可视化维度诅咒的真实程度
使用蒙特卡洛方法来可视化具有大量特征的观测行为
想象一个数据集,由一些观测组成,每个观测具有N个特征。如果将所有特征转换为数值表示,可以说每个观测是N维空间中的一个点。
当N较低时,点之间的关系符合直觉。但是有时N会变得非常大——例如,如果通过独热编码等方式创建了许多特征。对于非常大的N值,观测行为就像它们是稀疏的,或者它们之间的距离比你期望的要大。
这种现象是真实存在的。随着维度数量N的增长,其他条件保持不变,包含观测的N体积确实在某种意义上增加了(或者至少自由度的数量变得更大),观测之间的欧几里得距离也增加了。实际上,点的集合确实变得更稀疏。这是维度诅咒的几何基础。数据集上应用的模型和技术的行为会受到这些变化的影响。
如果特征数量非常大,许多问题可能会出现。特征数量超过观测数量是模型在训练过程中过拟合的典型设置。在这样的空间中进行任何暴力搜索(例如网格搜索)变得不那么高效,需要更多的试验来覆盖任何轴向的相同区间。对基于距离或邻近性的任何模型都有一个微妙的影响:随着维度数量增长到一些非常大的值,如果你考虑观测中的任何一个点,所有其他点似乎都离得很远,并且几乎等距离分布——由于这些模型依赖距离来完成工作,距离的差异变得平坦化,使它们的工作变得更困难。例如,如果所有点看起来几乎等距离,聚类效果就不会那么好。
出于种种原因,为了摆脱具有非常多维度的特殊空间的几何特性,并将数据集简化为与实际信息相容的维度数量,诸如PCA、LDA等技术已经被创建出来。
直观地感知这种现象的真正规模很困难,超过3个维度的空间极具挑战性,因此让我们进行一些简单的二维可视化来帮助我们的直觉。这个问题的几何基础是维度性可能成为问题的原因,这就是我们将在这里进行可视化的内容。如果你以前没有见过这个,结果可能会让你感到惊讶——高维空间的几何结构比典型的直觉所建议的要复杂得多。
体积
考虑一个边长为1、位于原点中心的正方形。在正方形内部,你可以内切一个圆。
这是2维情况下的设置。现在考虑一般的N维情况。在3维中,你有一个内切于一个立方体的球体。除此之外,你有一个内切于一个N维立方体的N维球体,这是最一般的方式。为了简单起见,我们将称这些对象为“球体”和“立方体”,不管它们有多少维。
立方体的体积是固定的,总是1。问题是:随着维度数量N的变化,球体的体积会发生什么变化?
让我们通过蒙特卡洛方法来实验性地回答这个问题。我们将生成大量均匀但随机分布在立方体内部的点。对于每个点,我们计算它到原点的距离——如果该距离小于0.5(球体的半径),则该点在球体内部。

如果我们将球体内部的点数除以总点数,那将近似于球体体积与立方体体积的比率。由于立方体的体积为1,这个比率将等于球体的体积。当总点数很大时,近似度会变得更好。
换句话说,比率 inside_points / total_points 将近似于球体的体积。
代码相当简单。由于我们需要许多点,必须避免使用显式循环。我们可以使用NumPy,但它只能在CPU上单线程运行,所以速度会很慢。其他可行的选择:CuPy(GPU)、Jax(CPU或GPU)、PyTorch(CPU或GPU)等。我们将使用PyTorch —— 但是NumPy代码看起来几乎相同。
如果你按照嵌套的 torch 语句,我们会生成1亿个随机点,计算它们到原点的距离,计算在球内的点的数量,并将该数量除以总点数。数组 ratio 最终将包含不同维度下的球体体积。
可调参数是针对具有24 GB内存的GPU设置的 —— 如果您的硬件不同,请进行调整。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 强制使用CPU# device = 'cpu'# 如果太多的比率值为0.0,则减小d_maxd_max = 22# 如果内存不足,请减小n的值n = 10**8ratio = np.zeros(d_max)for d in tqdm(range(d_max, 0, -1)): torch.manual_seed(0) # 将大的张量语句组合以获得更好的内存分配 ratio[d - 1] = ( torch.sum( torch.sqrt( torch.sum(torch.pow(torch.rand((n, d), device=device) - 0.5, 2), dim=1) ) <= 0.5 ).item() / n )# 清理内存torch.cuda.empty_cache()让我们可视化结果:

N=1 是平凡的:无论是“球体”还是“立方体”都只是线性段,它们是相等的,所以“球体”的“体积”为1。对于N=2和N=3,您应该记住高中几何学的结果,并注意到这个模拟与精确值非常接近。
但随着N的增加,发生了非常戏剧性的事情:球体的体积像石头一样下降。当N=10时,它已经接近0,当N=20左右时,它已经低于此模拟的浮点精度。在那之后,代码计算球体的体积为0.0(它只是一个近似值)。
>>> print(list(ratio))[1.0, 0.78548005, 0.52364381, 0.30841056, 0.16450286, 0.08075666, 0.03688062, 0.015852, 0.00645304, 0.00249584, 0.00092725, 0.00032921, 0.00011305, 3.766e-05, 1.14e-05, 3.29e-06, 9.9e-07, 2.8e-07, 8e-08, 3e-08, 2e-08, 0.0]对于较大的N值,几乎整个立方体的体积都位于角落。包含球体的中心区域相对不重要。在高维空间中,角落变得非常重要。大部分体积“迁移到”角落。随着N的增加,这种情况发生得非常快。
另一种看待它的方式:球体是原点的“附近”。随着N的增加,点会从附近消失。原点并不是那么特别,所以它的附近发生的事情也会发生在任何地方的附近。“附近”这个概念发生了很大的变化。随着N的增加,附近的空间变得空荡荡。
几年前我第一次运行这个模拟,我清楚地记得这个结果是多么令人震惊 —— 当N增加时,球体的体积迅速下降到0。在检查代码并没有找到任何错误之后,我的反应是:保存工作、锁定屏幕、出去走走,思考一下你刚刚看到的东西。 🙂
线性距离
让我们根据N计算立方体的对角线。这很简单,因为对角线就是sqrt(N),所以代码非常简单, 这里不包括代码。这是结果:
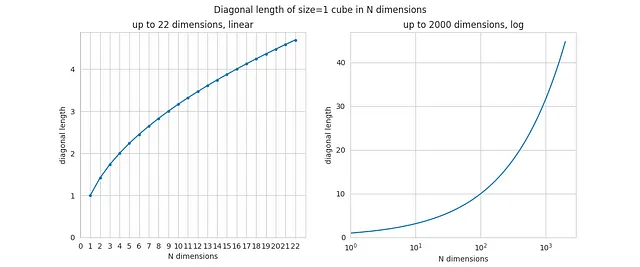
同样的,对于N=2和N=3,你应该从几何学中认识到这些结果(正方形和普通3维立方体的对角线)。但是随着N的增加,对角线也增加,并且它的增长是无限的。
这听起来可能很不直观,但是即使立方体的边长保持不变(等于1),其对角线也可以随着N的增加而无限增长。对于N=1000,对角线长度约为32。理论上,如果立方体的边长为1米,那么在非常多的维度空间中,立方体的对角线将是1千米!
即使边长保持不变,对角线随着维度的增加而不断增长。
每次向空间添加一个新的维度,就会增加更多的边、面等,角区域的配置变得更复杂,自由度更多,对角线会变长一点。
观测点之间的距离
那么观测点或者数据点之间的距离呢?假设我们生成了一定数量的随机点,然后计算任意两个点之间的平均距离,以及任意点最近邻的平均距离。所有的点都始终包含在立方体中。随着N的增加,平均距离会发生什么变化呢?让我们运行另一个模拟。
请注意对内存管理的保守态度。这很重要,因为这里使用的数据结构非常大。
n_points_d = 10**3# 有多少对点存在dist_count = n_points_d * (n_points_d - 1) / 2# 我们使用完整的两两距离矩阵,所以每个距离会被计算两次dist_count = 2 * dist_countd_max = d_max_diagavg_dist = np.zeros(d_max)avg_dist_nn = np.zeros(d_max)for d in tqdm(range(d_max, 0, -1)): torch.manual_seed(0) # 生成随机点 point_coordinates = torch.rand((n_points_d, d), device=device) # 计算所有轴上的点坐标差异 coord_diffs = point_coordinates.unsqueeze(1) - point_coordinates del point_coordinates # 对坐标差异进行平方 diffs_squared = torch.pow(coord_diffs, 2) del coord_diffs # 计算任意两个点之间的距离 distances_full = torch.sqrt(torch.sum(diffs_squared, dim=2)) del diffs_squared # 计算点之间的平均距离 avg_dist[d - 1] = torch.sum(distances_full).item() / dist_count # 计算到最近邻的距离 distances_full[distances_full == 0.0] = np.sqrt(d) + 1 distances_nn, _ = torch.min(distances_full, dim=0) del distances_full # 计算到最近邻的平均距离 avg_dist_nn[d - 1] = torch.mean(distances_nn).item() del distances_nntorch.cuda.empty_cache()这里我们使用的点要少得多(只有1000个),因为主要数据结构的大小随N^2增加,所以如果我们生成太多的点,内存很快就会用完。即便如此,近似结果应该足够接近实际值。
这是作为N函数的一部分,任意两个点之间的平均距离:
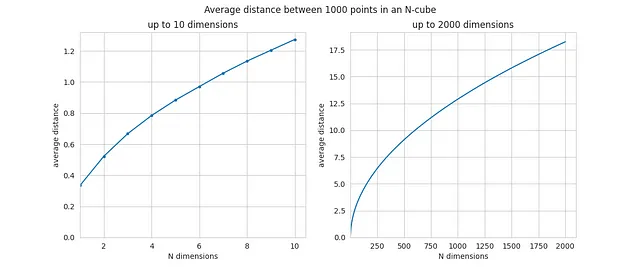
对于较小的N值,平均距离大约为0.5或1。但是随着N的增加,平均距离开始增加,当N=2000时,平均距离已经接近18。增长是显著的。
这是最近邻平均距离的函数:
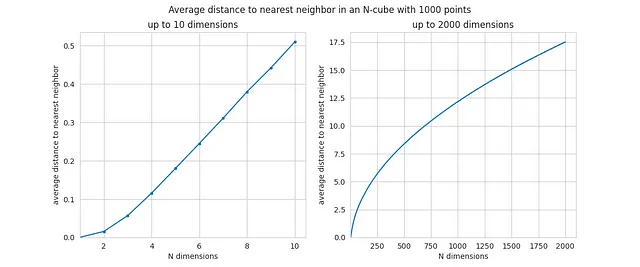
在这里,增加是更加明显的,因为当 N 小于 10 时,值非常小,点在低维空间中密集在一起。对于大的 N 值,最近邻平均距离实际上接近于任意两点之间的平均距离 — 换句话说,周围的空白区域主导了测量结果。
这就是为什么我们在开始时说高维空间中的点几乎等距 — 平均距离和最短距离几乎相同。这里有来自模拟的证据,以及对这种现象的直觉。
随着维度数量 N 的增加,所有点相互远离,尽管它们的坐标被限制在同一个狭窄的范围内(-0.5,+0.5)。通过简单地创建更多维度,点的组合变得越来越稀疏。当维度从几个单位增加到几千个单位时,增加跨越了几个数量级。这是一个非常大的增加。
结论
维数诅咒是一个真实的现象。其他条件相同,当增加维数(或特征)的数量时,点(或观察结果)将迅速相互远离。实际上,空间中有更多的空间,尽管沿轴线的线性间隔是相同的。所有邻近区域都变为空白,每个点最终都独自位于高维空间中。
这应该对一些技术(聚类、各种模型等)在特征数量发生重大变化时表现出不同行为提供一些直觉。少量观察结果与大量特征结合可能会导致次优的结果 — 维数诅咒并非唯一原因,但可能是其中之一。
一般来说,观察结果的数量应当“跟上”特征的数量 — 具体规则取决于许多因素。
如果没有其他,这篇文章应该提供了关于难以可视化的高维空间属性的直观概述。一些趋势是令人震惊的强烈,现在您应该对它们的强度有一些概念了。
本文中使用的所有代码在此处:
misc/curse_dimensionality_article/n_sphere.ipynb at master · FlorinAndrei/misc
随机内容。通过在 GitHub 上创建一个帐户,为 FlorinAndrei/misc 做出贡献。
github.com
本文中使用的所有图像均由作者创建(请参见上面的代码链接)。






