使用Amazon SageMaker Canvas,无需编码即可快速捕获公共卫生洞察
公共卫生机构拥有大量关于不同类型疾病、健康趋势和危险因素的数据。他们的工作人员长期以来一直使用统计模型和回归分析来做出重要决策,例如针对具有疾病最高危险因素的人群进行治疗,或预测令人担忧的爆发病情的进展。
当公共卫生威胁出现时,数据速度增加,传入数据集可能变得更大,数据管理变得更具挑战性。这使得全面分析数据并从中获取见解变得更加困难。而且在时间紧迫的情况下,分析数据并从中得出见解的速度和灵活性是形成快速和强大的健康应对措施的关键阻碍。
在紧张时期,公共卫生机构面临的典型问题包括:
- 某个地点是否有足够的治疗方法?
- 哪些危险因素推动了健康结果?
- 哪些人群更容易再次感染?
因为回答这些问题需要理解许多不同因素之间复杂的关系,这些因素经常变化和动态,我们可以利用的一个强大工具是机器学习(ML),它可以用于分析、预测和解决这些复杂的定量问题。我们越来越多地看到ML应用于解决困难的与健康相关的问题,如使用图像分析对脑瘤进行分类和预测需要提前介入计划的心理健康需求。
但是,如果公共卫生机构缺乏应用ML所需的技能,那么ML对公共卫生问题的应用就会受阻,公共卫生机构将失去应用强大定量工具解决挑战的能力。
那么我们如何消除这些瓶颈呢?答案是民主化ML,允许更多具有深厚领域专业知识的卫生专业人员使用它并将其应用于他们想要解决的问题。
Amazon SageMaker Canvas是一个无代码的ML工具,它赋予了公共卫生专业人员(如流行病学家、信息学家和生物统计学家)使用ML的能力,而不需要数据科学背景或ML专业知识。他们可以把时间花在数据上,应用他们的领域专业知识,快速测试假设,并量化见解。Canvas通过民主化ML帮助使公共卫生更加公平,允许卫生专家评估大型数据集,并利用ML获得高级见解。
在本文中,我们展示了公共卫生专家如何使用Canvas对未来30天某种治疗方法的需求进行预测。Canvas提供了一个可视界面,让您可以自己生成准确的ML预测,而不需要任何ML经验或编写一行代码。
解决方案概述
假设我们正在处理从美国各州收集的数据。我们可能形成一个假设,即某个市政当局或地点在未来几周内没有足够的治疗方法。我们如何快速测试并以高度准确性进行预测?
在本文中,我们使用美国卫生与人类服务部提供的公开可用数据集。该数据集包含与COVID-19相关的州级时间序列数据,包括医院利用率、某些治疗方法的可用性等等。该数据集(COVID-19报告的患者影响和州内医院容量时间序列(原始))可从healthdata.gov下载,包含135个列和超过60000行。该数据集定期更新。
在接下来的几节中,我们将演示如何进行探索性数据分析和准备工作,构建ML预测模型,并使用Canvas生成预测。
进行探索性数据分析和准备
在Canvas中进行时间序列预测时,我们需要根据服务配额减少特征或列的数量。最初,我们将将列数减少到最有可能相关的12列。例如,我们放弃了特定年龄的列,因为我们希望预测总需求。我们还删除了其数据与我们保留的其他列相似的列。在以后的迭代中,尝试保留其他列并使用Canvas中的特征解释性来量化这些特征的重要性以及我们想要保留的特征是合理的。我们还将state列重命名为location。
查看数据集时,我们还决定删除所有2020年的行,因为那个时候治疗方法有限。这样可以减少噪音,提高ML模型学习的数据质量。
可以通过不同的方式减少列数。您可以在电子表格中编辑数据集,或直接在Canvas中使用用户界面进行编辑。
您可以从各种来源导入数据到Canvas中,包括从您的计算机中的本地文件,Amazon Simple Storage Service(Amazon S3)存储桶,Amazon Athena,Snowflake(请参阅使用Snowflake集成准备用于相貌分类的培训和验证数据集,并使用Amazon SageMaker Canvas进行训练),以及其他40多种数据源。
在我们导入数据之后,我们可以探索和可视化数据,以获取更多的见解,例如散点图或条形图。我们还会查看不同特征之间的相关性,以确保我们选择了我们认为最好的特征。以下是一个示例可视化的屏幕截图。
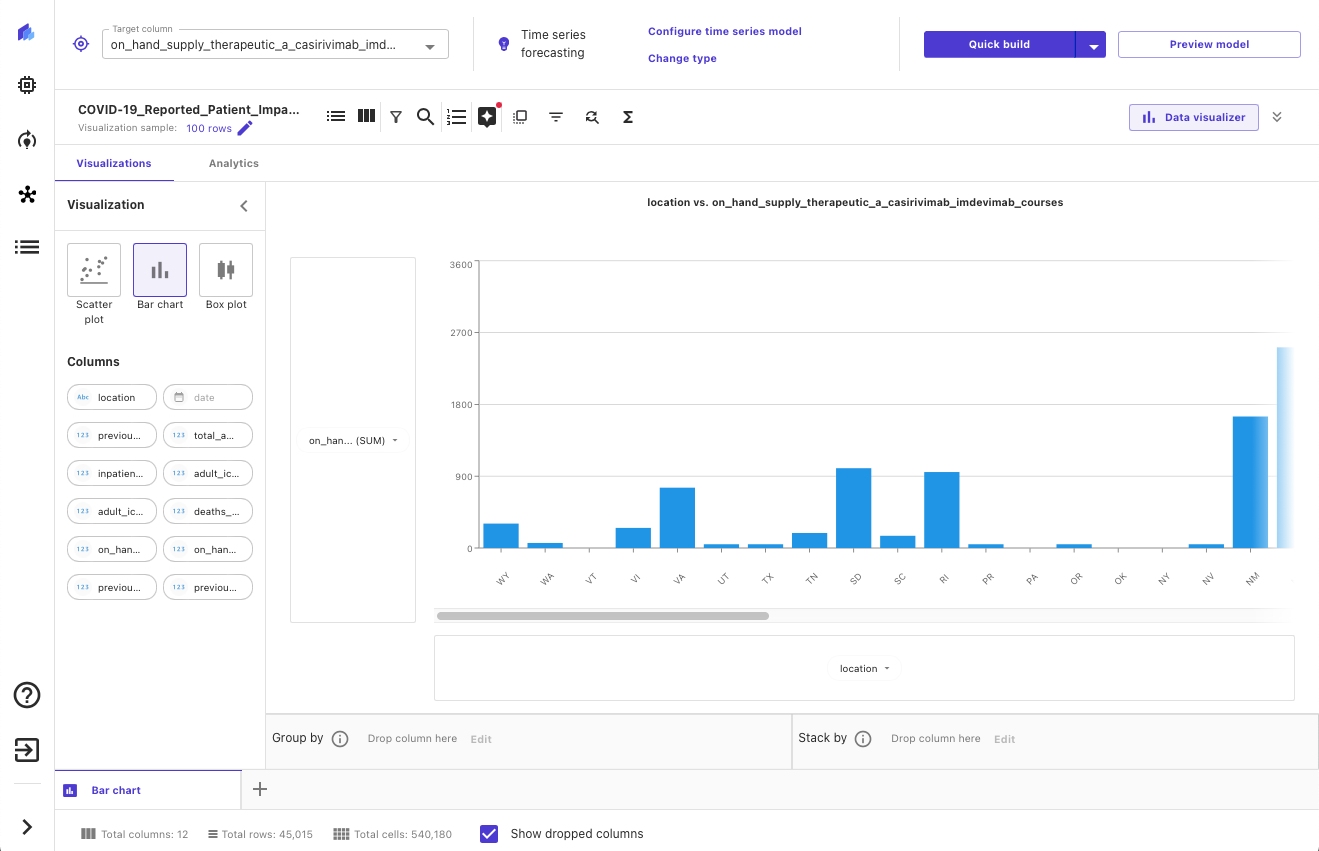
构建ML预测模型
现在我们可以通过只需几次点击来创建我们的模型了。我们选择标识现有治疗方法的列作为目标。Canvas根据我们刚刚选择的目标列自动识别我们的问题为时间序列预测,并且我们可以配置所需的参数。
我们将唯一标识符item_id配置为位置,因为我们的数据集是按位置(美国州)提供的。因为我们正在创建时间序列预测,所以我们需要选择一个时间戳,而在我们的数据集中是date。最后,我们指定我们要预测的未来天数(对于此示例,我们选择30天)。Canvas还提供了包括假日日程表以提高准确性的功能。在这种情况下,我们使用美国假日,因为这是一个基于美国的数据集。
使用Canvas,您可以在构建模型之前从数据中获取见解,只需选择预览模型。这样可以节省时间和成本,如果结果不太可能令人满意,则不需要构建模型。通过预览我们的模型,我们意识到一些列的影响很低,意味着该列对模型的期望值很低。我们通过在Canvas中取消选择这些列(以下屏幕截图中的红色箭头),并看到估计的质量指标有所改善(绿色箭头)来删除列。
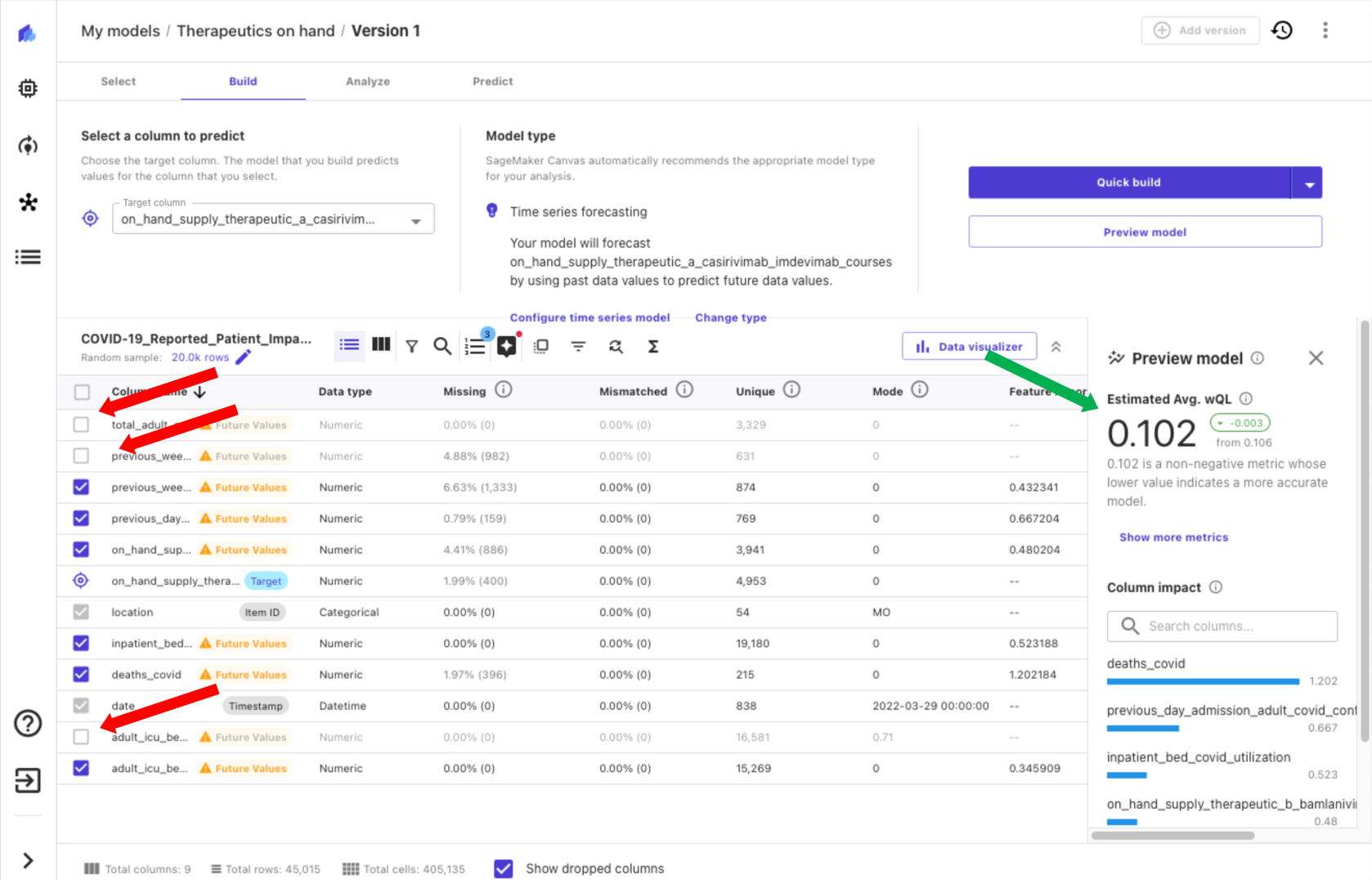
接下来,我们有两个选项来构建我们的模型,快速构建和标准构建。快速构建可以在不到20分钟内生成一个经过训练的模型,优先考虑速度而非准确性。这非常适用于实验,而且比预览模型更全面。标准构建可以在不到4小时内生成一个经过训练的模型,优先考虑准确性而非延迟,并通过多种模型配置来迭代选择最佳模型。
首先,我们使用快速构建来验证我们的模型预览。然后,因为我们对模型满意,我们选择标准构建,让Canvas帮助构建适用于我们的数据集的最佳模型。如果快速构建模型产生了不令人满意的结果,那么我们将返回并调整输入数据,以获得更高水平的准确性。我们可以通过添加或删除原始数据集中的列或行来实现这一点。快速构建模型支持快速实验,无需依赖稀缺的数据科学资源或等待完整的模型完成。
生成预测
现在模型已经构建完成,我们可以预测治疗方法的可用性,按location分类。让我们看看接下来30天内华盛顿特区的预计现有库存情况。
Canvas输出治疗需求的概率预测,让我们了解中值以及上下界。在以下屏幕截图中,您可以看到历史数据的末尾(来自原始数据集的数据)。然后,您可以看到三条新线:中值(50th分位数)预测为紫色,下界(10th分位数)为浅蓝色,上界(90th分位数)为深蓝色。
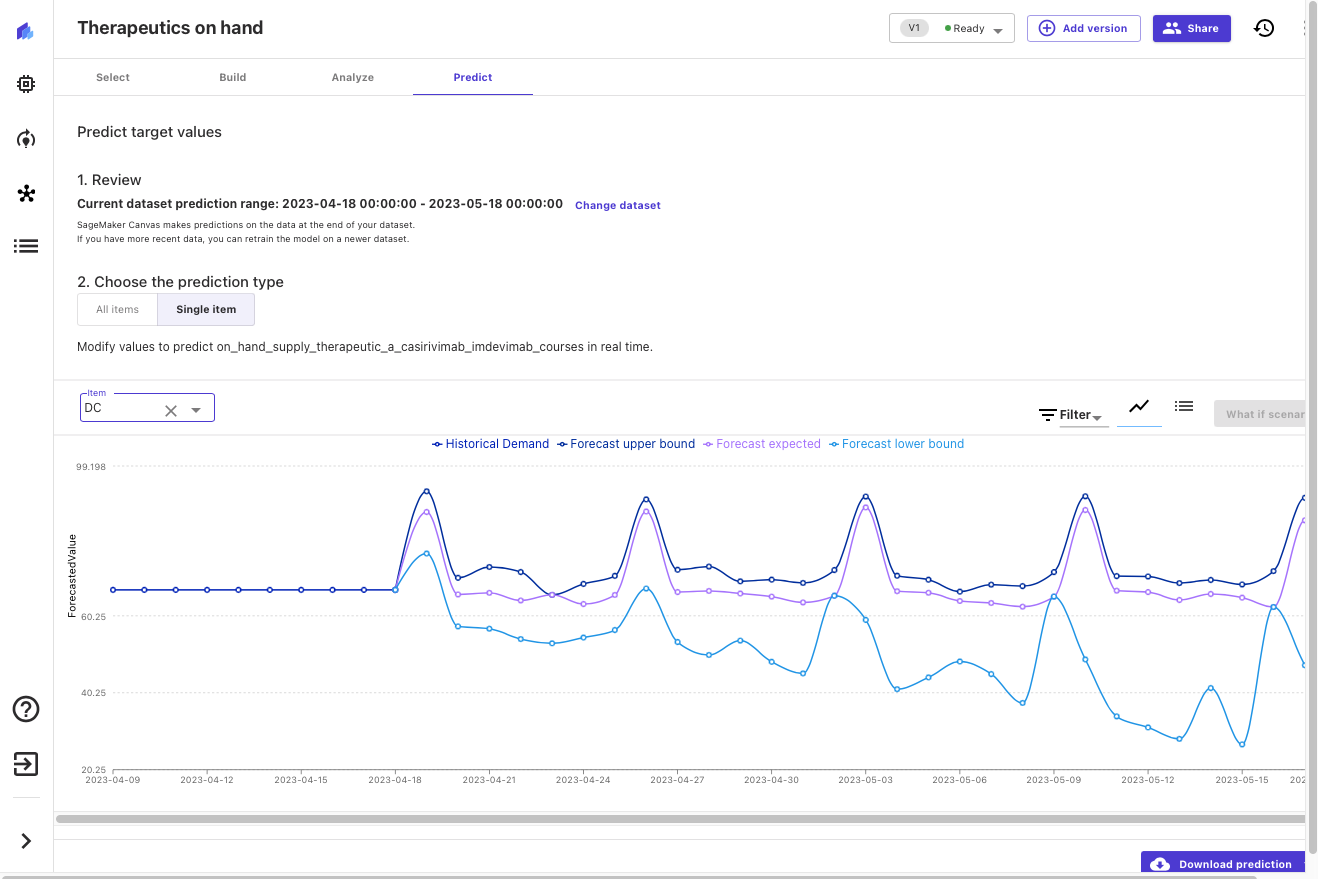
检查上限和下限可以洞察预测的概率分布,并使我们能够对所需的本地库存水平做出明智的决策。我们可以将这种洞察力与其他数据(例如疾病进展预测、治疗效果和接受程度)相结合,以做出关于未来订单和库存水平的明智决策。
结论
无代码机器学习工具使公共卫生专家能够快速有效地应用机器学习来应对公共卫生威胁。这种机器学习的民主化使公共卫生组织在保护公共健康的使命中更加灵活和高效。现在,专家可以直接进行临时分析,识别公共卫生问题中的重要趋势或拐点,而无需竞争有限的机器学习专家资源,从而减慢响应时间和决策过程。
在本文中,我们展示了如何在没有任何机器学习知识的情况下,使用Canvas来预测特定治疗方法的手头库存。通过云技术和无代码机器学习的力量,任何领域的分析师都可以执行此分析。这样做可以广泛分配能力,并使公共卫生机构更具响应性,并更有效地利用集中和外地办事处资源,以实现更好的公共卫生成果。
您可能会问一些问题,低代码/无代码工具如何帮助您回答这些问题?如果您有兴趣了解更多关于Canvas的信息,请参阅Amazon SageMaker Canvas,并开始将机器学习应用于自己的定量健康问题。






