从Python到Julia:特征工程和机器学习

用Julia构建欺诈检测模型的方法
这是我关于利用Julia进行应用数据科学的两篇系列文章中的第二篇。在第一篇文章中,我们通过一些简单的数据操作和使用Julia进行探索性数据分析的示例。在本文中,我们将继续构建欺诈检测模型的任务,以识别欺诈交易。
简要回顾一下,我们使用了从Kaggle获取的信用卡欺诈检测数据集。该数据集包含30个特征,包括交易时间、金额和通过PCA得到的28个主成分特征。下面是数据集的前5个实例的屏幕截图,以Julia中的dataframe形式加载。请注意,交易时间特征记录了当前交易和数据集中第一笔交易之间经过的时间(以秒为单位)。
特征工程
在训练欺诈检测模型之前,让我们为模型准备好要消耗的数据。由于本文的主要目的是介绍Julia,我们不会在此处执行任何特征选择或特征合成。
数据分割
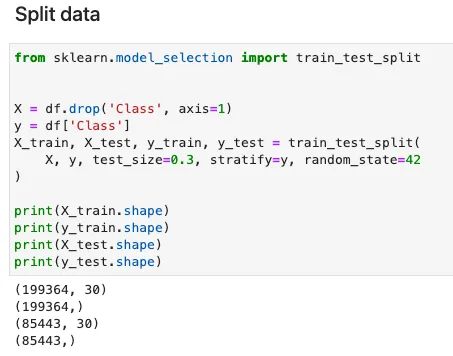
训练分类模型时,数据通常以分层方式进行训练和测试。主要目的是在训练和测试数据中保持数据相对于目标类变量的分布。当我们使用极度不平衡的数据集时,这是特别必要的。Julia中的MLDataUtils包提供了一系列预处理函数,包括数据拆分、标签编码和特征归一化。以下代码展示了如何使用MLDataUtils中的stratifiedobs函数执行分层抽样。可以设置随机种子,以便可以重复相同的数据拆分。
数据分割为训练和测试 — Julia实现
stratifiedobs函数的使用方式与Python中sklearn库中的train_test_split函数非常相似。请注意,输入特征X需要通过两次转置才能恢复数据集的原始维度。对于像我这样的Julia新手来说,这可能会令人困惑。我不确定MLDataUtils的作者为什么以这种方式开发了该函数。
等效的Python sklearn实现如下。
特征缩放
作为机器学习中的推荐实践,特征缩放可以将特征带到相同或类似的值范围或分布。特征缩放有助于提高训练神经网络的收敛速度,还可以避免在训练过程中任何单个特征的支配。
虽然在这项工作中我们没有训练神经网络模型,但我仍然想了解如何在Julia中执行特征缩放。不幸的是,我找不到一个Julia库,它提供了拟合缩放器和转换特征的两个函数。MLDataUtils包中提供的特征归一化函数允许用户派生特征的平均值和标准差,但它们不能轻松地应用于训练/测试数据集以转换特征。由于特征的平均值和标准差可以很容易地在Julia中计算,我们可以手动实现标准缩放过程。
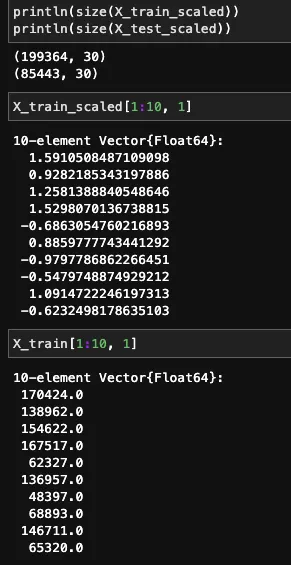
以下代码创建了X_train和X_test的副本,并在循环中计算每个特征的平均值和标准差。
标准化特征 — Julia实现
转换后的和原始特征如下所示。
在Python中,sklearn提供了各种特征缩放的选项,包括归一化和标准化。通过声明一个特征缩放器,只需要两行代码即可完成缩放。以下代码给出了使用RobustScaler的示例。

过采样(通过PyCall)
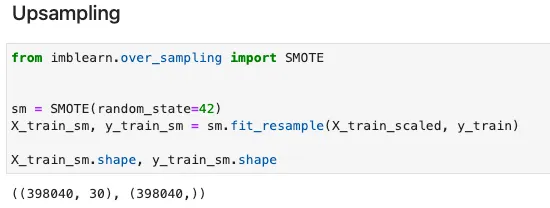
欺诈检测数据集通常严重不平衡。例如,我们的数据集中负面例子与正面例子的比率超过500:1。由于无法获得更多的数据点,欠采样将导致大量的多数类数据点丢失,因此在这种情况下,过采样是最佳选择。在这里,我应用了流行的SMOTE方法为正面类创建合成示例。
目前,没有可用的Julia库提供SMOTE的实现。 ClassImbalance包已经两年没有维护,不能与最新版本的Julia一起使用。幸运的是,Julia允许我们使用一个名为PyCall的包装库调用现成的Python包。
要将Python库导入Julia,我们需要安装PyCall并将PYTHONPATH指定为环境变量。我尝试在此处创建Python虚拟环境,但它没有成功。由于某些原因,Julia无法识别虚拟环境的python路径。这就是为什么我不得不指定系统默认的python路径。之后,我们可以导入SMOTE的Python实现,该实现在imbalanced-learn库中提供。 PyCall提供的pyimport函数可用于在Julia中导入Python库。以下代码显示了如何在Julia内核中激活PyCall并向Python请求帮助。
使用SMOTE上采样训练数据 – Julia实现
等效的Python实现如下。我们可以看到,在Julia中以相同的方式使用fit_resample函数。
模型训练
现在我们来到了模型训练阶段。我们将训练一个二元分类器,可以使用各种ML算法完成,包括逻辑回归、决策树和神经网络。目前,Julia中的ML资源分布在多个Julia库中。让我列出一些最流行的选项及其专业的模型集。
- MLJ:传统的ML算法
- ScikitLearn:传统的ML算法
- Mocha:神经网络
- Flux:神经网络
这里我将选择XGBoost,考虑到它在传统回归和分类问题上的简单性和优越性能。在Julia中训练XGBoost模型的过程与Python相同,尽管语法上有一些细微的差异。
使用XGBoost训练欺诈检测模型 – Julia实现
等效的Python实现如下。
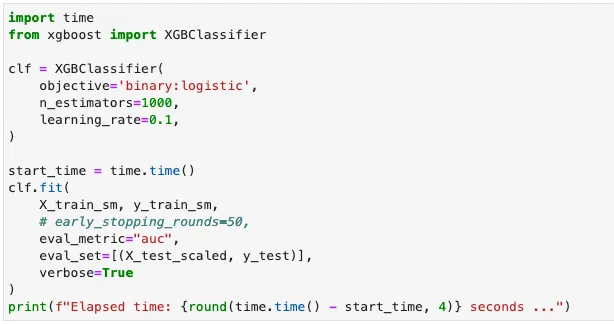
模型评估
最后,让我们通过查看测试数据上获得的精确度和召回率以及训练模型所花费的时间来查看我们的模型表现如何。在Julia中,可以使用EvalMetrics库计算精确度和召回率指标。相同目的的替代包是MLJBase。
进行预测并计算度量标准 – Julia实现
在Python中,我们可以使用sklearn来计算指标。
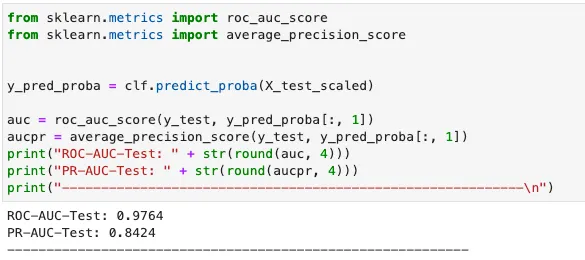
那么 Julia 和 Python 哪个更优秀呢?为了公平比较,两种模型都使用默认超参数进行训练,学习率为 0.1,估计器数量为 1000。性能指标总结在以下表格中。
可以看到,Julia 模型在稍长的训练时间内实现了更好的精度和召回率。由于 Python 模型训练所使用的 XGBoost 库是由 C++ 编写的,而 Julia XGBoost 库完全是由 Julia 编写的,所以 Julia 运行速度如同 C++,正如它所声称的那样!
上述测试使用的硬件:11 代英特尔® Core™ i7–1165G7 @ 2.80GHz — 4 核心。
Jupyter notebook 可以在 Github 上找到。
结论
我想以一个总结不同数据科学任务所提到的 Julia 库来结束这个系列。
由于缺乏社区支持,目前无法将 Julia 的可用性与 Python 进行比较。尽管如此,鉴于其出色的性能,Julia 在未来仍具有巨大的潜力。
参考文献
- ULB(Bruxelles 自由大学)机器学习组。 (无日期)。信用卡欺诈检测[数据集]。 H i i(数据库内容许可证(DbCL))
- Akshay Gupta。2021 年 5 月 13 日。开始使用 Julia 进行机器学习:机器学习的顶级 Julia 库。 https://www.analyticsvidhya.com/blog/2021/05/top-julia-machine-learning-libraries/