确度下降作为交换的情况下使用。
一个使用案例示例是内容推荐系统。想象一下,它基于用户过去观看的其他电影向用户推荐电影。数据库中包含100万部电影可供选择。
- 通过使用kNN,系统确实会选择最相关的电影并向用户推荐。但是,执行查询所需的时间非常长。
- 假设使用倒排文件索引,系统将推荐第五个最相关的电影,这在现实生活中可能是正确的情况。搜索时间比kNN快20倍。
从用户体验的角度来看,很难区分这两个推荐的质量结果:从100万个可能的电影中选择的第1个和第5个最相关的结果都是好的推荐。用户可能会对这些推荐中的任何一个都感到满意。从时间的角度来看,倒排文件显然是赢家。因此,在这种情况下最好使用后一种方法。
Faiss实现
Faiss(Facebook AI搜索相似性)是一个用于优化相似性搜索的C++编写的Python库。该库提供了不同类型的索引,这些索引是用于有效存储数据和执行查询的数据结构。
基于Faiss文档中的信息,我们将看到如何创建和参数化索引。
kNN
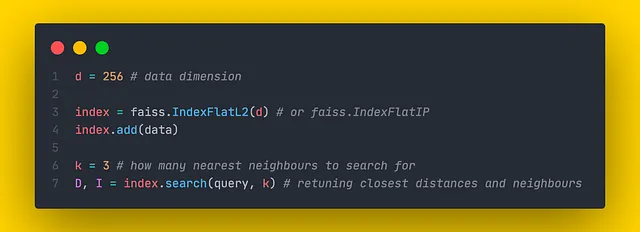
在Faiss中实现kNN方法的索引被称为flat,因为它们不压缩任何信息。它们是唯一保证正确搜索结果的索引。实际上,Faiss中存在两种类型的平面索引:
- IndexFlatL2。相似性是通过欧几里得距离计算的。
- IndexFlatIP。相似性是通过内积计算的。
这两个索引在其构造函数中都需要一个参数d:数据维度。这些索引没有可调参数。
一个向量的单个分量需要4个字节来存储。因此,要存储一个维数为d的单个向量,需要4 * d字节。

倒排文件索引
对于所描述的倒排文件,Faiss实现了IndexIVFFlat类。与kNN的情况一样,“Flat”一词表示没有对原始向量进行解压缩,它们完全存储。
要创建此索引,我们首先需要通过量化器(quantizer)来确定数据库向量将如何存储和比较。
IndexIVFFlat具有两个重要参数:
- nlist定义要在训练过程中创建的区域(Voronoi单元)的数量。
- nprobe决定要为候选项搜索多少个区域。更改nprobe参数不需要重新训练。

与先前的情况一样,我们需要4 * d字节来存储单个向量。但是现在我们还必须存储关于数据集向量所属的Voronoi区域的信息。在Faiss实现中,此信息每个向量占用8个字节。因此,存储单个向量所需的内存为:

结论
我们已经介绍了两种相似性搜索的基本算法。由于其糟糕的可扩展性,除特定情况外,有效的naive kNN几乎不应用于机器学习应用程序。另一方面,倒排文件提供了良好的启发式加速搜索的方法,其质量可以通过调整其超参数来改进。搜索性能仍然可以从不同的角度进行增强。在本文系列的下一部分中,我们将研究一种用于压缩数据集向量的方法。
相似性搜索,第2部分:乘积量化
在本文系列的第一部分中,我们介绍了kNN和倒排文件索引结构,用于执行相似性搜索…
小猪AI.com
资源
- 倒排索引|维基百科
- Faiss文档
- Faiss存储库
- Faiss索引总结
- 选择索引的指南
除非另有说明,否则所有图片均由作者提供。





