揭示物理感知神经网络设计模式:第06部分
为PINN训练引入因果关系
欢迎来到本系列的第六篇博客,在这里我们将继续探索物理感知神经网络(PINN)的设计模式🙌
在本篇文章中,我们将讨论如何在物理感知神经网络的训练中引入因果关系。正如今天我们将要看的论文所建议的那样:尊重因果关系就是你所需要的!
像往常一样,让我们先讨论当前问题,然后再转向建议的解决方法,评估过程,以及所提出方法的优缺点。最后,我们将通过探索潜在的机会来总结本文。
随着本系列的不断扩展,PINN设计模式的收集也变得越来越丰富🙌这是一个关于接下来内容的预览:
- 探索指令调整语言模型:见识 Tülu-一套经过微调的大型语言模型(LLMs)套件
- 认识Gorilla:加州大学伯克利分校和微软的API增强LLM表现优于GPT-4、Chat-GPT和Claude
- 微软人工智能推出鲸鱼(Orca):一个拥有130亿参数的模型,学习模仿大型基础模型(LFMs)的推理过程
PINN设计模式01: 优化残差点分布
PINN设计模式02: 动态解决方案间隔扩展
PINN设计模式03: 使用梯度提升训练PINN
PINN设计模式04: 梯度增强的PINN学习
PINN设计模式05: 自动超参数调整
让我们开始吧!
1. 论文概览 🔍
- 标题:尊重因果关系就是你训练物理感知神经网络所需要的
- 作者:S. Wang,S. Sankaran,P. Perdikaris
- 机构:宾夕法尼亚大学
- 链接:arXiv,GitHub
2. 设计模式 🎨
2.1 问题 🎯
物理感知神经网络(PINNs)是在各个领域结合观测数据和物理定律的重要跨越。然而,在实践中,它们经常无法处理高非线性、多尺度动力学或混沌问题,并且往往会收敛到错误的解决方案。
为什么会这样呢?
好吧,根本问题在于PINN公式中违反了因果关系,正如当前论文所揭示的那样。
在物理意义上,因果关系意味着未来时刻的状态取决于当前或过去时刻的状态。然而,在PINN训练中,这个原则可能不成立;这些网络可能在解决初始条件之前就会隐含地偏向于首先逼近未来状态的PDE解,从根本上“超前”时间,因此违反了因果关系。
相比之下,传统数值方法通过时间步进策略固有地保持了因果关系。例如,在时间上离散化PDE时,这些方法确保在逼近时间t + ∆t的解之前,已经解决了时间t的解。因此,每个未来状态都是在已解决的过去状态的基础上依次构建的,从而保持了因果关系的原则。
这种问题的理解引出了一个有趣的问题:我们如何纠正PINN中的这种因果关系违反,使其符合基本的物理定律呢?

2.2 解决方案 💡
这里的关键思想是重新制定PINN损失函数。
具体而言,我们可以引入一种动态加权方案,以考虑在不同时间位置评估的PDE残差损失的不同贡献。让我们使用图示进行详细说明。
为简单起见,假设我们的仿真空间 – 时间域中均匀采样了插值点,如下图所示:
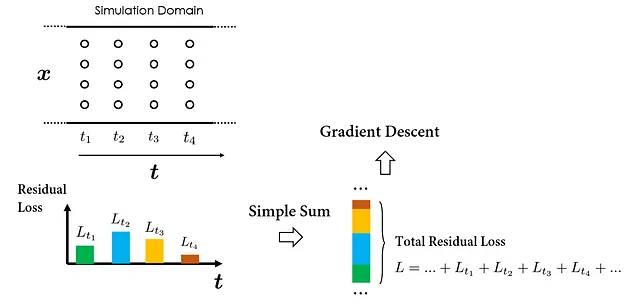
为执行一步梯度下降,我们必须首先计算所有插值点上的累积PDE残差损失。其中一种具体的方法是首先计算与各个时间点处的插值点相关的损失,然后执行“简单求和”以获得总损失。接下来的梯度下降步骤可以基于计算的总损失来进行,以优化PINN权重。
当然,对插值点的求和顺序并不影响总损失计算;所有方法都产生相同的结果。但是,按时间顺序分组损失计算的决定是有目的的,旨在强调“时间性”要素。这个概念对于理解所提出的因果训练策略至关重要。
在此过程中,将在不同时间位置评估的PDE残差损失等同地处理。这意味着所有时间残差损失都将同时被最小化。
然而,这种方法存在着违反时间因果性的风险,因为它不强制实施基于时间顺序的正则化,以最小化相继时间间隔的时间残差损失。
那么,在训练中如何让PINN遵循时间先决原则呢?
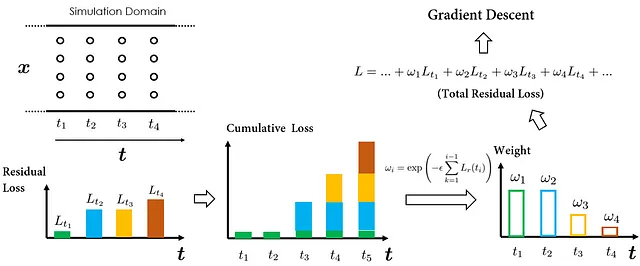
秘诀在于有选择地加权单个时间残差损失。例如,假设在当前迭代中,我们希望PINN集中于近似时间点t₁的解。那么,我们可以简单地在Lᵣ(t₁)上放置更高的权重,即t₁处的时间残差损失。这样,Lᵣ(t₁)将成为最终总损失的主要组成部分,因此,优化算法将优先考虑最小化Lᵣ(t₁),这符合我们首先近似时间点t₁的解的目标。

在后续迭代中,我们将重点转向时间点t₂处的解。通过增加Lᵣ(t₂)的权重,它现在成为总损失计算中的主要因素。因此,优化算法被定向于最小化Lᵣ(t₂),从而提高了解t₂的预测准确性。

如前述步骤所示,变化分配给不同时间点的时间残差损失的权重使我们能够引导PINN近似我们选择的时间点处的解。
那么,这如何帮助将因果结构纳入PINN训练中呢?事实证明,我们可以设计一种因果训练算法(如论文所建议的),使得仅当t之前的损失(Lᵣ(t-1),Lᵣ(t-2)等)足够小时,时间t处的时间残差损失的权重才显著。这实际上意味着神经网络仅在实现先前步骤的令人满意的近似精度时才开始最小化Lᵣ(t)。
为了确定权重,该论文提出了一个简单的公式:将权重ωᵢ设置为与之前所有时间实例的累积时间残差损失的幅度成反指数比例。这确保了权重ωᵢ只有在所有先前时间实例的累积损失很小,即PINN已经能够准确逼近先前时间步长的解时才会处于活动状态(即具有足够大的值)。这就是PINN训练中反映时间因果关系的方式。
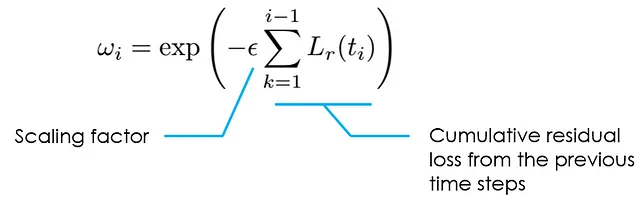
通过解释所有组件,我们可以将完整的因果训练算法组合如下:
在我们结束这一部分之前,有两点值得一提:
- 该论文建议使用ωᵢ的幅度作为PINN训练的停止标准。具体而言,当所有ωᵢ都大于预定义的阈值δ时,可以认为训练已经完成。 δ的推荐值为0.99。
- 选择适当的ε值很重要。尽管这个值可以通过常规超参数调整来调整,但该论文推荐了一种退火策略来调整ε值。详情请参见原始论文(第3节)。
2.3 该解决方案为什么可能有效 🛠️
通过动态加权评估不同时间实例的时间残差损失,所提出的算法能够引导PINN训练,先在较早的时间逼近PDE解,然后再尝试解决后续时间的解。
这种属性促进了时间因果关系的显式融入PINN训练,并构成了潜在更准确地模拟物理系统的关键因素。
2.4 基准 ⏱️
该论文考虑了共3个不同的基准方程。所有问题都是正向问题,其中使用PINN来解决PDE。
- Lorenz系统:这些方程式出现在行星大气对流的研究中。 Lorenz系统对其初始条件非常敏感,众所周知,对于香草PINN而言是具有挑战性的。

- Kuramoto-Sivashinsky方程:该方程描述了各种波状模式的动态,例如火焰,化学反应和表面波。众所周知,它展示了丰富的时空混沌行为。

- Navier-Stokes方程:这组偏微分方程描述了流体物质的运动,并构成流体力学中的基本方程。本文考虑的是一个经典的二维退化湍流示例,在具有周期性边界条件的正方形域中。

基准研究结果表明:
- 所提出的因果训练算法能够实现比香草PINN训练方案10-100倍的精度提高。
- 证明了配备因果训练算法的PINNs可以成功模拟高度非线性,多尺度和混沌的系统。
2.5 优点和缺点 ⚡
优点 💪
- 尊重因果关系原则,使PINN训练更加透明。
- 引入了显着的精度改进,使其能够应对一直难以应对的问题。
- 提供了一个实际的定量标准,用于评估PINN的训练收敛性。
- 与香草PINN训练策略相比,增加的计算成本可以忽略不计。唯一增加的成本是计算ωᵢ,与自动差分操作相比可以忽略不计。
缺点 📉
- 引入了一个新的超参数ε,用于控制时间残差损失的权重调度。尽管作者提出了一种退火策略作为替代方案,以避免繁琐的超参数调整。
- 复杂化了PINN训练流程。需要特别注意时间权重ωᵢ,因为它们现在是网络可训练参数(如层权重和偏置)的函数,计算ωᵢ的梯度不应被反向传播。
2.6 替代方法 🔀
有几种替代方法试图解决与当前“因果训练算法”相同的问题:
- 自适应时间采样策略(Wight等人):该策略修改了碰撞点的采样密度,而不是在不同时间实例加权碰撞点。这具有类似的效果,将优化器的重点从不同时间实例的最小化时间损失移动。
- “时间推进”/“课程训练”策略(例如Krishnapriyan等人):通过在单独的时间窗口中顺序学习解决方案,尊重时间因果性。
然而,与这些替代方法相比,“因果训练算法”将时间因果性置于中心位置,更适应各种问题,并享有较低的额外计算成本。
3 潜在未来改进 🌟
有几种可能进一步改进所提出的策略的可能性:
- 结合更复杂的数据采样策略,例如自适应和残差基于采样方法,以进一步提高训练效率和准确性。
要了解如何优化残差点分布,请查看此博客中的PINN设计模式系列。
- 扩展到反问题设置。如何确保在有信息的点源(即观测数据)可用时出现因果关系,需要扩展当前提出的训练策略。
4 总结 📝
在本博客中,我们看到如何通过重新定义训练目标来使PINN训练遵循物理系统的因果原则。以下是论文中提出的设计模式的亮点:
- [问题]:如何使PINNs遵循物理系统的因果原则?
- [解决方案]:重新定义PINN训练目标,引入动态加权方案,逐渐将训练重点从早期时间步骤转移到后期时间步骤。
- [潜在优点]:1.显著提高PINNs的准确性。2.扩展了PINNs对复杂问题的适用性。
以下是PINN设计卡片,以总结要点:

希望您会发现这篇博客有用!要了解有关PINN设计模式的更多信息,请随时查看以前的帖子:
- PINN设计模式01:优化残差点分布
- PINN设计模式02:动态解决方案间隔扩展
- PINN设计模式03:使用梯度提升的PINN训练
- PINN设计模式04:梯度增强的PINN学习
- PINN设计模式05:用于PINN的超参数调整
期待在未来的博客中与您分享更多见解!
参考文献 📑
[1]王等人,尊重因果关系是训练物理学知识神经网络所需要的全部,arXiv,2022年。





