可控制的医学图像生成与控制网络
使用 ControlNets 控制隐式扩散模型生成过程的指南
本文将介绍一个使用ControlNet训练指南,以赋予用户对隐式扩散模型(如稳定扩散!)生成过程的精确控制。我们旨在展示这些模型在将脑影像翻译成不同对比度方面的显着能力。为此,我们将利用最近推出的 MONAI 生成模型的开源扩展的强大功能!

我们的项目代码可以在此公共代码库中找到:https://github.com/Warvito/generative_brain_controlnet
介绍
近年来,文本到图像扩散模型取得了显着进展,能够基于开放域文本描述生成高度逼真的图像。这些生成的图像具有丰富的细节、清晰的轮廓、连贯的结构和有意义的上下文表示。然而,尽管扩散模型取得了显着成就,但仍然存在一个挑战,即在生成过程中实现精确控制。即使是通过冗长而复杂的文本描述,准确地捕捉用户所需的想法也可能是一项艰巨的任务。
ControlNets 的引入,正如 Lvmin Zhang 和 Maneesh Agrawala 在他们的开创性论文“在文本到图像扩散模型中添加条件控制”(2023)中所提出的那样,显着增强了扩散模型的可控性和个性化。这些神经网络充当轻量级适配器,使得精确控制和个性化定制成为可能,同时保留了扩散模型的原始生成能力。通过微调这些适配器,同时保持原始扩散模型冻结,文本到图像模型可以高效地增强各种图像到图像应用程序的多样性。
ControlNet 的独特之处在于其解决了空间一致性的挑战。与以往的方法不同,ControlNet 允许显式控制生成结构的空间、结构和几何方面,同时保留从文本标题中派生的语义控制。原始研究介绍了各种模型,使得基于边缘、姿态、语义掩模和深度图的有条件生成成为可能,为计算机视觉领域的令人兴奋的进展铺平了道路。
在医学成像领域,许多图像到图像应用程序具有重要意义。其中一个值得注意的任务涉及在不同域之间转换图像,例如将计算机断层扫描(CT)转换为磁共振成像(MRI),或者在不同对比度之间转换图像,例如从 T1 加权到 T2 加权 MRI 图像。在本文中,我们将重点关注一个特定案例:使用从 FLAIR 图像获得的脑部图像的 2D 切片来生成相应的 T1 加权图像。我们的目标是演示我们的 MONAI 扩展(MONAI 生成模型)和 ControlNets 如何有效地用于训练和评估医学数据上的生成模型。通过深入研究这个例子,我们的目的是为医学成像领域中这些技术的实际应用提供见解。
隐式扩散模型训练
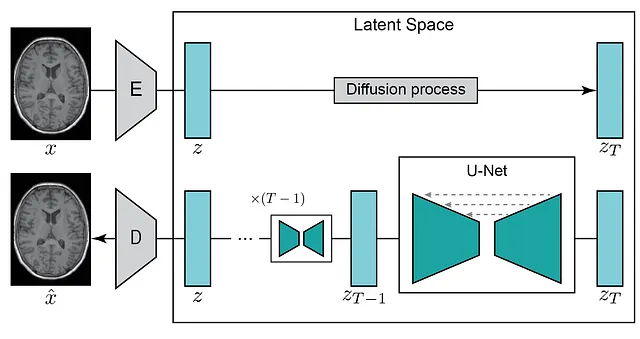
要从 FLAIR 图像生成 T1 加权(T1w)图像,最初的步骤是训练一种能够生成 T1 加权图像的扩散模型。在我们的例子中,我们利用从 UK Biobank 数据集中获取的脑 MRI 图像提取的 2D 切片(可在此数据协议下获取)。在将原始 3D 脑部图像注册到 MNI 空间之后,我们从中央脑部提取五个 2D 切片。我们选择此区域是因为它展示了各种组织,使得我们进行的图像翻译更容易评估。使用此脚本,我们得到了约190,000 个切片,其空间尺寸为224 × 160 像素。接下来,我们使用此脚本将图像分为训练(约 180,000 个切片)、验证(约 5,000 个切片)和测试(约 5,000 个切片)集。准备好我们的数据集后,我们可以开始训练我们的隐式扩散模型!
为了优化计算资源,潜在扩散模型采用编码器将输入图像x转换为较低维度的潜在空间z,然后可以通过解码器进行重构。这种方法使得即使计算能力有限,也能够训练扩散模型,同时仍然保持原始质量和灵活性。和我们在之前的帖子(使用MONAI生成医学图像)中所做的类似,我们使用MONAI生成模型中的KL正则化自编码器模型来创建我们的压缩模型。通过使用这个配置和L1损失以及KL正则化,感知损失和对抗性损失,我们创建了一个能够对大脑图像进行高保真编码和解码的自编码器(使用此脚本)。自编码器的重构质量对于潜在扩散模型的性能至关重要,因为它定义了我们生成的图像质量的上限。如果自编码器的解码器产生模糊或低质量的图像,我们的生成模型将无法生成更高质量的图像。
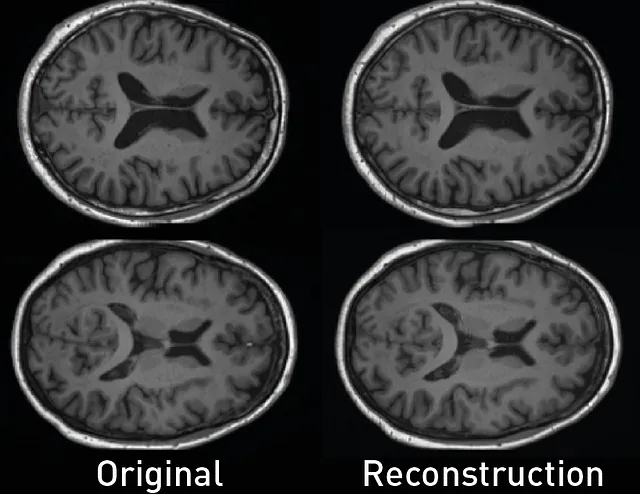
使用这个脚本,我们可以使用多尺度结构相似性指数测量(MS-SSIM)来量化自编码器的保真度和原始图像及其重构之间的相似性。在这个例子中,我们获得了一个MS-SSIM度量值等于0.9876的高性能。
在训练自编码器后,我们将在潜在空间z上训练扩散模型。扩散模型是一种能够通过迭代地在一系列时间步骤上对其进行去噪的纯噪声图像生成图像的模型。通常使用U-Net架构(具有编码器-解码器格式),其中我们有编码器的层通过长跳跃连接与解码器部分的层相连,实现特征重用并稳定训练和收敛。
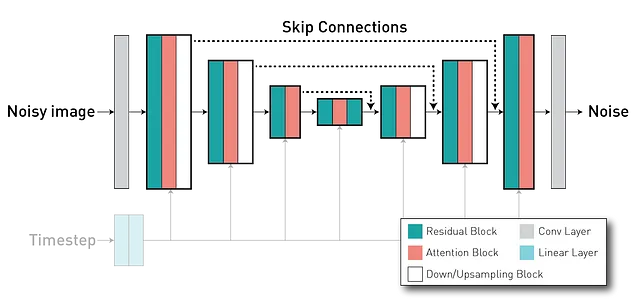
在训练期间,潜在扩散模型学习给出这些提示的条件性噪声预测。同样地,我们使用MONAI来创建和训练这个网络。在这个脚本中,我们使用这个配置来实例化模型,在这部分代码中进行训练和评估。由于在本教程中我们对文本提示不太感兴趣,所以我们对所有图像使用相同的文本提示(一句话说“一张大脑的T1加权图像”)。
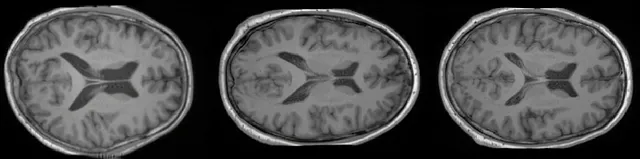
同样地,我们可以量化我们训练的生成模型的性能,这次我们评估样本的质量(使用Fréchet inception距离(FID))和模型的多样性(计算一组1,000个样本的所有成对样本之间的MS-SSIM)。使用这些脚本(1和2),我们获得了FID = 2.1986和MS-SSIM Diversity = 0.5368。
正如您在前面的图像和结果中所看到的,我们现在有了一个可以生成高分辨率图像的模型,其质量非常好。但是,我们没有任何关于图像外观的空间控制。为此,我们将使用ControlNet来指导我们的潜在扩散模型的生成。
ControlNet训练
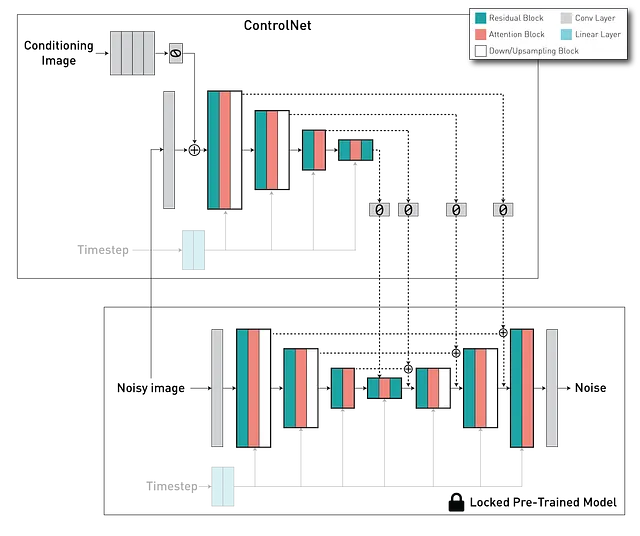
ControlNet架构由两个主要组件组成:U-Net模型的一个可训练版本,包括中间块,和一个预训练的“锁定”版本的扩散模型。在这里,锁定的副本保留了生成能力,而可训练的副本是针对特定的图像到图像数据集进行训练,以学习条件控制。这两个组件使用一个“零卷积”层相互连接——一个带有初始化权重和偏差的1×1卷积层,设置为零。卷积权重逐渐从零过渡到优化参数,确保在初始训练步骤中,可训练和锁定副本的输出保持一致,如果ControlNet不存在,输出与之前一致。换句话说,在任何优化之前,当ControlNet应用于某些神经网络块时,它不会引入任何额外的影响或噪声到深度神经特征中。
通过集成这两个组件,ControlNet使我们能够管理扩散模型U-Net中每个级别的行为。
在我们的示例中,我们使用以下等效片段在此脚本中实例化ControlNet。
import torchfrom generative.networks.nets import ControlNet, DiffusionModelUNet# Load pre-trained diffusion modeldiffusion_model = DiffusionModelUNet( spatial_dims=2, in_channels=3, out_channels=3, num_res_blocks=2, num_channels=[256, 512, 768], attention_levels=[False, True, True], with_conditioning=True, cross_attention_dim=1024, num_head_channels=[0, 512, 768],)diffusion_model.load_state_dict(torch.load("diffusion_model.pt"))# Create ControlNetcontrolnet = ControlNet( spatial_dims=2, in_channels=3, num_res_blocks=2, num_channels=[256, 512, 768], attention_levels=[False, True, True], with_conditioning=True, cross_attention_dim=1024, num_head_channels=[0, 512, 768], conditioning_embedding_in_channels=1, conditioning_embedding_num_channels=[64, 128, 128, 256],)# Create trainable copy of the diffusion modelcontrolnet.load_state_dict(diffusion_model.state_dict(), strict=False)# Lock the weighht of the diffusion modelfor p in diffusion_model.parameters(): p.requires_grad = False由于我们使用的是潜在扩散模型,这需要使用ControlNets将基于图像的条件转换为相同的潜在空间以匹配卷积大小。为此,我们使用与完整模型联合训练的卷积网络。在我们的情况下,我们定义了三个下采样级别(类似于自动编码器KL),“conditioning_embedding_num_channels=[64, 128, 128, 256]”。由于我们的条件图像是带有一个通道的FLAIR图像,我们还需要在“conditioning_embedding_in_channels=1”中指定其输入通道数。
在初始化网络之后,我们将其类似于扩散模型进行训练。在以下代码片段(和代码的这一部分)中,我们可以看到,首先将我们的条件FLAIR图像传递给可训练网络,并从其跳过连接中获取输出。然后,在计算预测的噪声时,将这些值输入到扩散模型中。在内部,扩散模型在馈送解码器部分之前将ControlNets的跳过连接与自己的连接相加。
# Training Loop...images = batch["t1w"].to(device)cond = batch["flair"].to(device)...noise = torch.randn_like(latent_representation).to(device)noisy_z = scheduler.add_noise( original_samples=latent_representation, noise=noise, timesteps=timesteps)# Compute trainable partdown_block_res_samples, mid_block_res_sample = controlnet( x=noisy_z, timesteps=timesteps, context=prompt_embeds, controlnet_cond=cond)# Using controlnet outputs to control diffusion model behaviournoise_pred = diffusion_model( x=noisy_z, timesteps=timesteps, context=prompt_embeds, down_block_additional_residuals=down_block_res_samples, mid_block_additional_residual=mid_block_res_sample,)# Then compute diffusion model loss as usual...ControlNet采样和评估
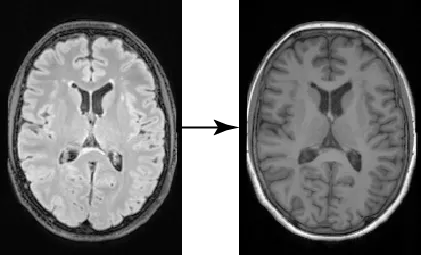
在训练我们的模型之后,我们可以对其进行采样和评估。在这里,我们使用测试集中的FLAIR图像生成条件T1w图像。与我们的训练类似,采样过程与扩散模型使用的过程非常接近,唯一的区别是我们将条件图像传递给训练后的ControlNet,并在每个采样时间步骤中使用其输出来馈送扩散模型。正如我们从下面的图中观察到的那样,我们生成的图像在高空间保真度方面遵循原始条件,大脑皮层回纹遵循相似的形状,并且图像保留了不同组织之间的边界。
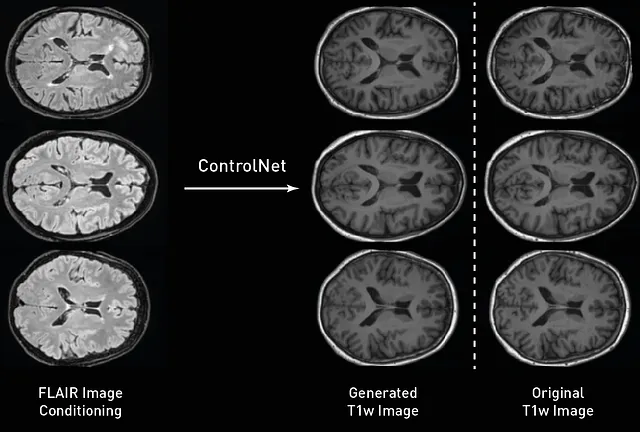
在我们对模型图像进行采样后,我们可以量化我们的ControlNet在不同对比度之间转换图像时的性能。由于我们从测试集中获得了期望的T1w图像,我们还可以检查它们之间的差异,并使用平均绝对误差(MAE)、峰值信噪比(PSNR)和MS-SSIM计算真实和合成图像之间的距离。在我们的测试集中,当执行此脚本时,我们获得了PSNR= 26.2458±1.0092,MAE=0.02632±0.0036和MSSIM=0.9526±0.0111。
这就是它的全部内容!ControlNet为我们的扩散模型提供了令人难以置信的控制能力,最近的方法已经扩展了其方法,将不同训练的ControlNets组合在一起(Multi-ControlNet),在同一模型中使用不同类型的调节(T2I适配器),甚至在样式上调节模型(使用ControlNet 1.1等方法-仅供参考)。如果这些方法听起来有趣,请不要忘记关注我,以获取更多类似的指南!😁
要获取更多有关MONAI生成模型的教程并了解更多功能,请查看我们的教程页面!
注意:除非另有说明,否则所有图像均由作者提供。