利用GPBoost进行混合效应机器学习,处理分组和区域空间计量数据
使用欧洲国内生产总值数据的示例
∘ 介绍 · 数据描述 · 数据加载和简要可视化 ∘ 训练GPBoost模型 ∘ 选择调参参数 ∘ 模型解释 · 估计的随机效应模型 · 空间效应图 · 理解固定效应函数 ∘ 扩展 · 不同时间段的独立随机效应 · 空间和固定效应预测变量之间的交互作用 · 大数据 · 其他空间随机效应模型 · (广义)线性混合效应和高斯过程模型 ∘ 参考文献
介绍
GPBoost算法通过使用树提升替换线性固定效应函数的非参数非线性函数来扩展线性混合效应和高斯过程模型。本文展示了如何使用GPBoost库中实现的GPBoost算法来对具有空间和分组结构的数据进行建模。我们使用欧洲国内生产总值数据作为示例,这是空间计量经济数据的例子。所有结果都是使用GPBoost版本1.2.1获得的。该演示使用R软件包,但相应的Python软件包提供相同的功能。
应用GPBoost模型(=组合树提升和随机效应/GP模型)涉及以下主要步骤:
- 定义一个
GPModel,其中指定以下内容: – 随机效应模型(例如,空间随机效应,分组随机效应,组合空间和分组等) – 似然函数(=响应变量在固定效应和随机效应条件下的分布) - 使用响应变量和固定效应预测变量创建
gpb.Dataset - 选择调参参数,例如使用函数
gpb.grid.search.tune.parameters - 使用
gpboost / gpb.train函数训练模型
在本文中,我们使用真实世界数据集演示这些步骤。此外,我们还展示如何解释拟合模型,并查看GPBoost库的几个扩展和其他特性。
数据描述
本演示使用的数据是欧洲国内生产总值(GDP)数据。它可以从https://raw.githubusercontent.com/fabsig/GPBoost/master/data/gdp_european_regions.csv下载。该数据由罗马大学托尔维亚塔分校的Massimo Giannini从Eurostat收集,并慷慨地提供给Fabio Sigrist在2023年6月16日于罗马大学托尔维亚塔分校的演讲中使用。
数据收集了242个欧洲地区的2000年和2021年的数据。即,数据点的总数为484。响应变量为(对数)GDP /人均。有四个预测变量:
- L:就业占比的(对数)份额(empl / pop)
- K:(对数)固定资本/人口
- Pop:对数(人口)
- Edu:高等教育占比
此外,还有每个地区的质心空间坐标(经度和纬度),242个不同欧洲地区的空间区域ID,以及标识地区所属簇的附加空间群集ID(共有两个簇)。
数据加载和简要可视化
我们首先加载数据并创建一个地图,说明空间上的(对数)GDP /人均。
library(gpboost)data <- read.csv("https://raw.githubusercontent.com/fabsig/GPBoost/master/data/gdp_european_regions.csv")data <- as.matrix(data) # convert to matrix since the boosting part currently does not support data.framescovars <- c("L", "K", "pop", "edu")library(ggplot2)library(viridis)library(gridExtra)p1 <- ggplot(data = data.frame(Lat=data[,"Lat"], Long=data[,"Long"], GDP=data[,"y"]), aes(x=Long,y=Lat,color=GDP)) + geom_point(size=2, alpha=0.5) + scale_color_viridis(option = "B") + ggtitle("GDP / capita (log)")p2 <- ggplot(data = data.frame(Lat=data[,"Lat"], Long=data[,"Long"], GDP=data[,"y"]), aes(x=Long,y=Lat,color=GDP)) + geom_point(size=3, alpha=0.5) + scale_color_viridis(option = "B") + ggtitle("GDP / capita (log) -- Europe excluding islands") + xlim(-10,28) + ylim(35,67)grid.arrange(p1, p2, ncol=2)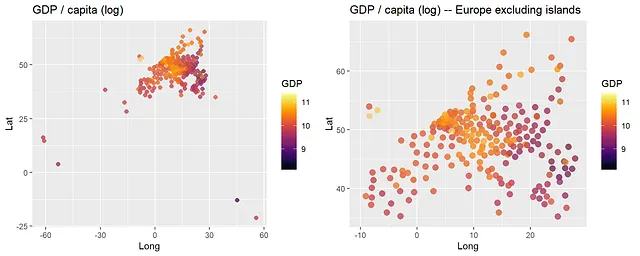
训练GPBoost模型
在以下内容中,我们使用高斯过程模型和指数协方差函数来建模空间随机效应。此外,我们在聚类变量cl中包括分组随机效应。在GPBoost库中,高斯过程随机效应由GPModel构造函数的gp_coords参数定义,分组随机效应由group_data参数定义。上述预测变量用于固定效应树合奏函数。我们使用gpboost函数或同等的gpb.train函数来拟合模型。请注意,我们使用下面选择的交叉验证的调整参数。
gp_model <- GPModel(group_data = data[, c("cl")], gp_coords = data[, c("Long", "Lat")], likelihood = "gaussian", cov_function = "exponential")params <- list(learning_rate = 0.01, max_depth = 2, num_leaves = 2^10, min_data_in_leaf = 10, lambda_l2 = 0)nrounds <- 37# gp_model$set_optim_params(params = list(trace=TRUE)) # 监控超参数估计boost_data <- gpb.Dataset(data = data[, covars], label = data[, "y"])gpboost_model <- gpboost(data = boost_data, gp_model = gp_model, nrounds = nrounds, params = params, verbose = 1) # 和gpb.train一样 # 和gpb.train一样 gpb.train选择调整参数
对于提升,正确选择调整参数非常重要。没有通用的默认值,每个数据集可能需要不同的调整参数。请注意,这可能需要一些时间。除了下面的固定网格搜索之外,也可以进行随机网格搜索以加快速度(请参见num_try_random)。下面我们展示如何使用gpb.grid.search.tune.parameters函数选择调整参数。我们使用均方误差(mse)作为验证数据上的预测准确性度量。或者,也可以使用例如测试负对数似然(如果没有指定,则为test_neg_log_likelihood)来考虑预测不确定性。
gp_model <- GPModel(group_data = data[, "cl"], gp_coords = data[, c("Long", "Lat")], likelihood = "gaussian", cov_function = "exponential")boost_data <- gpb.Dataset(data = data[, covars], label = data[, "y"])param_grid = list("learning_rate" = c(1,0.1,0.01), "min_data_in_leaf" = c(10,100,1000), "max_depth" = c(1,2,3,5,10), "lambda_l2" = c(0,1,10))other_params <- list(num_leaves = 2^10)set.seed(1)opt_params <- gpb.grid.search.tune.parameters(param_grid = param_grid, params = other_params, num_try_random = NULL, nfold = 4, data = boost_data, gp_model = gp_model, nrounds = 1000, early_stopping_rounds = 10, verbose_eval = 1, metric = "mse") # metric = "test_neg_log_likelihood"opt_params# ***** New best test score (l2 = 0.0255393919591794) found for the following parameter combination: learning_rate: 0.01, min_data_in_leaf: 10, max_depth: 2, lambda_l2: 0, nrounds: 37模型解释
估计随机效应模型
可通过在gp_model上调用summary函数来获取有关估计随机效应模型的信息。对于高斯过程,GP_var是边际方差,即空间相关性或结构空间变异的量,而GP_range是范围或尺度参数,它衡量相关性在空间上下降的速度。对于指数协方差函数,其值的三倍(约为17)是(残差)空间相关性基本上为零的距离(低于5%)。如下结果所示,空间相关性的量相对较小,因为边际方差为0.0089,与响应变量的总方差相比较小,后者约为0.29。此外,误差项和cl分组随机效应的方差也很小(0.013和0.022)。因此,我们得出结论,响应变量的大部分方差都由固定效应预测变量解释。
summary(gp_model)
## =====================================================## Covariance parameters (random effects):## Param.## Error_term 0.0131## Group_1 0.0221## GP_var 0.0089## GP_range 5.7502## =====================================================空间效应图
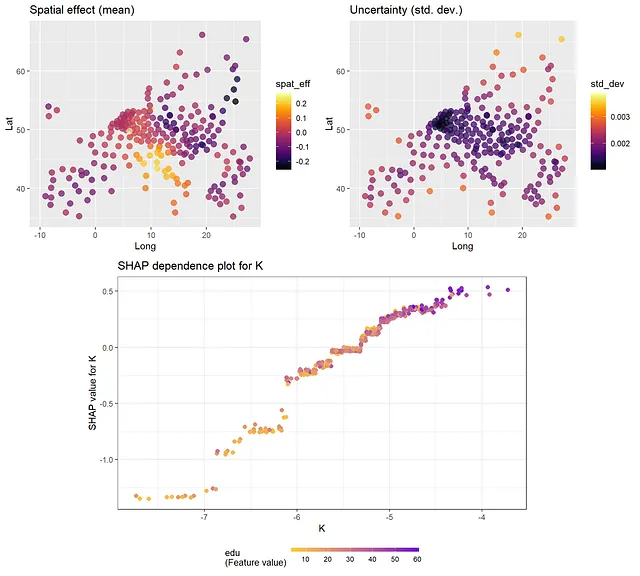
我们可以通过在训练数据上调用predict函数,绘制出训练数据位置上估计(“预测”)的空间随机效应;请参见下面的代码。这样的绘图显示了固定效应预测变量效应排除后的空间效应。请注意,这些空间效应考虑了空间高斯过程和分组区域聚类随机效应。如果想从高斯过程部分获得仅空间随机效应,可以使用predict_training_data_random_effects函数(请参见下面的注释代码)。或者,也可以进行空间外推(=“克里金”),但这对面积数据来说没有太多意义。
pred <- predict(gpboost_model, group_data_pred = data[1:242, c("cl")], gp_coords_pred = data[1:242, c("Long", "Lat")], data = data[1:242, covars], predict_var = TRUE, pred_latent = TRUE)plot_mu <- ggplot(data = data.frame(Lat=data[,"Lat"], Long=data[,"Long"], spat_eff=pred$random_effect_mean),aes(x=Long,y=Lat,color=spat_eff)) + geom_point(size=3, alpha=0.5) + scale_color_viridis(option = "B") + ggtitle("空间效应(平均值)") + xlim(-10,28) + ylim(35,67)plot_sd <- ggplot(data = data.frame(Lat=data[,"Lat"], Long=data[,"Long"], std_dev=pred$random_effect_cov),aes(x=Long,y=Lat,color=std_dev)) + geom_point(size=3, alpha=0.5) + scale_color_viridis(option = "B") + ggtitle("不确定性(标准偏差)") + xlim(-10,28) + ylim(35,67)grid.arrange(plot_mu, plot_sd, ncol=2)# # 仅从高斯过程中提取空间效应# rand_effs <- predict_training_data_random_effects(gp_model, predict_var = TRUE)[1:242, c("GP", "GP_var")]# plot_mu <- ggplot(data = data.frame(Lat=data[,"Lat"], Long=data[,"Long"], spat_eff=rand_effs[,1]),aes(x=Long,y=Lat,color=spat_eff)) +# geom_point(size=3, alpha=0.5) + scale_color_viridis(option = "B") + # ggtitle("高斯过程中的空间效应(平均值)") + xlim(-10,28) + ylim(35,67)# plot_sd <- ggplot(data = data.frame(Lat=data[,"Lat"], Long=data[,"Long"], std_dev=rand_effs[,2]),aes(x=Long,y=Lat,color=std_dev)) +# geom_point(size=3, alpha=0.5) + scale_color_viridis(option = "B") + # ggtitle("不确定性(标准偏差)") + xlim(-10,28) + ylim(35,67)# grid.arrange(plot_mu, plot_sd, ncol=2)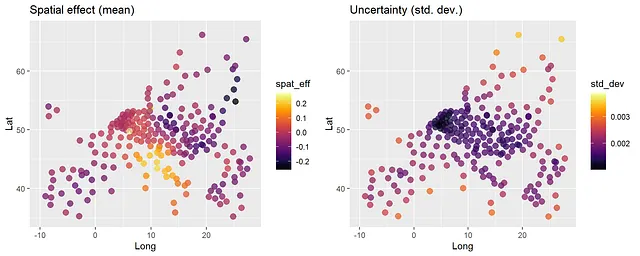
理解固定效应函数
有几种工具可以理解固定效应函数的形式。以下我们考虑变量重要性度量、交互度量和依赖性图。具体而言,我们看一下
- SHAP值
- SHAP依赖性图
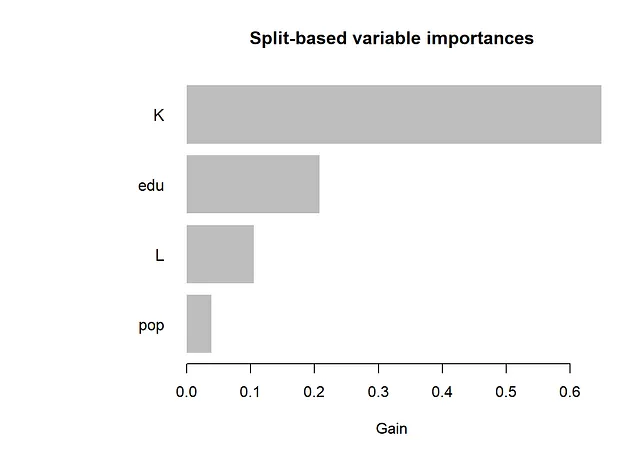
- 基于分割的变量重要性
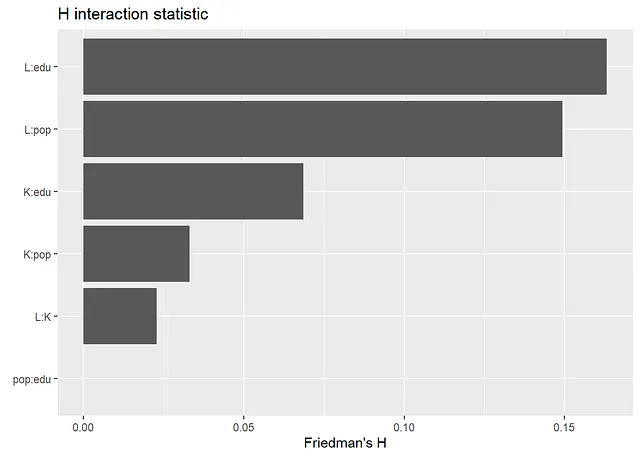
- Friedman的H统计量
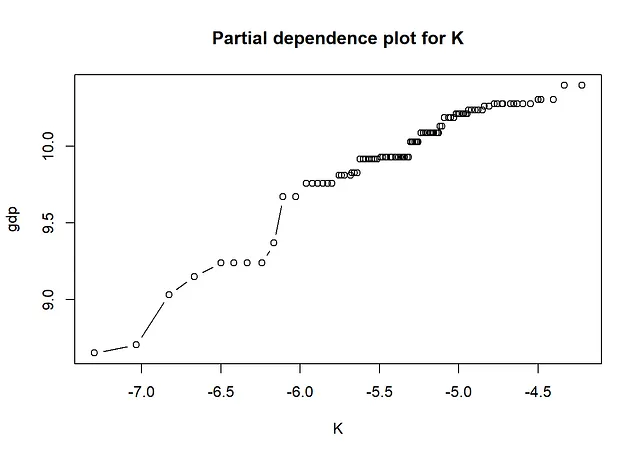
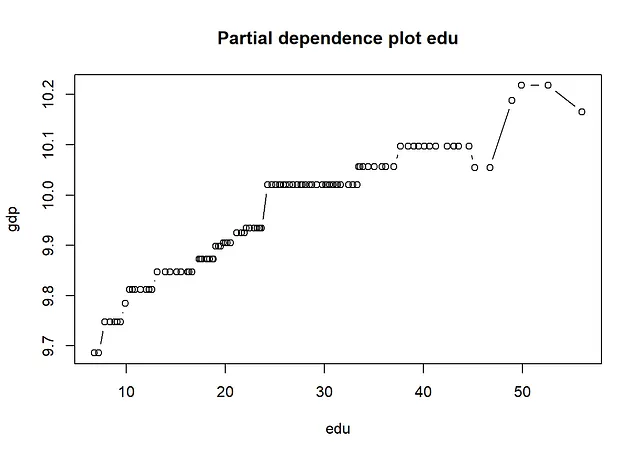
- 偏依赖图(一维和二维)
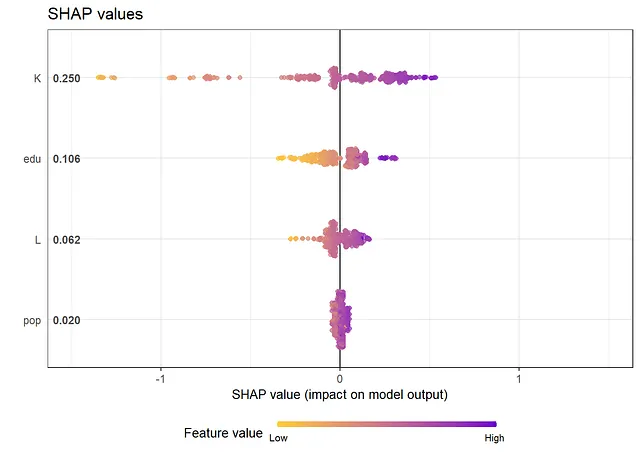
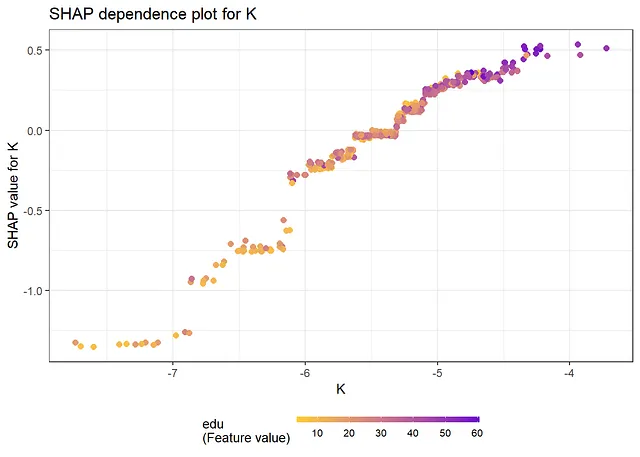
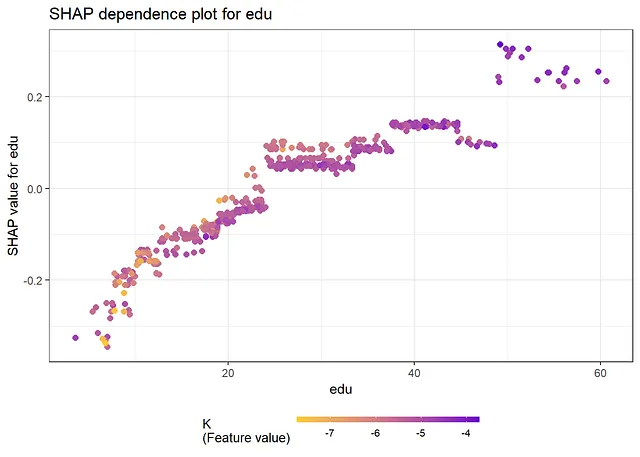
正如下面的结果所示,从SHAP值和SHAP依赖图获得的信息与查看传统的变量重要性度量和偏依赖图时获得的信息相同。最重要的变量是“K”和“edu”。从依赖图中,我们可以得出结论,存在非线性关系。例如,对于大和小值的K,其效应几乎是平的,在中间则会增加。此外,edu的效应在edu的小值时更加陡峭,而在edu的大值时则会变平。Friedman的H统计量表明存在一些交互作用。对于交互作用最多的两个变量L和pop,我们在下面创建了一个二维偏依赖图。
# SHAP值库
library(SHAPforxgboost)
shap.plot.summary.wrap1(gpboost_model, X = data[,covars]) + ggtitle("SHAP值")
# SHAP依赖图
shap_long <- shap.prep(gpboost_model, X_train = data[,covars])
shap.plot.dependence(data_long = shap_long, x = covars[2], color_feature = covars[4], smooth = FALSE, size = 2) + ggtitle("K的SHAP依赖图")
shap.plot.dependence(data_long = shap_long, x = covars[4], color_feature = covars[2], smooth = FALSE, size = 2) + ggtitle("edu的SHAP依赖图")
# 基于分割的特征重要性
feature_importances <- gpb.importance(gpboost_model, percentage = TRUE)
gpb.plot.importance(feature_importances, top_n = 25, measure = "Gain", main = "基于分割的变量重要性")
# 交互的H统计量。请注意:如果max_depth = 1,则没有交互
library(flashlight)
fl <- flashlight(model = gpboost_model, data = data.frame(y = data[,"y"], data[,covars]), y = "y", label = "gpb", predict_fun = function(m, X) predict(m, data.matrix(X[,covars]), gp_coords_pred = matrix(-100, ncol = 2, nrow = dim(X)[1]), group_data_pred = matrix(-1, ncol = 1, nrow = dim(X)[1]), pred_latent = TRUE)$fixed_effect)
plot(imp <- light_interaction(fl, v = covars, pairwise = TRUE)) + ggtitle("交互统计")
# 局部依赖图
gpb.plot.partial.dependence(gpboost_model, data[,covars], variable = 2, xlab = covars[2], ylab = "gdp", main = "K的局部依赖图")
gpb.plot.partial.dependence(gpboost_model, data[,covars], variable = 4, xlab = covars[4], ylab = "gdp", main = "edu的局部依赖图")
# 二维部分依赖图(用于可视化交互作用)
i = 1; j = 3; # i vs j
gpb.plot.part.dep.interact(gpboost_model, data[,covars], variables = c(i,j), xlab = covars[i],
ylab = covars[j], main = "二元部分依赖图")
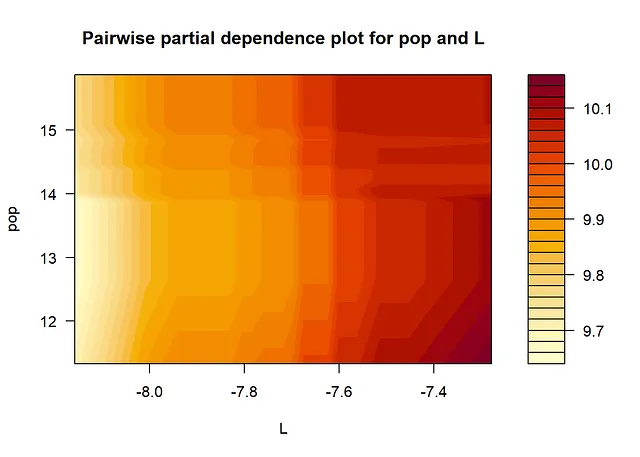
扩展
不同时间段的独立随机效应
在上述模型中,我们使用了相同的随机效应来描述2000年和2021年的数据。另一种方法是使用不同的空间和分组随机效应来描述不同的时间段(在先验下独立,条件于数据,存在依赖关系…)。在GPBoost库中,可以通过cluster_ids参数实现这一点。 cluster_ids需要是一个样本大小的向量,每个条目指示观察属于的“群集”。然后,不同的群集具有独立的空间和分组随机效应,但是超参数(例如边际方差、方差分量等)和固定效应函数在群集之间是相同的。
下面我们展示如何拟合这样的模型并创建两个单独的空间图。如下所示,两年的空间效应有很大不同。特别是,2021年的残差空间变化(或异质性)较少。这通过查看预测的空间随机效应的标准偏差得到了证实,2000年的标准偏差几乎是2021年的两倍(见下文)。进一步的结论是,在2000年,有更多地区的GDP数据较低(空间效应低于0),而在2021年不再如此。
gp_model <- GPModel(group_data = data[, c("cl")], gp_coords = data[, c("Long", "Lat")],
likelihood = "gaussian", cov_function = "exponential",
cluster_ids = c(rep(1,242), rep(2,242)))
boost_data <- gpb.Dataset(data = data[, covars], label = data[, "y"])
params <- list(learning_rate = 0.01, max_depth = 1, num_leaves = 2^10,
min_data_in_leaf = 10, lambda_l2 = 1) # 注意:我们使用与上面相同的调参参数,理想情况下,需要重新选择
gpboost_model <- gpboost(data = boost_data, gp_model = gp_model, nrounds = nrounds,
params = params, verbose = 0)
# 年份为2000和2021的单独空间映射
pred <- predict(gpboost_model, group_data_pred = data[, c("cl")],
gp_coords_pred = data[, c("Long", "Lat")],data = data[, covars], predict_var = TRUE,
pred_latent = TRUE,cluster_ids_pred = c(rep(1,242), rep(2,242)))
plot_mu_2000 <- ggplot(data = data.frame(Lat=data[,"Lat"], Long=data[,"Long"],
spat_eff=pred$random_effect_mean[1:242]), aes(x=Long,y=Lat,color=spat_eff)) +
geom_point(size=3, alpha=0.5) + scale_color_viridis(option = "B") +
ggtitle("2000年的空间效应(平均)") + xlim(-10,28) + ylim(35,67)
plot_mu_2021 <- ggplot(data = data.frame(Lat=data[,"Lat"], Long=data[,"Long"],
spat_eff=pred$random_effect_mean[243:484]), aes(x=Long,y=Lat,color=spat_eff)) +
geom_point(size=3, alpha=0.5) + scale_color_viridis(option = "B") +
ggtitle("2021年的空间效应(平均)") + xlim(-10,28) + ylim(35,67)
grid.arrange(plot_mu_2000, plot_mu_2021, ncol=2)

空间和固定效应预测变量之间的交互作用
在上面的模型中,随机效应和固定效应预测变量之间没有交互作用。即,空间坐标和固定效应预测变量之间没有交互作用。可以通过在固定效应函数中另外包含随机效应输入变量(即空间坐标或分类分组变量)来建模这种交互作用。下面的代码展示了如何实现。如下所示的变量重要性图表显示,坐标在树集合中没有被使用,因此在此数据集中无法检测出这种交互作用。
gp_model <- GPModel(group_data = data[, c("cl")], gp_coords = data[, c("Long", "Lat")], likelihood = "gaussian", cov_function = "exponential")covars_interact <- c(c("Long", "Lat"), covars) ## 将空间坐标添加到固定效应预测变量中boost_data <- gpb.Dataset(data = data[, covars_interact], label = data[, "y"])params <- list(learning_rate = 0.01, max_depth = 1, num_leaves = 2^10, min_data_in_leaf = 10, lambda_l2 = 1) # 注意:我们使用与上面相同的调参参数。理想情况下,应该再次选择调参参数gpboost_model <- gpboost(data = boost_data, gp_model = gp_model, nrounds = nrounds, params = params, verbose = 0)feature_importances <- gpb.importance(gpboost_model, percentage = TRUE)gpb.plot.importance(feature_importances, top_n = 25, measure = "Gain", main = "当在固定效应中包括坐标时的变量重要性")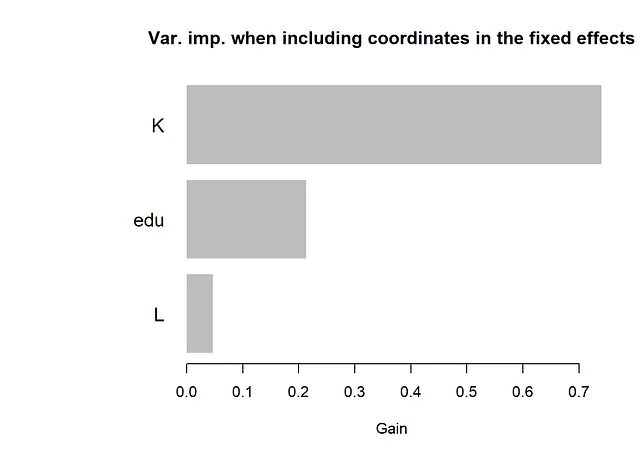
大数据
对于大型数据集,使用高斯过程进行计算会很慢,因此必须使用一种近似方法。 GPBoost 库实现了许多近似方法。例如,在 GPModel 构造函数中设置 gp_approx="vecchia" 将使用 Vecchia 近似。本文中使用的数据集相对较小,我们可以精确地进行所有计算。
其他空间随机效应模型
上面,我们使用高斯过程来模拟空间随机效应。由于数据是区域性数据,因此另一种选择是使用依赖于邻域信息的模型,例如 CAR 和 SAR 模型。这些模型目前尚未在 GPBoost 库中实现(可能会在将来添加 -> 联系作者)。
另一种选择是使用由分类区域 ID 变量定义的分组随机效应模型来建模空间效应。下面的代码展示了如何在 GPBoost 中实现此操作。但是,该模型实质上忽略了空间结构。
gp_model <- GPModel(group_data = data[, c("group", "cl")], likelihood = "gaussian")(广义)线性混合效应和高斯过程模型
(广义)线性混合效应和高斯过程模型也可以在 GPBoost 库中运行。下面的代码展示了如何使用 fitGPModel 函数实现此操作。请注意,需要手动添加一列 1 来包括截距。
X_incl_1 = cbind(Intercept = rep(1,dim(data)[1]), data[, covars])gp_model <- fitGPModel(group_data = data[, c("cl")], gp_coords = data[, c("Long", "Lat")], likelihood = "gaussian", cov_function = "exponential", y = data[, "y"], X = X_incl_1, params = list(std_dev=TRUE))summary(gp_model)
## =====================================================## 模型总结:## 对数似然 AIC BIC ## 195.97 -373.94 -336.30 ## 观测量:484## 组数:2(Group_1)## -----------------------------------------------------## 协方差参数(随机效应):## 参数 标准差## Error_term 0.0215 0.0017## Group_1 0.0003 0.0008## GP_var 0.0126 0.0047## GP_range 7.2823 3.6585## -----------------------------------------------------## 线性回归系数(固定效应):## 参数 标准差 z 值 P(>|z|)## Intercept 16.2816 0.4559 35.7128 0.0000## L 0.4243 0.0565 7.5042 0.0000## K 0.6493 0.0212 30.6755 0.0000## pop 0.0134 0.0097 1.3812 0.1672## edu 0.0100 0.0009 10.9645 0.0000## =====================================================参考文献
- Sigrist Fabio. “高斯过程提升”. 机器学习研究杂志 (2022).
- Sigrist Fabio. “潜在高斯模型提升”. IEEE 模式分析与机器智能交易 (2023).
- https://github.com/fabsig/GPBoost
- 数据集来源于 Eurostat; 更多关于权利的信息请参见 https://ec.europa.eu/eurostat/about-us/policies/copyright (“Eurostat 鼓励自由重复使用其数据,无论是商业用途还是非商业用途。”)