超越准确性:在长期用户保留中拥抱偶然性与新颖性的推荐
推荐系统
探讨影响良好推荐和长期用户留存的因素

在咖啡店形成的信任联系
你坐在咖啡店里,品尝着你最喜欢的咖啡(当然是卡布奇诺),与朋友沉浸在谈话中。随着话题的推进,你们开始谈论最近追的电视剧。共同的兴趣建立起了一种信任关系,以至于你的朋友热切地询问你:“下一个我该看什么?你有什么推荐吗?”
在那一刻,你成为了他们娱乐体验的策展人。你有责任保持他们的信任并提供保证能够吸引他们的建议。此外,你很兴奋有机会向他们介绍一些他们以前没有尝试过的新类型或情节。
但是,哪些因素影响了你在为朋友考虑完美推荐时的决策过程呢?
什么是好的推荐?

首先,你要了解你朋友的口味和兴趣。你回想起他们喜欢复杂的情节转折和黑色幽默;此外,你知道他们喜欢像“神探夏洛克”和“黑镜”这样的犯罪剧和心理惊悚片。有了这些知识,你就可以在心理图书馆中寻找电视节目。
玩得保险?
你想建议一些几乎与你之前热烈推荐的电视节目相同,只是稍微有些变化,包括犯罪和惊悚。你还考虑到其他口味相似的人喜欢这些节目,以缩小你的选择范围。毕竟,他们几乎保证会喜欢这些节目;这是一个安全和容易的选择。然而,你也考虑到仅仅依赖他们过去的喜好可能会限制他们接触新的和多样化的内容,并且不想依赖安全和容易的选择。
你会想起最近的一部科幻剧,巧妙地融合了神秘、冒险和超自然的情节。虽然它不同于他们通常喜欢的类型,但你相信它会提供一种清新和迷人的叙述变化。
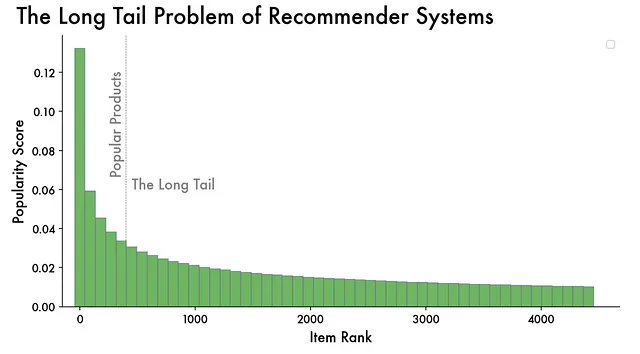
长尾问题、反馈循环和过滤气泡
推荐系统旨在在更大的范围内复制这一过程。通过分析有关个人偏好、行为和过去经验的大量数据,这些系统努力生成涵盖人类决策复杂性的个性化推荐。
然而,传统上,推荐系统主要——如果不是全部——关注玩得保险,依赖那些保证能够满足需求(至少在短期内)的推荐。
他们这样做的一种方法是优先考虑热门或主流内容。结果,这些流行内容会获得更多的曝光和互动(流行度偏见),形成一个反馈循环,强化它们的显著性。不幸的是,这经常使较少人知道的或者利基市场的内容难以获得可见度和触达目标受众(长尾问题)。
实际上,在过去的几年里,有很多文献探讨了推荐系统中的“公平”问题。例如,在《音乐推荐系统的公平性:以利益相关者为中心的小型评论》中,Karlijn Dinnissen和Christine Bauer从多个利益相关者的角度分析了音乐推荐系统中的公平性和流行度偏见问题,例如,流行度偏见对艺术家代表性的影响。
在文章“公正在问题:音乐推荐算法是否重视多样性?”中,朱莉·尼布分享了:
作为一家流媒体平台的前产品总监,我经常收到像“流媒体服务是否选择推广流行艺术家而不是独立和小众音乐?”这样的问题。直觉上,人们认为在这些大平台上“富者越富”。
在文章的后面,尼布也echoes了丹尼森和鲍尔的观点:
“在音乐推荐的背景下,公平经常是以曝光或关注的形式定义的。流媒体服务也是一个双边市场,这意味着“公平和公正的待遇”必须适用于流媒体服务的用户和艺术家。
两个来源突出了推荐系统中公平的双重性质,强调了考虑对用户和内容创作者“公正和公正的待遇”的重要性。
理想的结果是什么样的?
自然地,内容的分布存在内在的不平衡。人类经验之所以丰富,部分原因在于其网络复杂性;一些内容与更广泛的受众共鸣,而其他内容则在小众群体中建立联系,发展出丰富和个性化的感觉。目标不是为了人为地推广不那么流行的内容,而是为了将小众内容呈现给真正与之相关并能欣赏内容创作者的作品的个人,从而最小化有意义的联系的机会。
行业对此有何看法?
2020年,Spotify的研究团队发布了一篇题为“算法对Spotify消费多样性的影响”的文章。在他们的研究中,他们考察了听众多样性和用户结果之间的关系。
他们的目的是回答以下问题:“多样性与重要用户结果之间的关系如何?听众多样性较大的用户与听众较窄的用户相比,是更满意还是不满意?”
研究人员发现,“听众多样性较大的用户与听众较窄的用户相比,他们流失的可能性减少了10-20个百分点,听众多样性与用户转化和保留有关。”
此外,根据朱莉·尼布的说法:
“TikTok的推荐算法最近被MIT技术评论评为前十名之一。他们方法中的创新不在于算法本身,而在于他们优化的指标,更注重多样性而不是其他因素。”
因此,在平台内的可发现性属性和用户保留之间存在联系。换句话说,当推荐变得可预测时,用户可能会寻求提供更多内容“新鲜感”的其他平台,以便他们逃脱过滤气泡的限制。
那么推荐系统如何模拟您在为朋友策划完美建议时所使用的周到和直觉呢?
转向多样性指标
在文章“推荐系统中的多样性,意外,新颖和覆盖范围:超出准确度目标的调查和实证分析”中,作者Marius Kaminskas和Derek Bridge强调:
“推荐系统的研究传统上关注准确度[…],但已经认识到其他推荐质量——如推荐列表是否多样化以及是否包含新颖的内容——可能对推荐系统的整体质量产生重要影响。因此[…]推荐系统研究的重心已经转向包括更广泛的“超出准确度”目标。”
这些“超出准确度”目标是什么?
多样性
在试图理解推荐系统中的“多样性”是什么的过程中,筛选文献是残酷的,因为每篇文章都提出了自己独特的定义。多样性可以在个体水平或全局水平上进行衡量。我们将介绍三种在给朋友提供建议的背景下概念化多样性的方法。
推荐多样性
推荐多样性是指在给定的推荐集合中推荐内容的差异程度。当你向你的朋友推荐一些节目时,推荐多样性会评估推荐内容在流派、主题或其他相关因素方面的差异程度。
更高的推荐多样性意味着推荐集合中有更多的选择,为你的朋友提供更加多样化和丰富的观影体验。
其中一种衡量方法是使用列表内多样性(ILD),这是推荐项之间平均差异的度量。给定推荐项列表,ILD定义如下:

用户多样性
在向朋友提供节目推荐时,用户多样性考虑的是你向该特定朋友提供的所有推荐的平均多样性。它考虑了随着时间的推移,为他们建议的内容的广度和多样性,捕捉到了所涵盖的流派、主题或其他相关因素的范围。
你还可以通过分析每个朋友推荐集合内的项嵌入之间的平均差异来评估用户多样性。
全局多样性
另一方面,全局多样性超越了特定朋友,评估你向任何朋友提供的所有推荐的平均多样性。
有时,这被称为拥堵——反映了推荐均匀性或推荐拥挤的情况。
你可以使用一些指标来分析全局多样性,其中包括基尼指数和熵。
基尼指数是从收入不平等测量领域改编而来,用于评估推荐系统中推荐分布的公正性和平衡性。较低的基尼指数表明推荐分布更公平,推荐内容更均衡地分布,促进更大程度的多样性和对更广泛内容的曝光。相反,较高的基尼指数表明推荐集中在少数流行项上,可能限制了小众内容的可见性,减少了推荐的多样性。
熵是推荐过程中所包含的信息量的度量。它量化了推荐分布中的不确定性或随机性。与基尼指数类似,当推荐分布均匀时,最佳熵值得到实现,这意味着每个项被推荐的概率相等。这表明了一个平衡和多样化的推荐集。更高的熵表明推荐系统更加多样化和不可预测,而较低的熵表明推荐集更加集中和可预测。
覆盖率
覆盖率被定义为算法可以产生的所有可能推荐的部分/比例。换句话说,推荐算法在向用户推荐歌曲时有效地覆盖了可用歌曲的全部目录。
缺点:这个指标将一次推荐的项目与被推荐数千次的项目视为相同。
新颖性
新颖性是用于衡量推荐项中新颖或原创程度的度量。它包括两个方面:用户相关和用户无关的新颖性。用户相关的新颖性衡量推荐内容对用户的不同或不熟悉程度,表明了新鲜和未开发的内容的存在。然而,越来越常见的是以用户无关的方式来参考项目的新颖性。
估算新颖性的一种常见方法是考虑项目的流行度,这是以项目稀有度来衡量的。这种方法将项目的新颖性与其流行度相反地关联起来,认识到不太流行的项目通常被认为更具有新颖性,因为它们偏离了主流或广为人知的选择。通过融合这种观点,新颖性指标提供了关于推荐内容中创新和多样性水平的见解,有助于更加丰富和探索性的推荐体验。
意外性(惊喜)
推荐系统中的惊喜度是基于用户历史交互的推荐物品中意外程度的度量。一种量化惊喜度的方法是通过计算推荐物品和用户过去交互之间的余弦相似度。较高的相似度表示推荐物品的惊喜度较低,而较低的相似度则表示推荐的惊喜度更大。
可发现性
推荐系统中的可发现性可以理解为用户轻松查找和找到模型建议的推荐的能力。类似于推荐在用户界面或平台中的可见性和可访问性。
它使用递减的排名折扣函数进行量化,该函数将更高的重要性分配给推荐列表顶部的推荐,随着排名位置的下降逐渐降低它们的权重。
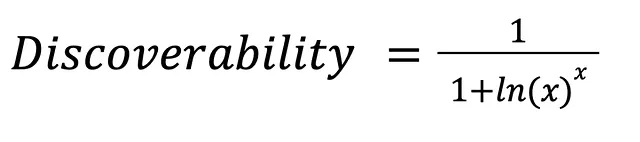
意外性
推荐系统中的意外性包括两个关键方面:意外性和相关性。
意外性指愉快惊喜的发生或有趣且意想不到的建议的发现。为了量化意外性,它是根据以下公式在每个用户和每个项目的基础上计算的:
通过乘以意外性和相关性,意外性指标结合了愉快惊喜和适用性的元素。它量化了推荐程度的意外性和相关性,为推荐过程中的意外体验提供了一种度量。
跨用户和推荐项目的整体意外性可以计算为:
总结
随着行业的发展,越来越强调优化推荐算法,以提供涵盖用户偏好整体的推荐,包括更丰富的个性化、意外性和新颖性。此外,优化这些维度之间的平衡的推荐系统还与改善用户保留度和用户体验相关。最终的目标是创建推荐系统,不仅迎合用户已知的偏好,而且还通过新鲜、多样化和个性化的推荐给他们带来惊喜和愉悦,促进长期的参与和满意度。
参考文献
- 推荐系统中的多样性、意外性、新颖性和覆盖范围:调查和实证分析
- 面向多样性的推荐系统的后处理
- 推荐系统中的多样性-一项调查
- 避免拥堵在推荐系统中
- 推荐系统中新颖性的定义
- 推荐系统中的新颖性和多样性:评估和改进的信息检索方法
- 通过随机可达性量化推荐系统中的可用性和发现性
- 用于具有高效算法的推荐的全新系统范围多样性测量
- 自动评估推荐系统:覆盖范围、新颖性和多样性
- 意外性:推荐系统中准确性的不受欢迎的最佳伙伴