如何像老板一样进行MLOps:无痛机器学习指南
如果你曾经将 .pickle 文件通过邮件发送给工程师进行部署,那么这个信息适用于你!

预计到2025年,由于迅速的普及,MLOps市场在2019年估计为232亿美元,将达到1260亿美元。
介绍
许多数据科学项目都没能实现。MLOps是一个从数据阶段到部署阶段的过程,确保机器学习模型的成功。在本文中,您将学习关于MLOps的关键阶段(从数据科学家的角度)以及一些常见陷阱。
- Google AI 推出了一种新的安全 AI 框架(SAIF):确保 AI 系统安全的概念框架
- 认识Video-LLaMA:一种多模式框架,赋予大型语言模型(LLMs)理解视频中视觉和听觉内容的能力
- 这篇AI论文提出了一种有效的解决常见实际多边际最优传输问题的解决方案
MLOps的动机
MLOps是一种专注于操作化数据科学模型的实践。通常,在大多数企业中,数据科学家负责创建建模数据集,预处理数据,进行特征工程,最后构建模型。然后,将模型“丢”给工程团队以部署到API / Endpoint。科学和工程通常是在孤立的环境中进行的,这导致了部署延迟或在最坏的情况下进行了错误的部署。
MLOps解决了准确快速部署企业级ML模型的挑战。
数据科学中“说起来容易做起来难”这句话的等价物可能是“建起来比部署难”。
MLOps可以是企业面临的将机器学习模型投入生产的困难的解决方案。对于我们数据科学家中的大多数人来说,发现约90%的ML模型无法实现生产应该不会感到惊讶。 MLOps为数据科学和工程团队带来纪律和流程,以确保他们紧密而持续地协作。这种协作对于确保成功的模型部署至关重要。
概述MLOps
对于熟悉DevOps的人来说,MLOps就像DevOps对于软件应用程序一样。
根据您问的人,MLOps有多种不同的味道。然而,有五个关键阶段对于成功的MLOps策略至关重要。顺便说一句,每个阶段都需要与利益相关者进行沟通。
问题框架
全面了解业务问题。这是成功模型部署和使用的关键步骤之一。在此阶段与所有利益相关者接触以获得项目购买。可以是工程,产品,合规等。
解决方案框架
只有在解决方案说明得到解决之后,才能考虑“如何”。需要机器学习来解决这个业务问题吗?一开始,作为数据科学家,我建议避开机器学习可能会感到奇怪。那是因为“伟大的力量伴随着伟大的责任”。在这种情况下,责任是确保机器学习模型被认真构建,部署和监测,以确保满足并继续满足业务要求。也应该与利益相关者在此阶段讨论时间表和资源。
数据准备
一旦您决定走机器学习的路线,请开始考虑“数据”。此阶段包括数据收集,数据清理,数据转换,特征工程和标记(用于监督学习)。在这里需要记住的格言是“垃圾进垃圾出”。这一步通常是该过程中最费力的一步,并且对于确保模型成功至关重要。确保多次验证数据和特征以确保它们与业务问题对齐。记录您创建数据集时的所有假设。例如:特征的异常值是否真的是异常值?
模型构建和分析
在此阶段,构建和评估多个模型,并选择最适合解决手头问题的模型架构。优化的选择度量应反映业务要求。今天,有许多机器学习库可以帮助加快此步骤。记住记录并跟踪实验以确保机器学习管道的可重复性。
模型服务和监测
一旦我们从上一阶段构建了模型对象,我们需要考虑如何使其对最终用户“可用”。响应延迟需要最小化,同时最大化吞吐量。一些流行的模型服务选项包括 – REST API 端点,作为云上的 Docker 容器或边缘设备上的模型。一旦我们部署了模型对象,我们不能立即庆祝,因为它们在性质上非常动态。例如,数据可能会在生产环境中漂移,导致模型衰减,或者可能对模型进行对抗性攻击。我们需要为机器学习应用程序建立强大的监控基础架构。这里需要监控两个方面:
- 部署环境的健康状况(例如:负载、使用情况、延迟)
- 模型本身的健康状况(例如:性能指标、输出分布)。
在此阶段还需要确定监控过程的频率。您是否每天、每周或每月监控机器学习应用程序?
现在,您已经构建、部署和监控了一个强大的机器学习应用程序。但是,这个过程并不会停止,因为以上步骤需要不断迭代。 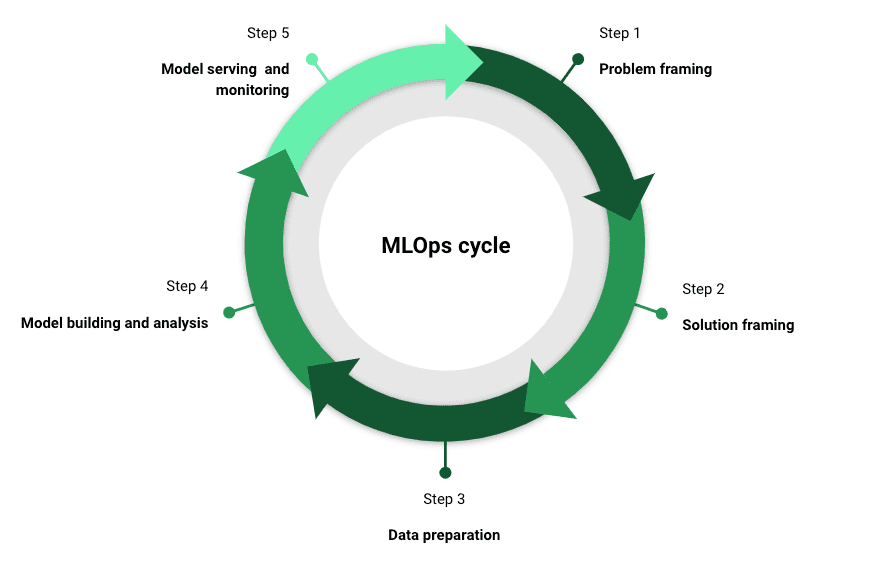
金融科技案例研究
为了实践上述五个阶段,假设在本节中您是一家金融科技公司的数据科学家,负责部署欺诈模型以检测欺诈交易。
在这种情况下,首先深入研究您要检测的欺诈类型(第一方或第三方?)。交易如何被识别为欺诈或非欺诈?它们是由最终用户报告的,还是您必须使用启发式方法来识别欺诈?谁将使用该模型?它将实时使用还是批处理模式?以上问题的答案对于解决此业务问题至关重要。
接下来,考虑哪种解决方案最能解决此问题。您是否需要使用机器学习来解决此问题,还是可以从简单的启发式方法入手来解决欺诈问题?所有的欺诈行为是否都来自一小部分 IP 地址?
如果您决定构建机器学习模型(假设为监督学习),则需要标签和特征。您将如何处理缺失的变量?离群值怎么办?欺诈标签的观察窗口是多长时间?即用户报告欺诈交易需要多长时间?是否有数据仓库可用于构建特征?确保在继续之前验证数据和特征。这也是与利益相关者讨论项目方向的好时机。
一旦您拥有所需的数据,就可以构建模型并执行必要的分析。确保模型指标与业务使用方式相一致(例如:在此用例中可能是第一十分位数的召回率)。所选的模型算法是否满足延迟要求?
最后,与工程师协调部署和服务模型。因为欺诈检测是一个非常动态的环境,欺诈者努力保持领先地位,因此监控非常关键。针对数据和模型都需要有监控计划。常见的措施,例如 PSI(人口稳定性指数),可用于跟踪数据漂移。您将以多频率重新训练模型?
现在,您可以成功地利用机器学习创建业务价值,以减少欺诈交易(如果需要!)。
结论
希望阅读本文后,您能看到在您的公司实施 MLOps 的好处。总之,MLOps 确保数据科学团队:
- 解决正确的业务问题
- 使用正确的工具解决问题
- 利用代表问题的数据集
- 构建最优的机器学习模型
- 最后部署和监控模型以确保持续的成功
但是,要注意常见的陷阱,以确保您的数据科学项目不会成为数据科学墓地中的墓碑!应该记住数据科学应用程序是一个活生生的事物。需要持续监控数据和模型。人工智能治理应该从一开始就考虑,而不是事后再考虑。
有了这些原则,我相信您可以真正利用机器学习创造业务价值(如果需要!)。
MLOps 参考资料
- 面向生产的机器学习工程(MLOps)
- MLOps 简介
- 数据科学家的 MLOps 实践
- MLOps:即将崛起的明星
Natesh Babu Arunachalam 是万事达卡的数据科学领袖,目前专注于利用开放银行数据构建创新的人工智能应用。






