苹果研究员推出ByteFormer:一种仅使用字节并不显式地建模输入方式的AI模型


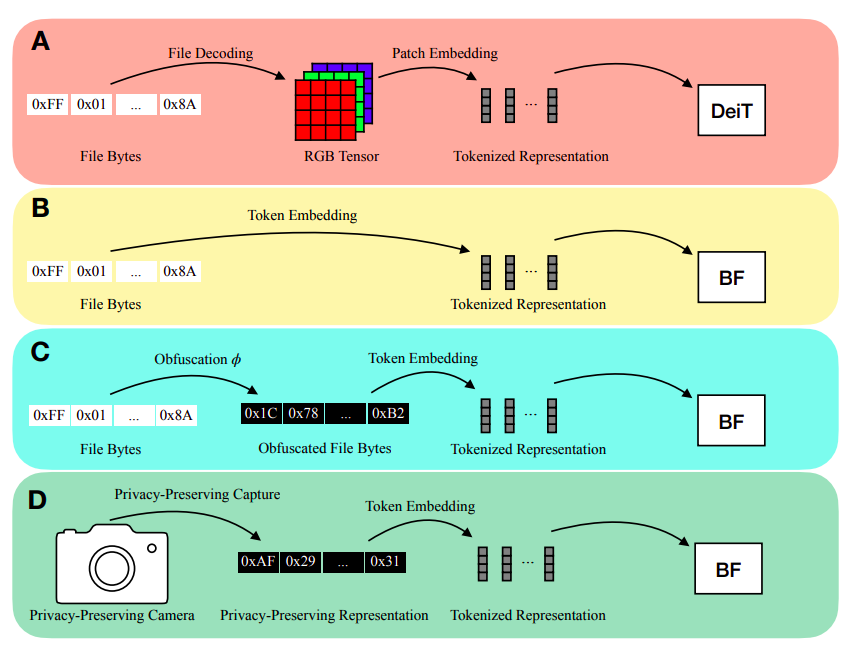
深度学习推理通常需要明确建模输入模态。例如,通过将图片补丁编码为向量,Vision Transformers (ViTs) 直接模拟了图像的二维空间组织。类似地,在音频推理中经常涉及计算频谱特性(如 MFCCs)以传输到网络中。用户必须先将文件解码成模态特定的表示(例如 RGB 张量或 MFCCs),然后才能对保存在磁盘上的文件进行推理(如 JPEG 图像文件或 MP3 音频文件),如图1a所示。将输入解码为模态特定表示有两个实际的缺点。
首先需要为每个输入模态手动创建输入表示和模型干线。最近的项目如 PerceiverIO 和 UnifiedIO 展示了 Transformer 骨干的多功能性。但这些技术仍需要模态特定的输入预处理。例如,在将图片文件发送到网络之前,PerceiverIO 需要将其解码为张量。其他输入模态则由 PerceiverIO 转换为各种形式。他们提出,直接在文件字节上执行推理可行,可以消除所有模态特定的输入预处理。将分析的材料暴露出来是解码输入为模态特定表示的第二个缺点。
想象一下使用 RGB 照片进行推理的智能家居设备。如果敌人获得了这个模型输入的访问权限,用户的隐私可能会受到威胁。他们认为可以在保护隐私的输入上进行推理。他们指出,许多输入模态都具有将其保存为文件字节的能力,以解决这些缺点。因此,他们在推理时将文件字节馈入模型(图1b),而不进行任何解码。鉴于他们处理各种模态和可变长度输入的能力,他们采用了修改后的 Transformer 架构来构建他们的模型。
苹果公司的研究人员介绍了一种称为 ByteFormer 的模型。他们使用存储在 TIFF 格式中的数据展示了 ByteFormer 在 ImageNet 分类上的有效性,达到了 77.33% 的准确率。他们的模型使用了 DeiT-Ti transformer 骨干的超参数,该超参数在 RGB 输入上取得了 72.2% 的准确率。此外,他们在 JPEG 和 PNG 文件上提供了出色的结果。此外,他们展示了在不损失准确性的情况下伪装输入的能力,通过使用置换函数 ϕ : [0, 255] → [0, 255] 重新映射输入字节值来实现(图1c)。尽管这不能确保加密级别的安全性,但他们展示了这种方法可用作掩盖输入进入学习系统的基础。通过使用 ByteFormer 在部分生成的图片上进行推理,可以实现更高的隐私保护(图1d)。他们展示了 ByteFormer 可以训练在有 90% 像素被覆盖的图像上,并在 ImageNet 上达到 71.35% 的准确率。
不需要知道未遮盖像素的精确位置即可使用ByteFormer。通过避免典型的图像捕捉,给予模型的表现确保了匿名性。他们的简要贡献如下:(1)他们创建了一个名为ByteFormer的模型,以对文件字节进行推断。(2)他们证明ByteFormer在几种图片和音频文件编码上表现良好,无需进行架构修改或超参数优化。(3)他们举例说明了ByteFormer如何与保护隐私的输入配合使用。(4)他们研究了ByteFormer的特征,这些特征已经被教给从文件字节中直接分类音频和视觉数据的ByteFormers。(5)他们还在GitHub上发布了他们的代码。