使用SQuID评估多语言语音合成
由Google研究科学家Thibault Sellam发布
我们曾经提出了1000种语言计划和通用语音模型,旨在为全球数十亿用户提供语音和语言技术。其中一部分承诺是开发高质量的语音合成技术,这些技术建立在VDTTS和AudioLM等项目之上,面向使用许多不同语言的用户。
 |
在开发新模型后,必须评估其生成的语音是否准确和自然:内容必须与任务相关,发音正确,语气适当,且不应有裂缝或信号相关噪音等声学伪像。这样的评估是开发多语言语音系统的主要瓶颈之一。
评估语音合成模型质量的最流行方法是人工评估:文本到语音(TTS)工程师从最新模型中产生数千个话语,将它们发送进行人工评估,并在几天后接收结果。这个评估阶段通常涉及听力测试,期间几十个注释器依次听取话语以确定它们听起来有多自然。虽然人类仍然无法击败是否自然地发音的声音,但这个过程可能不切实际,特别是在研究项目的早期阶段,当工程师需要快速反馈以测试和重新制定他们的方法时。人工评估是昂贵的、耗时的,并且可能受到感兴趣语言的评分者可用性的限制。
进展的另一个障碍是,不同的项目和机构通常使用各种评分、平台和协议,这使得苹果和苹果之间的比较成为不可能。在这方面,语音合成技术落后于文本生成,研究人员长期以来一直将人工评估与自动度量(例如BLEU或最近的BLEURT)相结合。
在即将于2023年在ICASSP上展示的“ SQuId: Measuring Speech Naturalness in Many Languages ”一文中,我们介绍了SQuId(Speech Quality Identification),这是一个600M参数回归模型,描述了一段语音听起来有多自然。 SQuId基于Google开发的预训练语音文本模型mSLAM,通过对42种语言中的100多万个质量评分进行微调并在65种语言中进行测试。我们展示了如何使用SQuId来补充人类评分,以评估许多语言。这是迄今为止最大的此类发布性努力。
使用SQuId评估TTS
SQuId背后的主要假设是,在先前收集的评分上训练回归模型可以为我们提供一种低成本的方法,用于评估TTS模型的质量。因此,该模型可以成为TTS研究人员评估工具箱中有价值的补充,提供一种近乎即时的、虽然不如人工评估准确的替代方法。
SQuId将话语作为输入,以及一个可选的区域标记(即语言的本地化变体,例如“巴西葡萄牙语”或“英式英语”)。它返回一个介于1和5之间的分数,指示波形听起来有多自然,分数越高,波形越自然。
在内部,该模型包括三个组件:(1)编码器,(2)汇聚/回归层和(3)全连接层。首先,编码器接受频谱图作为输入,并将其嵌入到一个较小的2D矩阵中,该矩阵包含大小为1,024的3,200个向量,其中每个向量编码一个时间步。汇聚/回归层聚合向量,附加区域标记,将结果馈送到全连接层,该层返回一个分数。最后,我们应用应用程序特定的后处理,使得分数重新调整或规范化,使其在[1,5]范围内,这是常见的自然度人工评分。我们使用回归损失对整个模型进行端到端的培训。
编码器是该模型最大且最重要的部分。我们使用了mSLAM,一个现有的600M参数Conformer,它在语音(51种语言)和文本(101种语言)方面都进行了预训练。
 |
| SQuId模型。 |
为了训练和评估该模型,我们创建了SQuId语料库:这是一个跨越66种语言的、包含190万个评分话语的集合,用于超过2000个研究和产品TTS项目。SQuId语料库涵盖了各种各样的系统,包括串联和神经模型,适用于广泛的用例,如驾驶方向和虚拟助手。手动检查显示,SQuId暴露于各种各样的TTS错误,例如声学伪影(例如裂缝和爆声)、不正确的韵律(例如英语中没有升调的问题)以及文本规范化错误(例如将“7/7”发音为“seven divided by seven”而不是“July seventh”)或发音错误(例如将“tough”发音为“toe”)。
当训练多语言系统时,常见的问题是训练数据可能不会对所有感兴趣的语言均匀可用。SQuId也不例外。以下图显示了每个地区的语料库大小。我们可以看到,分布基本上被美式英语所占据。
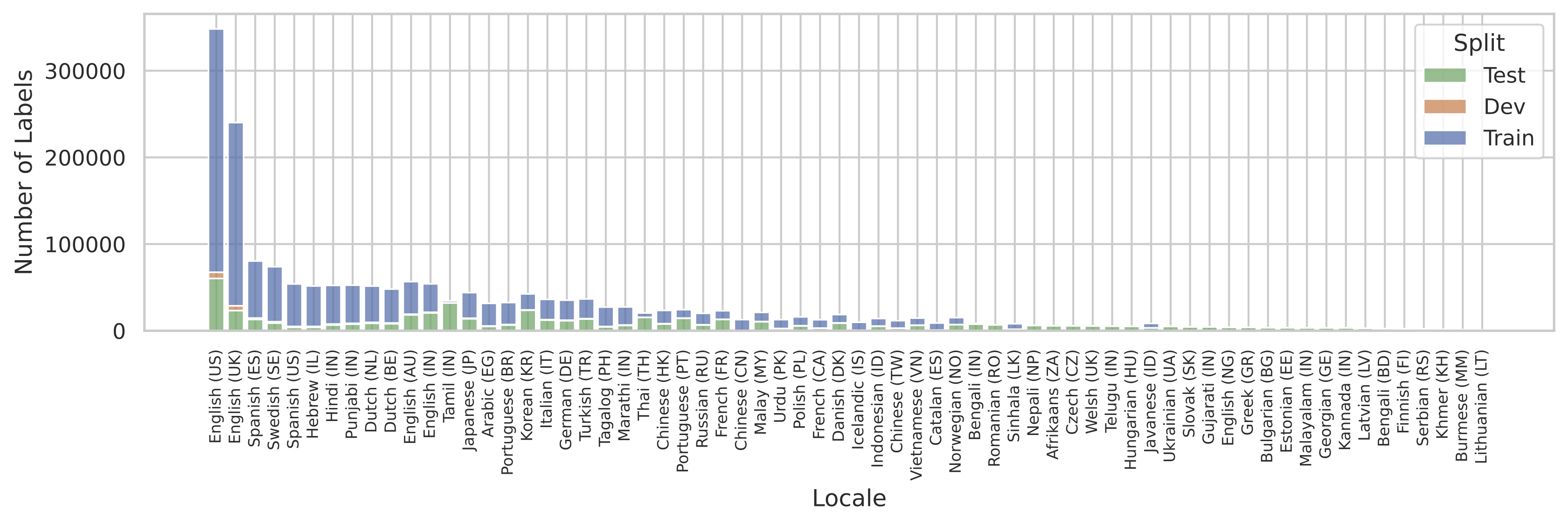 |
| SQuId数据集中的地区分布。 |
当存在这样的变化时,我们如何为所有语言提供良好的性能?受先前机器翻译工作以及来自语音文献的过去工作的启发,我们决定为所有语言训练一个模型,而不是为每种语言使用单独的模型。假设是,如果模型足够大,则可以进行跨地区转移:模型在每个地区的准确性会随着在其他地区进行联合训练而得到改善。正如我们的实验所显示的,跨地区证明是性能的强大驱动器。
实验结果
为了了解SQuId的整体表现,我们将其与自定义的Big-SSL-MOS模型(在论文中描述)进行比较,后者是受MOS-SSL启发的竞争基线,是最先进的TTS评估系统。 Big-SSL-MOS基于w2v-BERT,是在VoiceMOS’22 Challenge数据集上进行训练的,这是评估时最流行的数据集。我们尝试了几种模型变体,并发现SQuId的准确性高达50.0%。
 |
| SQuId与最先进的基线对比。我们使用Kendall Tau进行人类评分的一致性度量,值越高表示准确性越好。 |
为了了解跨语言转移的影响,我们进行了一系列的消融研究。我们改变了训练集中引入的语言数量,并测量了对SQuId准确性的影响。在英语中,由于数据集已经过度表示,添加语言的效果可以忽略不计。
 |
| SQuId在美式英语上的表现,在微调过程中使用1、8和42个语言。 |
然而,对于大多数其他语言,跨语言转移效果更为显著:
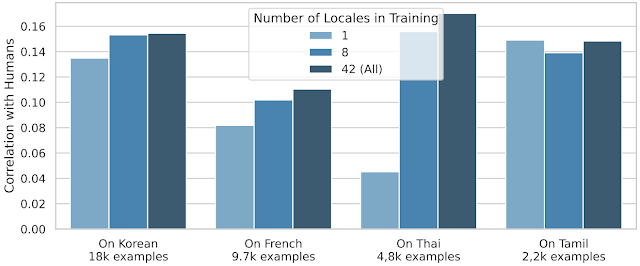 |
| SQuId在四种选定语言(韩语、法语、泰语和泰米尔语)上的表现,在微调过程中使用1、8和42个语言。对于每种语言,我们还提供训练集大小。 |
为了将转移推向极限,我们在训练过程中保留了24个语言,并将其专门用于测试。因此,我们测量SQuId能够处理它从未见过的语言的程度。下面的图表显示,尽管效果不均匀,跨语言转移是有效的。
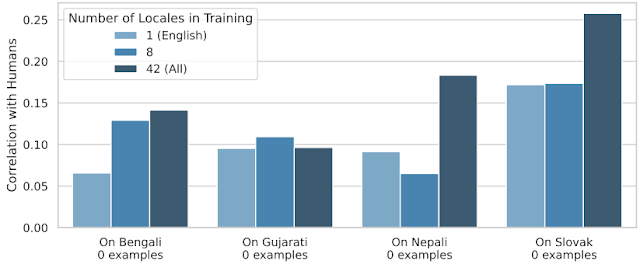 |
| SQuId在四种“零-shot”语言上的表现;在微调过程中使用1、8和42个语言。 |
跨语言操作何时进行,以及如何进行?我们在论文中提出了更多的消融研究,并表明虽然语言相似性起到一定作用(例如,训练巴西葡萄牙语有助于欧洲葡萄牙语),但它令人惊讶地远非唯一要考虑的因素。
结论和未来工作
我们介绍了SQuId,一个利用SQuId数据集和跨语言学习评估语音质量以及描述其自然程度的6亿参数回归模型。我们证明SQuId可以补充人类评审员在许多语言的评估中。未来的工作包括提高准确性,扩大涵盖的语言范围以及解决新的错误类型。
致谢
本篇文章的作者现已成为Google DeepMind的一员。感谢论文的所有作者:Ankur Bapna、Joshua Camp、Diana Mackinnon、Ankur P. Parikh和Jason Riesa。