使用Hugging Face Datasets工作
了解如何访问Hugging Face Hub上的数据集,以及如何使用DuckDB和Datasets库远程加载它们
作为一个AI平台,Hugging Face构建、训练和部署最先进的开源机器学习模型。除了托管所有这些训练好的模型,Hugging Face还托管数据集( https://huggingface.co/datasets ),您可以在自己的项目中使用它们。
在本文中,我将向您展示如何访问Hugging Face中的数据集,以及如何以编程方式将它们下载到您的本地计算机上。具体而言,我将向您展示如何:
- 使用DuckDB对httpfs的支持远程加载数据集
- 使用Hugging Face的Datasets库流式传输数据集
Hugging Face数据集服务器
Hugging Face数据集服务器是一个轻量级的Web API,用于可视化存储在Hugging Face Hub上的不同类型的数据集。您可以使用提供的REST API查询存储在Hugging Face Hub上的数据集。下面的部分提供了关于您可以使用位于https://datasets-server.huggingface.co/的API的简短教程。
获取托管在Hub上的数据集列表
要获取可以从Hugging Face检索的数据集列表,请使用以下语句和valid端点:
$ curl -X GET "https://datasets-server.huggingface.co/valid"您将看到如下所示的JSON结果:

可以无错误工作的数据集列在结果中valid键的值中。上面的一个有效数据集示例是0-hero/OIG-small-chip2。
验证数据集
要验证数据集,请使用以下语句和is-valid端点以及dataset参数:
$ curl -X GET "https://datasets-server.huggingface.co/is-valid?dataset=0-hero/OIG-small-chip2"如果数据集有效,您将看到以下结果:
{"valid":true}获取数据集的配置和拆分列表
数据集通常具有拆分(训练集、验证集和测试集)。它们还可以具有配置 – 在更大的数据集内的子数据集。
配置对于多语言语音数据集很常见。有关拆分的更多详细信息,请访问:https://huggingface.co/docs/datasets-server/splits 。
要获取数据集的拆分,请使用以下语句和splits端点以及dataset参数:
$ curl -X GET "https://datasets-server.huggingface.co/splits?dataset=0-hero/OIG-small-chip2"将返回以下结果:
{ "splits": [ { "dataset":"0-hero/OIG-small-chip2", "config":"0-hero--OIG-small-chip2", "split":"train" } ], "pending":[], "failed":[]}对于该数据集,只有一个train拆分。
以下是一个具有多个拆分和配置的数据集(” duorc “)的示例:
{ "splits": [ { "dataset": "duorc", "config": "SelfRC", "split": "训练集", "num_bytes": 239852925, "num_examples": 60721 }, { "dataset": "duorc", "config": "SelfRC", "split": "验证集", "num_bytes": 51662575, "num_examples": 12961 }, { "dataset": "duorc", "config": "SelfRC", "split": "测试集", "num_bytes": 49142766, "num_examples": 12559 }, { "dataset": "duorc", "config": "ParaphraseRC", "split": "训练集", "num_bytes": 496683105, "num_examples": 69524 }, { "dataset": "duorc", "config": "ParaphraseRC", "split": "验证集", "num_bytes": 106510545, "num_examples": 15591 }, { "dataset": "duorc", "config": "ParaphraseRC", "split": "测试集", "num_bytes": 115215816, "num_examples": 15857 } ]}获取前100行
通常,您可能希望检索数据集的子集用于审查目的,而不是下载全部数据。以下语句使用first-rows端点和dataset、config和split参数提取指定数据集的前100行:
$ curl -X GET "https://datasets-server.huggingface.co/first-rows?dataset=0-hero/OIG-small-chip2&config=0-hero--OIG-small-chip2&split=train"JSON结果将返回指定数据集的前100行:
{ "dataset": "0-hero/OIG-small-chip2", "config": "0-hero--OIG-small-chip2", "split": "训练集", "features": [{ "feature_idx": 0, "name": "user", "type": { "dtype": "string", "_type": "Value" } }, { "feature_idx": 1, "name": "chip2", "type": { "dtype": "string", "_type": "Value" } }], "rows": [{ "row_idx": 0, "row": { "user": "我听说拥有一份遗嘱是个好主意。什么是遗嘱?\n\n", "chip2": "遗嘱是一份法律文件,规定了您死后如何分配财产。它还可以指定谁来照顾您可能拥有的任何子女或其他依赖人士。确保您的遗嘱有效和最新是很重要的,因为不同州对遗嘱的法律有所不同。" }, "truncated_cells": [] }, { "row_idx": 1, "row": { "user": "如何找工作?\n\n", "chip2": "找工作的最好方法是制作一份强大的简历和求职信,突出您的技能、经验和资格。您还可以在网上搜索您所在领域的工作机会,或直接联系当地雇主查询可用职位。与同一领域或行业的人们建立联系也有助于找到就业机会。" }, "truncated_cells": [] }, { "row_idx": 2, "row": { "user": "详细描述一个拥有圆顶天花板、柱子和门的豪宅内部阴暗的场景。\n\n", "chip2": "房间呈圆形,地板完全由黑色大理石的方形切割部分组成。墙壁上有大型黑色大理石柱子,顶部有一个高高的圆顶玻璃天花板。房间的远端有一个狭窄的缺口,通向一座带有Mithglin镀板门的宽阔楼梯。" }, "truncated_cells": [] }, { ... }, { "row_idx": 98, "row": { "user": "我需要学会更好地管理我的财务。你能给我什么建议吗?\n\n", "chip2": "更好地管理您的财务的最佳方法之一是制定预算并跟踪您的支出。首先写下所有的收入来源和支出。仔细审查每个项目,确定您可以削减的内容。优先支付需要支付的事项,如租金和水电费,并尽量确保您留出一些钱用于储蓄。此外,为自己设定消费限额可以帮助您保持正确的轨道。最后,定期审查您的预算,确保您在预算目标范围内。" }, "truncated_cells": [] }, { "row_idx": 99, "row": { "user": "详细描述一条山路外面平静的场景,有小树和一块巨石。\n\n", "chip2": "一块巨大的花岗岩巨石,显然是从山脉崎岖的悬崖上在某个遥远的时代掉下来的,靠着铺砌的鹅卵石路旁边。被茂密的小树林环绕着,这块巨石为旅行者提供了一个便利的休息地,可以暂时摆脱旅途的劳累。" }, "truncated_cells": [] }]}获取数据集的切片
您还可以获取数据集的切片。下面的语句使用rows端点和dataset、config、split、offset、length参数提取从第三行开始的指定数据集的三行:
$ curl -X GET "https://datasets-server.huggingface.co/rows?dataset=0-hero/OIG-small-chip2&config=0-hero--OIG-small-chip2&split=train&offset=2&length=3"结果将如下所示:
{ "features": [{ "feature_idx": 0, "name": "user", "type": { "dtype": "string", "_type": "Value" } }, { "feature_idx": 1, "name": "chip2", "type": { "dtype": "string", "_type": "Value" } }], "rows": [{ "row_idx": 2, "row": { "user": "Produce a detailed written description of a gloomy scene inside of a mansion with a domed ceiling, pillars, and a door.\n\n", "chip2": "Circular in shape, the floor is completely made from square-cut sections of black marble. Large, blackened marble pillars line the walls, ending with a domed glass ceiling high overhead. A narrow gap on the far side of the room leads to a sweeping stairwell with a mithglin-plated door beneath it." }, "truncated_cells": [] }, { "row_idx": 3, "row": { "user": "I have a sprained ankle and need to know what I can do to help it heal faster.\n\n", "chip2": "You may want to try some ice therapy, which will help reduce swelling and inflammation. Additionally, you could use an elastic bandage or compression wrap to provide additional support for your ankle. It's also important to stay off of it as much as possible, so that it can heal properly." }, "truncated_cells": [] }, { "row_idx": 4, "row": { "user": "How do you roast a turkey?\n\n", "chip2": "To roast a turkey, start by preheating your oven to 350 degrees F. Place the turkey in a roasting pan, and rub it with butter or olive oil. Sprinkle with salt and pepper, and any other herbs or seasonings you like. Place the turkey in the oven and cook for approximately 20 minutes per pound, or until the internal temperature registers 165 degrees. Once the turkey is cooked, remove it from the oven and let it sit for 10-15 minutes before carving." }, "truncated_cells": [] }]}获取数据集的Parquet文件
虽然Hugging Face Hub中的数据集可以以各种格式(CSV、JSONL等)发布,但Datasets服务器会自动将所有公共数据集转换为Parquet格式。Parquet格式在处理大型数据集时具有显著的性能优势。后面的章节将进行演示。
Apache Parquet是一种旨在支持复杂数据的快速数据处理的文件格式。有关Parquet的更多信息,请阅读我的早期文章:
还在使用CSV保存数据吗?尝试其他选项
学习如何将数据保存为不同格式(CSV、压缩、Pickle和Parquet)以节省存储空间和减少…
towardsdatascience.com
要加载Parquet格式的数据集,请使用以下语句和parquet端点和dataset参数:
$ curl -X GET "https://datasets-server.huggingface.co/parquet?dataset=0-hero/OIG-small-chip2" 上述语句将返回以下JSON结果:
{ "parquet_files": [{ "dataset": "0-hero/OIG-small-chip2", "config": "0-hero--OIG-small-chip2", "split": "train", "url": "https://huggingface.co/datasets/0-hero/OIG-small-chip2/resolve/refs%2Fconvert%2Fparquet/0-hero--OIG-small-chip2/parquet-train.parquet", "filename": "parquet-train.parquet", "size": 51736759 }], "pending": [], "failed": []}特别是url键的值指定了可以下载数据集的位置,该数据集以Parquet格式提供,例如在这个例子中是https://huggingface.co/datasets/0-hero/OIG-small-chip2/resolve/refs%2Fconvert%2Fparquet/0-hero--OIG-small-chip2/parquet-train.parquet。
通过编程方式下载数据集
现在你已经看到了如何使用数据集服务器 REST API,让我们看看如何通过编程方式下载数据集。
在Python中,最简单的方法是使用requests库:
import requestsr = requests.get("https://datasets-server.huggingface.co/parquet?dataset=0-hero/OIG-small-chip2")j = r.json()print(j)json()函数的结果是一个Python字典:
{ 'parquet_files': [ { 'dataset': '0-hero/OIG-small-chip2', 'config': '0-hero--OIG-small-chip2', 'split': 'train', 'url': 'https://huggingface.co/datasets/0-hero/OIG-small-chip2/resolve/refs%2Fconvert%2Fparquet/0-hero--OIG-small-chip2/parquet-train.parquet', 'filename': 'parquet-train.parquet', 'size': 51736759 } ], 'pending': [], 'failed': []}使用这个字典结果,你可以使用列表推导式找到以Parquet格式提供的数据集的URL:
urls = [f['url'] for f in j['parquet_files'] if f['split'] == 'train']urlsurls变量是一个包含训练集数据集URL的列表:
['https://huggingface.co/datasets/0-hero/OIG-small-chip2/resolve/refs%2Fconvert%2Fparquet/0-hero--OIG-small-chip2/parquet-train.parquet']使用DuckDB下载Parquet文件
如果你使用DuckDB,你实际上可以使用DuckDB远程加载数据集。
如果你对DuckDB还不熟悉,你可以从这篇文章中了解基础知识:
使用DuckDB进行数据分析
学习如何使用SQL进行数据分析
levelup.gitconnected.com
首先,确保你已经安装了DuckDB:
!pip install duckdb 然后,创建一个DuckDB实例并安装httpfs:
import duckdbcon = duckdb.connect()con.execute("INSTALL httpfs;")con.execute("LOAD httpfs;")httpfs扩展是一个可加载的扩展,实现了一个允许读取远程/写入远程文件的文件系统。
一旦安装和加载了httpfs,你可以通过使用SQL查询从Hugging Face Hub加载Parquet数据集:
con.sql(f''' SELECT * from '{urls[0]}'''').df()上面的df()函数将查询结果转换为Pandas DataFrame:

Parquet的一个很棒的特性是它以列格式存储文件。因此,如果你的查询只请求一个列,那么只有这个请求的列会被下载到你的计算机上:
con.sql(f''' SELECT "user" from '{urls[0]}'''').df()在上述查询中,只下载了“user”列:

这个Parquet功能对于大型数据集特别有用-想象一下仅下载所需列所能节省的时间和空间。
在某些情况下,您甚至不需要下载数据。考虑以下查询:
con.sql(f''' SELECT count(*) from '{urls[0]}'''').df()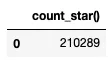
由于可以仅通过读取数据集的元数据来满足此请求,因此不需要下载任何数据。
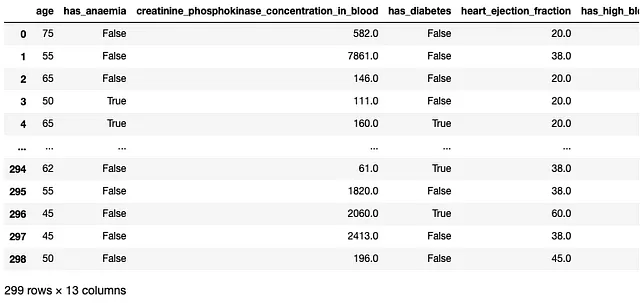
以下是使用DuckDB下载另一个数据集(**“mstz/heart_failure”)的另一个示例:
import requestsr = requests.get("https://datasets-server.huggingface.co/parquet?dataset=mstz/heart_failure")j = r.json()urls = [f['url'] for f in j['parquet_files'] if f['split'] == 'train']con.sql(f''' SELECT "user" from '{urls[0]}'''').df()此数据集共有299行和13列:
我们可以对age列进行一些聚合:
con.sql(f""" SELECT SUM(IF(age<40,1,0)) AS 'Under 40', SUM(IF(age BETWEEN 40 and 49,1,0)) AS '40-49', SUM(IF(age BETWEEN 50 and 59,1,0)) AS '50-59', SUM(IF(age BETWEEN 60 and 69,1,0)) AS '60-69', SUM(IF(age BETWEEN 70 and 79,1,0)) AS '70-79', SUM(IF(age BETWEEN 80 and 89,1,0)) AS '80-89', SUM(IF(age>89,1,0)) AS 'Over 89', FROM '{urls[0]}'""").df()这是结果:

使用结果,我们还可以绘制柱状图:
con.sql(f""" SELECT SUM(IF(age<40,1,0)) AS 'Under 40', SUM(IF(age BETWEEN 40 and 49,1,0)) AS '40-49', SUM(IF(age BETWEEN 50 and 59,1,0)) AS '50-59', SUM(IF(age BETWEEN 60 and 69,1,0)) AS '60-69', SUM(IF(age BETWEEN 70 and 79,1,0)) AS '70-79', SUM(IF(age BETWEEN 80 and 89,1,0)) AS '80-89', SUM(IF(age>89,1,0)) AS 'Over 89', FROM '{urls[0]}'""").df().T.plot.bar(legend=False)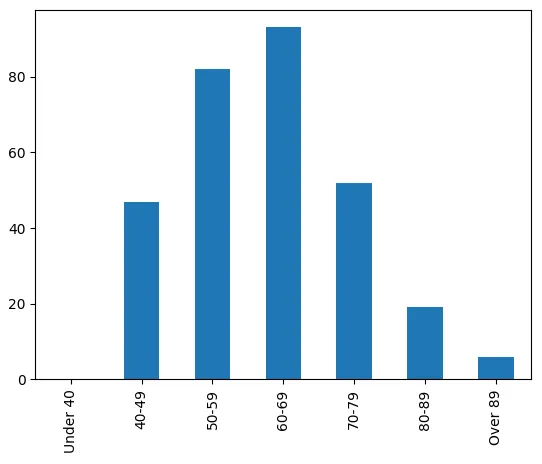
使用Datasets库
为了使与Hugging Face的数据工作变得简单高效,Hugging Face有自己的Datasets库(https://github.com/huggingface/datasets)。
要安装datasets库,请使用pip命令:
!pip install datasetsload_dataset()函数加载指定的数据集:
from datasets import load_datasetdataset = load_dataset('0-hero/OIG-small-chip2', split='train')第一次加载数据集时,整个数据集(以Parquet格式)将被下载到您的计算机上:

返回的dataset的数据类型为datasets.arrow_dataset.Dataset。那么您可以用它做什么呢?首先,可以将其转换为Pandas DataFrame:
dataset.to_pandas()
您还可以通过使用索引来获取数据集的第一行:
dataset[0]这将返回数据的第一行:
{ 'user': "我听说拥有一份遗嘱是个好主意。什么是遗嘱?\n\n", 'chip2': "遗嘱是一份法律文件,规定了您死后财产应如何分配。它还可以指定谁应该照顾您可能有的任何子女或其他依赖人员。确保您的遗嘱有效和及时更新非常重要,因为不同州对遗嘱的法律规定各不相同。"}还有许多其他可以使用这个datasets.arrow_dataset.Dataset对象做的事情。我将让您自行探索。
流式处理数据集
再次提醒,在处理大型数据集时,在进行任何操作之前将整个数据集下载到计算机上是不可行的。在前一节中,调用load_dataset()函数会将整个数据集下载到我的计算机上:

这个特定的数据集占用了82.2MB的磁盘空间。您可以想象需要更大数据集时所需的时间和磁盘空间。
幸运的是,Datasets库支持流式处理。数据集流式处理使您可以在不下载数据集的情况下使用数据集-当您迭代遍历数据集时,数据会以流式方式传输。要使用流式处理,在load_dataset()函数中将streaming参数设置为True:
from datasets import load_datasetdataset = load_dataset('0-hero/OIG-small-chip2', split='train', streaming=True)现在dataset的类型是datasets.iterable_dataset.IterableDataset,而不是datasets.arrow_dataset.Dataset。那么如何使用它呢?您可以对其使用iter()函数,它返回一个iterator对象:
i = iter(dataset)要获取一行数据,调用next()函数,它返回迭代器中的下一项:
next(i)您将看到第一行作为一个字典:
{ 'user': "我听说拥有一份遗嘱是个好主意。什么是遗嘱?\n\n", 'chip2': "遗嘱是一份法律文件,规定了您死后财产应如何分配。它还可以指定谁应该照顾您可能有的任何子女或其他依赖人员。确保您的遗嘱有效和及时更新非常重要,因为不同州对遗嘱的法律规定各不相同。"}在 i 上再次调用 next() 函数将返回下一行:
{ 'user': '如何找工作?\n\n', 'chip2': '找工作的最佳方式是创建一个强大的简历和求职信,突出你的技能、经验和资格。你还可以在你擅长的领域在线搜索工作机会,或直接联系当地雇主了解可用职位。与同行或同行业人士建立人际关系网也有助于找到就业机会。'}等等。
对数据集进行随机化
您还可以通过在 dataset 变量上使用 shuffle() 函数对数据集进行随机化,如下所示:
shuffled_dataset = dataset.shuffle(seed = 42, buffer_size = 500)在上面的示例中,假设您的数据集有 10,000 行。 shuffle() 函数将从缓冲区的前五百行中随机选择示例。
默认情况下,缓冲区大小为 1,000。
其他任务
您可以使用流式处理执行更多任务,例如:
- 拆分数据集
- 交错数据集 – 在每个数据集之间交替行
- 修改数据集的列
- 过滤数据集
请访问 https://huggingface.co/docs/datasets/stream 了解更多详情。
如果您喜欢阅读我的文章,并且它对您的职业/学习有所帮助,请考虑以小猪AI会员的身份注册。每月只需支付 5 美元,即可无限制访问小猪AI上的所有文章(包括我的文章)。如果您使用以下链接注册,我将获得一小笔佣金(您不需要额外支付)。您的支持意味着我将能够投入更多时间撰写这样的文章。
使用我的推荐链接加入小猪AI – 李伟民
作为小猪AI会员,你的会员费的一部分将用于支持你阅读的作家,你将获得对每个故事的完全访问权限…
weimenglee.medium.com
总结
在本文中,我向您展示了如何访问存储在Hugging Face Hub上的数据集。由于数据集存储在Parquet格式中,因此可以远程访问数据集,而无需下载整个数据集的大量数据。您可以使用DuckDB或Hugging Face提供的Datasets库来访问数据集。