相似性搜索,第三部分:融合倒排文件索引和产品量化
探索如何将两种基本相似性搜索索引结合起来,以获得双方的优势
相似性搜索是一个问题,其中给定查询,目标是在所有数据库文档中找到与之最相似的文档。
介绍
在数据科学中,相似性搜索经常出现在NLP领域、搜索引擎或推荐系统中,其中需要检索与查询最相关的文档或项目。存在许多不同的方式来提高大量数据的搜索性能。
在本系列的前两部分中,我们讨论了信息检索中的两个基本算法:倒排文件索引和产品量化。它们都优化了搜索性能,但着重于不同的方面:第一个加速搜索速度,而后者将向量压缩为更小、更节省内存的表示形式。
相似性搜索,第1部分:kNN和倒排文件索引
相似性搜索是一个普遍的问题,其中给定查询Q,我们需要在所有文档中找到与之最相似的文档…
towardsdatascience.com
相似性搜索,第2部分:产品量化
在本文系列的第一部分中,我们讨论了用于执行相似性的kNN和倒排文件索引结构…
小猪AI.com
由于两种算法都着重于不同的方面,自然而然会出现一个问题,即是否可能将这两种算法合并为一种新的算法
在本文中,我们将结合两种方法的优点,产生一种快速而节省内存的算法。值得一提的是,大多数讨论的想法都基于这篇论文。
在深入细节之前,有必要了解什么是残差向量,并对它们的有用属性有一个简单的直观认识。在设计算法时,我们将在后面使用它们。
残差向量
想象一下,执行了一个聚类算法,它产生了几个聚类。每个聚类都有一个质心和与之关联的点。残差是一个点(向量)从其质心的偏移量。基本上,要为特定的向量找到残差,必须从其质心中减去向量。
如果聚类是由k-means算法构建的,那么聚类质心是属于该聚类的所有点的平均值。因此,从任何点找到残差都相当于从聚类的平均值中减去它。通过从属于特定聚类的所有点中减去平均值,这些点将围绕0居中。

我们可以观察到一个有用的事实:
用残差替换原始向量不会改变它们相对位置。
也就是说,向量之间的距离始终保持不变。让我们简单地看一下下面的两个方程。
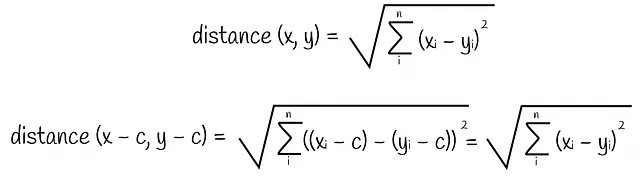
第一个方程式是一对向量之间欧几里得距离的公式。在第二个方程式中,簇均值从两个向量中减去。我们可以看到,均值项简单地被消除了——整个表达式变成了第一个方程式中的欧几里得距离!
我们使用L2度量(欧几里得距离)的公式证明了这个说法。重要的是要记住,这个规则可能对其他度量不适用。
因此,如果对于给定的查询,目标是找到最近的邻居,则可以将簇均值从查询中减去,并继续在残差中进行正常的搜索过程。
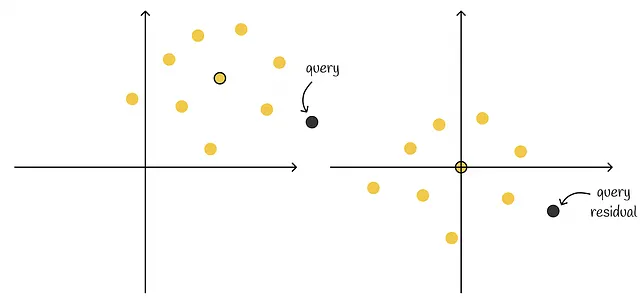
现在,让我们看下面的另一个示例,其中有两个簇,在每个簇的向量的残差分别计算。
从每个簇的相应质心的平均值中减去每个向量,会使所有数据集向量以0为中心。
这是一个有用的观察结果,将在未来使用。此外,对于给定的查询,我们可以计算查询残差到所有簇的残差。查询残差允许我们计算到簇的原始残差的距离。

训练
在考虑了前一节中的有用观察后,我们可以开始设计算法。
给定一个向量数据库,构建一个反转文件索引,将向量集合分成n个沃罗诺伊分区,从而在推理过程中减小搜索范围。
在每个沃罗诺伊分区内,从每个向量中减去质心的坐标。结果,所有分区的向量都变得更接近彼此并以0为中心。此时,不需要原始向量,因为我们存储它们的残差。
之后,在来自所有分区的向量上运行产品量化算法。
重要的方面:不是每个分区分别执行产品量化——这将是低效的,因为分区的数量通常往往很高,这将导致需要大量的内存来存储所有码本。相反,算法是同时在所有分区的所有残差上执行的。
有效地,现在每个子空间都包含来自不同沃罗诺伊分区的子向量。然后,对于每个子空间,执行聚类算法,并构建k个带有它们的质心的聚类,与通常的方法一样。
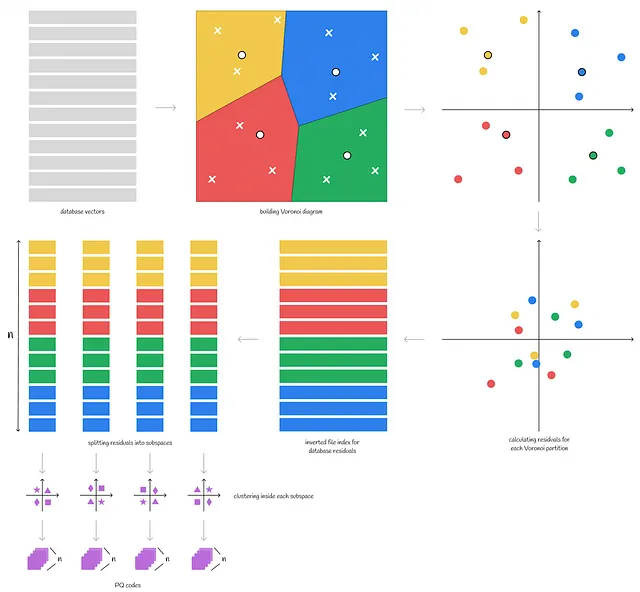
替换向量为它们的残差的重要性是什么?如果没有用残差替换向量,则每个子空间将包含更多各种子向量(因为子空间将存储来自不同不相交的沃罗诺伊分区的子向量,这些向量在空间中可能相距很远)。现在来自不同分区的向量(残差)彼此重叠。由于现在每个子空间的变化较小,因此需要较少的繁殖值来有效地表示向量。换句话说:
使用先前使用的相同长度的PQ代码,可以更准确地表示向量,因为它们的方差更小。
推理
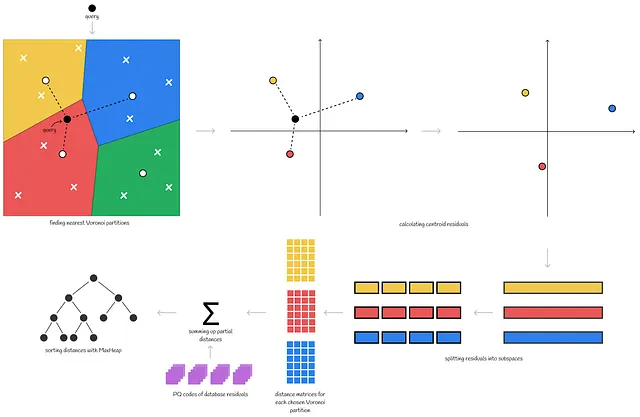
对于给定的查询,找到沃罗诺伊分区的k个最近质心。在这些区域内的所有点都被视为候选点。由于最初在每个沃罗诺伊区域中用其残差替换了原始向量,因此还需要计算查询向量的残差。在这种情况下,需要为每个沃罗诺伊分区分别计算查询残差(因为每个区域都有不同的质心)。只有从选择的沃罗诺伊分区的残差才会成为候选者。
然后将查询残差拆分为子向量。与原始的产品量化算法一样,对于每个子空间,计算包含从子空间质心到查询子向量的距离的距离矩阵d。必须牢记的是,对于每个Voronoi分区,查询残差都是不同的。基本上意味着需要为每个查询残差单独计算距离矩阵d。这是所需优化的计算价格。
最后,部分距离被汇总,就像在产品量化算法中一样。
排序结果
计算所有距离后,需要选择k个最近的邻居。为了高效地执行此操作,作者建议使用MaxHeap数据结构。它具有k的有限容量,在每个步骤中,它存储k个当前最小的距离。每当计算出新的距离时,仅当计算出的值小于MaxHeap中的最大值时,才将其添加到MaxHeap中。计算所有距离后,查询的答案已经存储在MaxHeap中。使用MaxHeap的优点是其快速构建时间,即O(n)。
性能
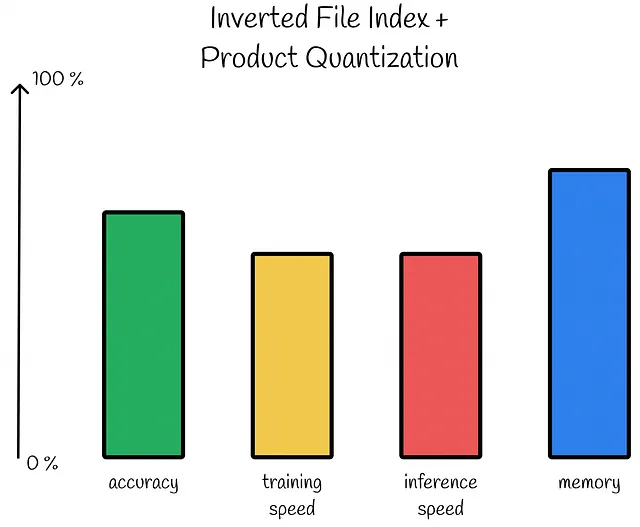
该算法利用了反向文件索引和产品量化的优势。根据推理期间探测的Voronoi分区的数量,需要计算并存储内存中的相同数量的子向量到质心矩阵d。这可能看起来像是一个缺点,但与总体优势相比,这是一个相当不错的折衷。
Faiss实现
Faiss(Facebook AI搜索相似性)是一种用于优化相似性搜索的用C++编写的Python库。此库提供了不同类型的索引,这些索引是用于有效地存储数据和执行查询的数据结构。
根据Faiss文档中的信息,我们将看到如何将反向文件和产品量化索引组合在一起形成一个新的索引。
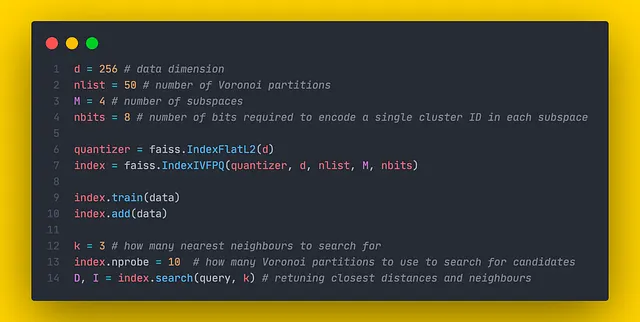
Faiss在IndexIVFPQ类中实现了所述的算法,该类接受以下参数:
- quantizer :指定如何计算向量之间的距离。
- d :数据维度。
- nlist :Voronoi分区的数量。
- M :子空间的数量。
- nbits :编码单个簇ID所需的位数。这意味着单个子空间中的总簇数将等于k = 2 ^ nbits。
此外,可以调整nprobe属性,该属性指定在推理期间使用多少Voronoi分区来搜索候选项。更改此参数不需要重新训练。
存储单个向量所需的内存与原始产品量化方法相同,只是现在需要添加8个字节以在反向文件索引中存储有关向量的信息。
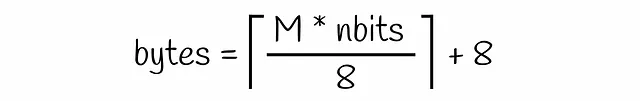
结论
使用先前文章部分的知识,我们已经实现了一种最先进的算法,该算法实现了高内存压缩和加速搜索速度。在处理大量数据时,这种算法在信息检索系统中被广泛使用。
资源
- 最近搜索的产品量化
- Faiss文档
- Faiss存储库
- Faiss索引摘要
除非另有说明,所有图片均由作者提供。