深度学习在推荐系统中的应用:入门指南
现代工业推荐系统背后最重要技术突破的巡回

推荐系统是当今发展最快的工业机器学习应用之一。从商业角度来看,这不足为奇:更好的推荐带来更多的用户。就是这么简单。
然而,底层技术远非简单。自从深度学习的兴起——得益于GPU的商品化——推荐系统变得越来越复杂。
在本文中,我们将回顾过去十年最重要的几个建模突破,粗略地重建标志着深度学习在推荐系统中兴起的关键点。这是一个关于技术突破、科学探索和跨越大陆和合作的军备竞赛的故事。
系好安全带。我们的巡回从2017年的新加坡开始。
NCF (新加坡大学,2017年)
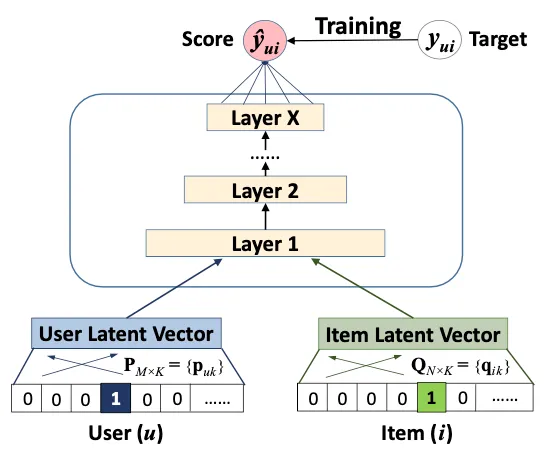
任何有关推荐系统中深度学习的讨论都不完整,没有提到该领域最重要的突破之一——神经协同过滤(NCF),该技术由新加坡大学的He et al(2017)提出。
在NCF之前,推荐系统的黄金标准是矩阵分解,在其中,我们为用户和物品学习潜在向量(即嵌入),然后通过用户向量和物品向量的点积来生成用户的推荐。正如我们从线性代数中知道的那样,点积越接近1,预测匹配就越好。因此,矩阵分解可以简单地视为潜在因素的线性模型。
NCF中的关键思想是用神经网络替换矩阵分解中的内积。在实践中,这是通过首先将用户和物品嵌入进行串联,然后将它们传递到具有单一任务头的多层感知器(MLP)中来完成的,该任务头预测用户参与度,例如点击。在模型训练期间,通过损失梯度的反向传播来学习MLP权重和嵌入权重(将ID映射到它们各自的嵌入)。
NCF背后的假设是用户/物品之间的相互作用不是线性的,如矩阵分解所假设的那样,而是非线性的。如果是这样,当我们向MLP中添加更多层时,我们应该看到更好的性能。而这正是He等人发现的。通过4层,他们能够击败当时Movielens和Pinterest基准数据集上最好的矩阵分解算法约5%的命中率。
He等人证明了深度学习在推荐系统中的巨大价值,标志着从矩阵分解向深度推荐器的关键转变。
Wide & Deep (Google, 2016年)
我们的巡回从新加坡继续到加利福尼亚州的山景城。
虽然NCF革命了推荐系统领域,但它缺少一个被证明对推荐器成功非常重要的重要因素:交叉特征。交叉特征的概念在Google的2016年论文“宽度和深度学习用于推荐系统”中得到普及。
什么是交叉特征?它是通过“交叉”两个原始特征而创建的二阶特征。例如,在Google Play商店中,一阶特征包括印象应用程序或用户安装的应用程序列表。这两个可以组合成强大的交叉特征,例如
AND(user_installed_app='netflix', impression_app='hulu')如果用户已安装 Netflix 应用程序并且被展示的应用程序是 Hulu,则为1。
交叉特征也可以更加普遍化,例如
AND(user_installed_category='video', impression_category='music')等等。作者认为,添加不同粒度的交叉特征可以同时实现记忆(来自更精细的交叉)和泛化(来自较不精细的交叉)。
Wide&Deep 的关键架构选择是同时拥有宽模块和深模块。宽模块是一个线性层,直接将所有交叉特征作为输入,而深模块则本质上是一个 NCF。然后将两个模块组合成一个单一的输出任务头,从用户/应用程序参与中学习。
实际上,Wide&Deep 的效果非常好:作者发现从仅使用深层到使用宽模块和深层时,在线应用获取方面提高了1%。考虑到 Google 每年从其 Play Store 获得数十亿美元的收入,很容易看出 Wide&Deep 的影响。
DCN(Google,2017)
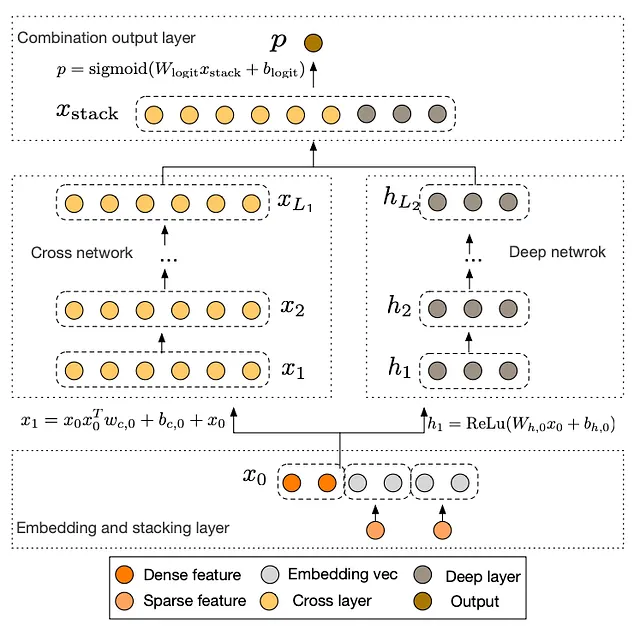
Wide&Deep已经证明了交叉特征的重要性,但是它有一个巨大的缺点:交叉特征需要手动设计,这是一项繁琐的过程,需要工程资源、基础设施和领域专业知识。Wide&Deep 类型的交叉特征非常昂贵,不具有可扩展性。
因此,谷歌在2017年推出了“深度和交叉神经网络”(DCN)。DCN的关键思想是用“交叉神经网络”替换Wide&Deep中的宽组件,这是一个专门用于学习任意高阶交叉特征的神经网络。
交叉神经网络与标准MLP的区别在哪里?提醒一下,在MLP中,下一层中的每个神经元都是前一层中所有神经元的线性组合:
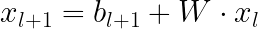
相比之下,在交叉神经网络中,下一层是由第一层自身形成的二阶组合构建的:
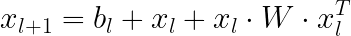
因此,深度为 L 的交叉神经网络将学习以下形式的交叉特征的多项式度数高达L。神经网络越深,学习的高阶交互作用就越多。
实验证实了DCN的有效性。与仅使用深层组件的模型相比,DCN在Criteo展示广告基准数据集上具有0.1%更低的对数损失(被认为具有统计学意义)。而且这是没有像 Wide&Deep 那样进行任何手动特征工程的情况下实现的!
(很遗憾,我们没有看到DCN和Wide&Deep之间的比较。不幸的是,DCN的作者没有好的方法手动创建Criteo数据集的交叉特征,因此跳过了这个比较。)
DeepFM(华为,2017)
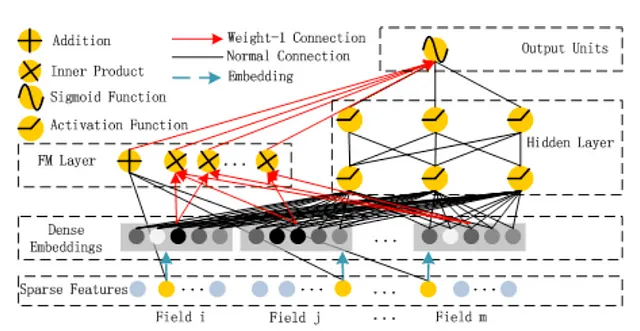
接下来,我们的旅程从2017年的谷歌转向2017年的华为。华为的深度推荐解决方案“DeepFM”也使用了专用神经网络学习交叉特征,取代了 Wide&Deep 中宽组件中的手动特征工程,但与 DCN 不同的是,宽组件不是交叉神经网络,而是所谓的 FM(“因子分解机”)层。
FM层是做什么的?它只是计算所有嵌入对的点积。例如,如果一个电影推荐器将4个id特征作为输入,比如用户id、电影id、演员id和导演id,那么模型会为所有这些id特征学习嵌入,FM层会计算6个点积,分别对应于用户-电影、用户-演员、用户-导演、电影-演员、电影-导演和演员-导演的组合。它是矩阵分解思想的回归。FM层的输出然后与深度组件的输出结合成一个sigmoid激活的输出,得出模型的预测。
事实上,正如你可能已经猜到的那样,DeepFM已经被证明是有效的。作者展示了DeepFM在公司内部数据上比一系列竞争对手(包括Google的Wide&Deep)在AUC和Logloss方面分别高出0.37%和0.42%。
DLRM(Meta,2019)
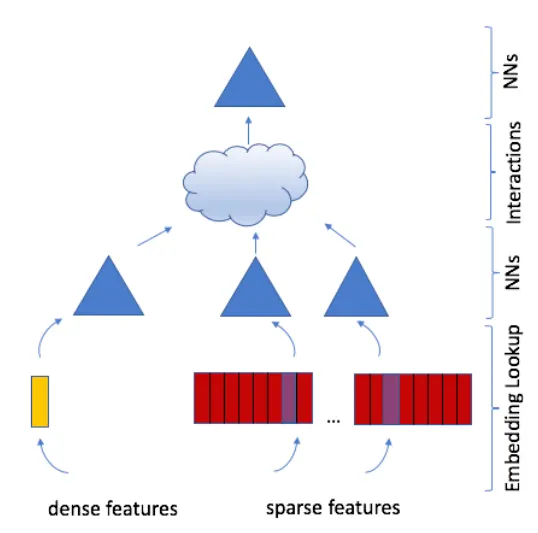
现在,让我们暂时放下Google和华为。我们旅行的下一站是2019年的Meta。
Meta的DLRM(“用于推荐系统的深度学习”)架构,在Naumov et al(2019)中介绍,其工作方式如下:所有分类特征都使用嵌入表转换为嵌入。所有密集特征都被传递到一个MLP中,该MLP为它们计算嵌入。重要的是,所有嵌入具有相同的维度。然后,我们简单地计算所有嵌入对的点积,将它们连接成一个单一的向量,并通过一个最终的MLP传递该向量,该MLP具有一个sigmoid激活的任务头,产生预测。
因此,DLRM几乎是DeepFM的简化版本:如果您采用DeepFM并丢弃深度组件(仅保留FM组件),则会得到类似DLRM的东西,但没有DLRM的密集MLP。
在实验中,Naumov等人展示DLRM在Criteo显示广告基准数据集上的训练和验证准确性都超过了DCN。这个结果表明,在DCN中,深度组件可能确实是多余的,而我们真正需要的只是特征交互,在DLRM中,这些特征交互是通过点积捕捉的。
DHEN(Meta,2022)
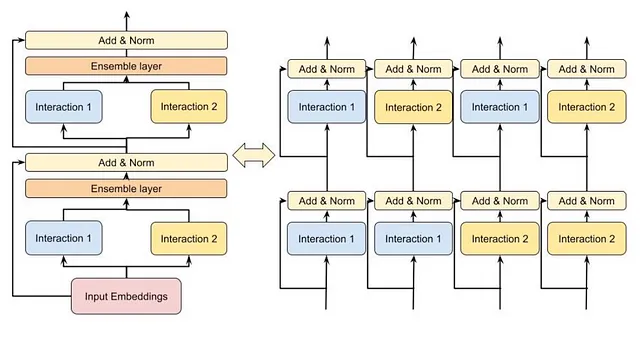
与DCN相比,DLRM中的特征交互仅限于二阶:它们只是所有嵌入对的点积。回到电影的例子(具有用户、电影、演员和导演功能),二阶交互将是用户-电影、用户-演员、用户-导演、电影-演员、电影-导演和演员-导演。三阶交互将是用户-电影-导演、演员-演员-用户、导演-演员-用户等。某些用户可能是史蒂文·斯皮尔伯格执导的汤姆·汉克斯电影的粉丝,因此应该有一个交叉特征!不幸的是,在标准的DLRM中,没有。这是一个重要限制。
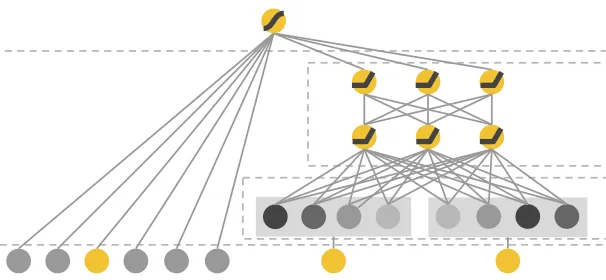
DHEN是我们现代推荐系统之旅中的最后一个重要论文。DHEN代表“深度分层集成网络”,其关键思想是创建一个交叉特征的“层次结构”,随着DHEN层数的增加而变得更深。
首先,我们用一个简单的例子来理解DHEN。假设我们将两个输入特征传入DHEN,让我们用A和B来表示它们(例如,它们可以代表用户id和视频id)。一个2层DHEN模块将创建所有二阶交叉特征的层次结构,即:
A,AxA,AxB,B,BxB,其中,“x”可以是以下5种交互之一或其组合:
- 点积,
- 自注意力,
- 卷积,
- 线性:y = Wx,或
- DCN中的交叉模块。
DHEN非常强大,由于其递归性质,计算复杂度非常高。为了使其正常工作,DHEN论文的作者不得不发明一种新的分布式训练范式,称为“混合分片数据并行”,其吞吐量比当时的最先进技术高出1.2倍。
但最重要的是,这个强大的模型是有效的:在他们对内部点击率数据进行的实验中,作者使用8层DHEN堆叠相较于DLRM,测量出0.27%的NE提升。
总结
这就是我们的导览的结尾。让我用一句标题总结每一个里程碑:
- NCF : 我们只需要用户和项目的嵌入。MLP会处理其余部分。
- 宽&深 : 交叉特征很重要。实际上,它们非常重要,我们直接将它们馈送到任务头中。
- DCN :交叉特征很重要,但不应手动设计。让交叉神经网络处理。
- DeepFM :让我们在FM层中生成交叉特征,仍然保留来自宽&深的深层组件。
- DRLM :FM就是我们需要的-还有另一个专门用于密集特征的MLP。
- DHEN :FM不够。我们需要一个更高阶(超过二阶)的层次特征交互层次结构。还要进行一堆优化才能使其在实践中起作用。
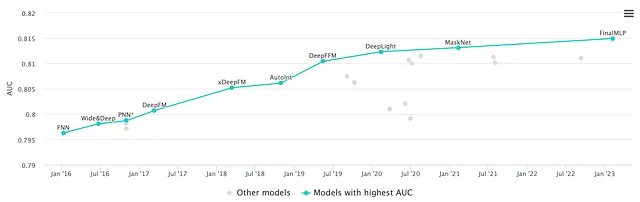
而旅程真的只是刚刚开始。在撰写本文时,DCN已经发展成为DCN-M,DeepFM已经发展为xDeepFM,Criteo竞赛排行榜已经被华为的最新发明FinalMLP所占领。
考虑到更好的推荐所带来的巨大经济激励,我们保证会在可预见的未来持续看到这个领域的新突破。敬请关注。