使用多任务和集成学习来预测阿尔茨海默病的认知功能
个人故事:从认知科学到数据科学
从认知科学出发,意识到自己在机器学习领域可以产生的影响,并发表了自己的第一篇科学论文
在我之前的一篇文章中,我详细讲述了我从认知科学转向机器学习的经历以及我所遭遇的冒充者综合症。在那篇文章中,我提到:
“我开始慢慢地想到,也许我的背景[在认知科学方面]提供了比我最初预期的更加坚实的基础。”
在本文中,我将分享一个具体的例子,展示了我的认知科学背景使我能够 1)为我在神经科学领域个人意义重大的一种疾病开发创新的建模方法,并 2)建立常规讨论中常被忽视的独特联系。
通过这种经历,我认识到深度学习领域虽然具有潜力,但仍处于形成阶段,这提醒我们注意到它为传统和非传统背景的个人提供了包容性的机会。
- 数字文艺复兴:NVIDIA Neuralangelo 研究重建 3D 场景
- 养鱼初创公司投入人工智能以使水产养殖更高效和可持续
- 小猪AI新闻,5月17日:Mojo Lang:新编程语言 • Pandas AI:生成式AI Python库
脑网络实验室
在完成本科学位后,一直萦绕在我心头的感觉是,我拥有了不错的理论基础,但缺乏将这些工具有效地应用于实践的实际理解。我设想了一个理想的场景,在神经科学或心理健康领域应用这些工具。
因此,当我有机会申请 Wicklow AI in Medicine 研究计划时,我感到非常兴奋。这意味着我将致力于在我的研究生课程中进行面向研究的实习,专注于“利用人工智能模型推进肿瘤学、心脏病学和神经病学等领域的医学研究”。
在该计划中,我被接受了 🎉,最终在 UCSF 的脑网络实验室工作。该实验室的重点是:
“通过将计算工具应用于神经成像数据,了解健康和疾病脑的机制。”
我迫不及待地等待着实习的进一步细节;内心充满了开始弥合理论和实践之间的差距的激情。最终,我收到了自己的任务,心情激动。
预测阿尔茨海默病患者的认知得分
任务:预测阿尔茨海默病患者的认知得分。 问题:我对计算机视觉完全没有经验。
我的第一印象是:“我怎么可能为此做出贡献?”自然而然地,恐惧和冒充者综合症的声音想要表达自己的存在。此外,我对深度学习的经验有限,甚至可以说是微不足道的,并且由于任务的复杂性,该职位本身也面临着被取消的风险。
然而,我所拥有的是全面理解阿尔茨海默病的动力、对受影响人群的真挚同情和利用我们所拥有的计算工具做出贡献的渴望。此外,理论和实践之间的脱节也激发了我做出贡献和成长的决心。
生活方式与阿尔茨海默病的相关性
我的第二印象是,仅仅依靠 MRI 数据来预测认知得分似乎有些奇怪,考虑到阿尔茨海默病与人口统计学、遗传学和生活方式的相关性。

在研究中,“肠道菌群、衰老、现代生活方式和阿尔茨海默病之间的联系”,作者强调:“报道了阿尔茨海默病患者肠道菌群的显著变化[…]肠道菌群对消极的外部生活方式因素非常敏感,如饮食、睡眠剥夺、昼夜节律紊乱、长期噪音和久坐行为,这些也被认为是散发性阿尔茨海默病发展的重要风险因素之一。
然而,我知道我需要专注于我的任务;尽管如此,好奇心却让我询问是否有可能获得人口统计和临床数据的访问权限,以防万一出现机会… *揉手*
我们稍后会回到这个问题。
测量认知功能
ADAS-Cog-11分数
同时,我继续使用MRI数据进行建模方法的头脑风暴。然而,你可能会想知道,我们如何定义“认知功能”呢?换句话说,我们的目标是什么?我们的目标标签是什么?
我们使用ADAS-Cog-11来测量认知功能——一种用于评估阿尔茨海默病患者记忆、语言和操作能力恶化的指标。根据维基百科,“它是最广泛使用的认知量表之一[…]被认为是评估抗痴呆治疗的‘黄金标准’”。
ADAS-Cog-11得分是从以下十一项认知任务中得出的:

你可以在这里找到每项任务的详细摘要。
简单卷积神经网络
为了开始实验,我们训练了一个基线卷积神经网络(CNN)模型,用MRI数据来预测认知分数。
这个简单的CNN包括以下层:第一卷积层、池化层、第二卷积层、池化层、2层全连接神经网络和回归层。
结果并不显著,交叉验证R2在0.33到0.52之间,测试R2为0.47。尽管如此,考虑到这个简单模型的谦虚期望,我们对建立一个可以改进的起始基线感到满意。
多任务学习和捕捉脑结构背景
下一步是研究痴呆的结构预测因素。这导致了一系列的文献,强调了灰质和白质体积与痴呆严重程度之间的独立关系。
据Stout等人称,
“定量磁共振方法提供了强有力的证据,即皮质灰质体积(可能反映萎缩)和异常白质体积与患有可能的阿尔茨海默病的痴呆严重程度是独立关系:较低的灰质和较高的异常白质体积与更严重的痴呆有关。”
由此,一个理论浮现:如果模型能够捕捉关于灰质和白质体积的信息,它应该提高预测能力。
但是我们该如何做到这一点呢?
简短的回答:✨多任务学习✨
“多任务学习是机器学习的一个子领域,在同一时间解决多个学习任务,同时利用任务之间的共性和差异[…]使用相关任务的训练信号中包含的领域信息[…]为每个任务学到的东西可以帮助其他任务更好地学习”
——多任务学习,2021年7月6日。 在维基百科中
直觉:如果我们的模型可以预测认知得分,并同时学习将输入的MRI扫描分割为白质、灰质和脑脊液,这些相互关联的任务将基于共享的领域信息提高每个单独任务的性能。
U-Net架构
在这个模型中,我们使用了U-Net架构:
“这种架构依赖于强大的数据增强,由一个收缩路径用于捕获上下文和一个对称的扩展路径用于精确定位组成,这样的网络可以从很少的图像中进行端对端的训练,并且优于先前最佳方法(滑动窗卷积网络)” — Ronneberger等人,2015年
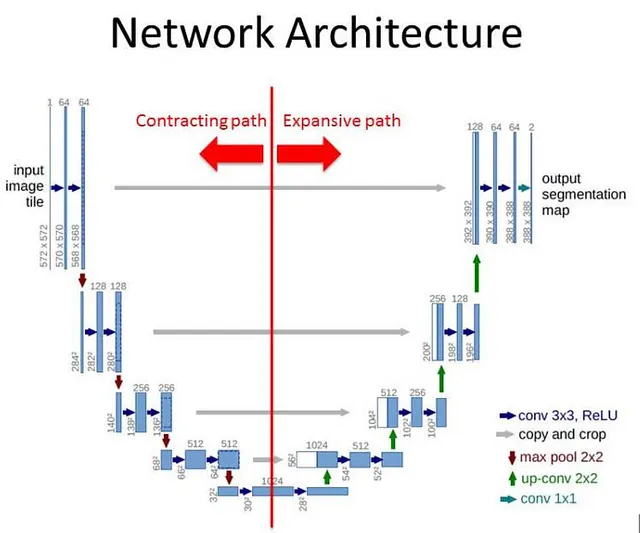
这是一个有吸引力的架构,我们可以用很少的图像来实现比以前的方法更好的性能,只要我们应用数据增强技术。
医学影像数据增强技术是什么?
数据增强是将随机化的变化(如平移、旋转、翻转、拉伸、剪切等)应用于输入图像的过程,以增加变异性。只要修改后的图像仍然在可能输入的范围内,这个过程就允许我们的模型通过引入对输入数据的微小偏移来更好地概括。
这些技术也是解决标记医学影像稀缺性的有价值解决方案。获得足够大的医学成像数据集是一个主要问题,原因有两个:1)医学扫描的手动注释非常耗时,2)临床数据的共享受到越来越严格的患者隐私法律的限制。

在不同器官和模态下的性能
通常的做法是尝试各种数据增强技术,以确定哪些对你的特定任务最有效。然而,在医学影像领域中,引导探索过程的一种方法是了解不同器官/结构、模态和任务组合的适当和最有效的增强技术。这里,“适当”是指确保增强数据包括输入空间内的有效示例。
例如,对于具有固有弹性或可变形性的器官,弹性变形通常是适合的。大脑组织就是一个很好的例子,由于大脑对经验、学习和环境变化做出结构和功能变化的非凡能力,也被称为神经可塑性。
一位被尊敬的现代神经科学之父Santiago Ramón y Cajal曾经宣称:
“任何人都可以,如果他愿意的话,成为自己大脑的雕塑家”
— Santiago Ramón y Cajal
然而,骨头的可变性有限,血管是刚性结构,因此应用弹性变形可能无法准确表示现实变化或保持解剖完整性。
此外,缩放(将图像缩放以强调特定区域)通常非常适合X光图像,因为它们通常包含更广泛的视野。然而,对于已经具有较窄视野并集中于特定感兴趣区域的MRI,缩放可能会意外地排除重要的上下文信息,从而使其作为MRI的增强技术不太适合。
这里有一篇非常全面的数据增强技术文献综述。作者强调了这一点:
“根据输入的性质和视觉任务,不同的数据增强策略可能会表现不同。因此,医学成像需要特定的增强策略,以生成可信的数据样本并有效地正则化深度神经网络”
多任务学习架构可视化
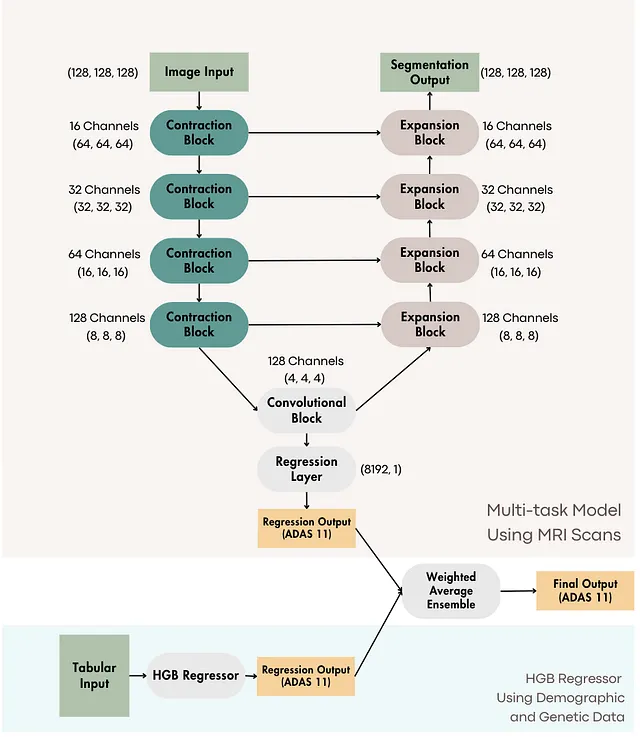
下面提供了多任务模型的可视化表示。在U-Net架构的最下方部分,我们加入了一个回归块。在这个块中,所有像素都被压平,然后通过一个线性层传递,得到的输出表示认知分数。
U-Net 和多任务学习表现
回顾一下,我们最初采用了一个简单的CNN基准模型,得到了交叉验证R2值在0.33到0.52之间的结果,测试R2为0.47。
然而,通过实现多任务模型,我们观察到了显著的改进:
- 交叉验证R2:提高到0.41至0.69的范围
- 测试R2:提高到0.57
值得一提的是,我们使用U-Net架构为分割任务开发了一个基准模型,其准确率为93.7%。
值得注意的是,分割任务也经历了性能提升,将准确率从93.7%提高到了97.27% 🎉

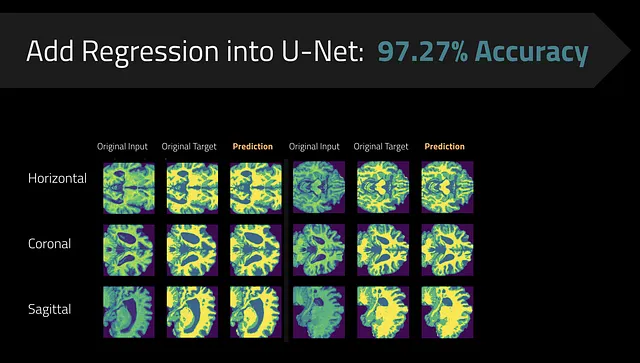
多任务模型似乎胜过了当时的最先进技术,如下所示:

那么人口统计和基因特征呢?
但是,我答应过的人口统计和基因特征呢?
好吧,我们得到了数据!*欢呼*
第一步是仅在表格特征上训练另一个基准模型。我们最终决定使用基于直方图的梯度提升回归器(HGB回归器),它具有泊松损失函数,产生了出乎意料的不错结果。
- 交叉验证R2:在0.56至0.63之间
- 测试R2:0.51
将表格数据整合到集成多任务模型中
在最终的实验中,我们构思了一些将这些特性有效整合到我们的模型中的方法。
由于成像数据(其中每个体素都被视为输入)和表格数据集(其中每个特征都表示为单个值)之间的输入数量存在实质性差异,因此将表格数据和成像数据进行整合是一项挑战。平等对待所有特征有可能会降低人口统计和基因风险因素在整体模型中的重要性。
为了解决这个问题,我们使用HGB回归器开发了一个单独的模型来处理表格数据。然后,我们应用了带权平均集成方法来合并HGB回归器和多任务模型的预测结果。为每个模型分配的权重基于它们的表现和可靠性,给予更准确或更自信的模型更高的权重。这种集成技术通过分配适当的权重有效地优化了每个模型的贡献。
下面是这种集成方法的可视化展示。
最终模型表现
那么,这种集成、多任务方法与以前的实验相比如何呢?
鼓声响起*
回归任务表现:
- 交叉验证R2:0.73-0.78
- 测试R2:0.67
分割任务表现:
- 准确率:98.12%
正如在多任务学习中所观察到的显着性能改进一样,通过集成方法将人口统计特征和遗传风险因素纳入模型,不仅显著提高了回归任务的性能,还进一步增强了分割任务的性能。这清楚地表明了利用多个数据源并发挥其协同潜力的威力。
结论
有机会深入探讨神经科学和机器学习的交叉点,特别是与阿尔茨海默病有关的交叉点,并意识到我的背景使我能够将各个领域的概念联系起来,这是具有变革性的。自从体验到将当前的神经科学研究与ML概念相结合所取得的重大改进以来,我对整合多样数据源和以面向领域的方式应用模型架构的能力有了更深刻的认识。
我希望这项研究能够激发以下人群的灵感:
- 已经从认知科学转向ML的人
- 鼓励获取和应用神经系统疾病技术的人
- 对医学领域的计算机视觉感兴趣的人
如果您有任何问题,请随时与我们联系,希望这对您与我一样充满激情!
用于图II的文章:
- 健康生活方式的组合可能会大大降低阿尔茨海默病的发病率
- 肠道微生物群、衰老、现代生活方式与阿尔茨海默病之间的联系
- 认知储备和生活方式:迈向临床前阿尔茨海默病