检索增强的视觉语言预训练
作者:胡子牛(Ziniu Hu),学生研究员,法提阿利(Alireza Fathi),研究科学家,Google研究,感知团队
大型模型(例如T5,GPT-3,PaLM,Flamingo和PaLI)已经证明,当它们被缩放到数百亿个参数并在大型文本和图像数据集上进行训练时,它们可以存储大量的知识。这些模型在下游任务上取得了最先进的结果,例如图像字幕,视觉问答和开放词汇识别。尽管取得了这样的成就,但这些模型需要大量的数据进行训练,并且最终会产生大量的参数(在许多情况下为数十亿个),从而需要大量的计算要求。此外,用于训练这些模型的数据可能会变得过时,需要每次更新世界知识时重新训练。例如,仅两年前训练的模型可能会提供关于美国现任总统的过时信息。
在自然语言处理(RETRO,REALM)和计算机视觉(KAT)领域,研究人员尝试使用检索增强模型来解决这些挑战。通常,这些模型使用骨干,该骨干一次只能处理一个模态,例如仅文本或仅图像,以对知识语料库进行编码和检索。但是,这些检索增强模型无法利用查询和知识语料库中所有可用的模态,并且可能无法找到对生成模型输出最有帮助的信息。
为了解决这些问题,在“ REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory”中,即将在CVPR 2023上发布,我们介绍了一种视觉语言模型,该模型学习利用多源多模式的“记忆”来回答知识密集型查询。 REVEAL采用神经表示学习来将不同的知识源编码和转换为由键值对组成的记忆结构。键作为记忆项的索引,而相应的值存储有关这些项的相关信息。在训练期间,REVEAL学习键嵌入、值令牌以及从这个记忆中检索信息以回答知识密集型查询的能力。这种方法使模型参数可以集中处理有关查询的推理,而不是专门用于记忆。
 |
| 我们使用多源多模态的知识语料库来扩展视觉语言模型,以便检索多个知识条目,有助于生成。 |
从多模态知识语料库中构建记忆
我们的方法类似于REALM,因为我们预计算来自不同来源的知识项的键和值嵌入,并将它们索引到统一的知识存储器中,其中每个知识项都被编码为键值对。每个键是一个d维嵌入向量,而每个值是代表知识项更详细信息的令牌嵌入序列。与以前的工作相反,REVEAL利用了多样化的多模态知识语料库,包括WikiData知识图,Wikipedia段落和图像,Web图像-文本对和视觉问答数据。每个知识项可以是文本、图像、二者的组合(例如Wikipedia中的页面)或来自知识图形的关系或属性(例如Barack Obama身高6’2“)。在训练期间,随着模型参数的更新,我们持续重新计算记忆键和值嵌入。我们每隔一千个训练步骤异步更新一次记忆。
使用压缩来扩展记忆
对于编码记忆值的天真解决方案是保留每个知识项的整个令牌序列。然后,模型可以通过将所有令牌连接起来并将其馈送到变压器编码器-解码器流水线中来融合输入查询和top-k检索到的记忆值。此方法有两个问题:(1)如果每个记忆值由数百个令牌组成,则在内存中存储数亿个知识项是不切实际的;(2)变压器编码器与自注意中的总令牌数和k的平方复杂度相关。因此,我们建议使用Perceiver体系结构来对知识项进行编码和压缩。Perceiver模型使用变压器解码器将完整的令牌序列压缩为任意长度。这使我们可以检索k为100的顶部k记忆条目。
以下图示展示了构建内存键值对的过程。每个知识项目都会通过多模态视觉语言编码器进行处理,生成图像和文本令牌序列。键头然后将这些令牌转换为紧凑的嵌入向量。值头(感知器)将这些令牌压缩成较少的令牌,保留有关知识项目的相关信息。
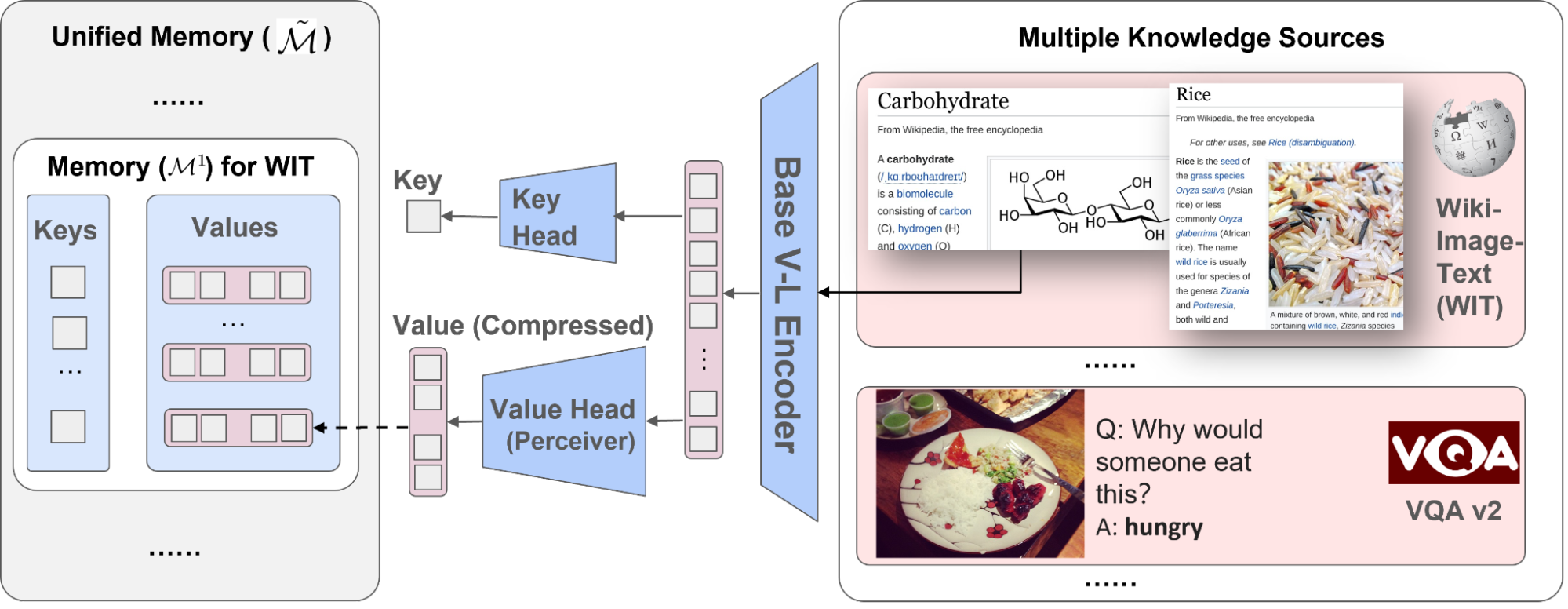 |
| 我们将来自不同语料库的知识条目编码成统一的键和值嵌入对,其中键用于索引内存,值包含有关条目的信息。 |
基于图像-文本对的大规模预训练
为了训练REVEAL模型,我们从公共网络中收集了三十亿个图像替代文本标题对的大规模语料库,这些语料库在LiT中介绍。由于数据集存在噪声,我们添加了一个过滤器来删除标题短于50个字符的数据点,这样大约就有13亿个图像标题对。然后,我们将这些对与SimVLM中使用的文本生成目标相结合,对REVEAL进行训练。针对给定的图像-文本示例,我们随机采样一个包含文本前几个令牌的前缀。我们将文本前缀和图像作为输入提供给模型,目标是生成其余文本作为输出。训练目标是将前缀条件化并自回归生成剩余的文本序列。
为了使REVEAL的所有组件都能够端到端地进行训练,我们需要将模型预热到一个良好的状态(将初始值设置为模型参数)。否则,如果我们从随机权重(冷启动)开始,检索器通常会返回无关的存储项,这些存储项从不会生成有用的训练信号。为了避免这个冷启动问题,我们构建了一个具有伪“地面真实知识”的初始检索数据集,以使预训练具有合理的开端。
我们为此目的创建了WIT数据集的修改版本。WIT中的每个图像-标题对也带有相应的维基百科段落(周围的文本)。我们将周围的段落与查询图像组合在一起,并将其作为对应于输入查询的伪地面真实知识。该段落提供了有关图像和标题的丰富信息,对于初始化模型非常有用。
为了防止模型依赖于低级别的图像特征进行检索,我们对输入查询图像应用了随机数据增强。给定包含伪检索地面真实知识的修改后数据集,我们训练查询和内存键嵌入以预热模型。
REVEAL工作流程
REVEAL的整体工作流程包括四个主要步骤。首先,REVEAL将多模态输入编码为令牌嵌入序列以及压缩的查询嵌入。然后,模型将每个多源知识条目转换为统一的键和值嵌入对,其中键用于内存索引,值包含整个条目的信息。接下来,REVEAL从多个知识源中检索与之相关的前k个知识片段,返回存储在内存中的预处理值嵌入,并重新对值进行编码。最后,REVEAL通过注入检索得分(查询和键嵌入之间的点积)作为先验条件进行注意力计算,通过注意力知识融合层融合前k个知识片段。该结构对于使内存、编码器、检索器和生成器能够同时进行端到端的训练非常有用。
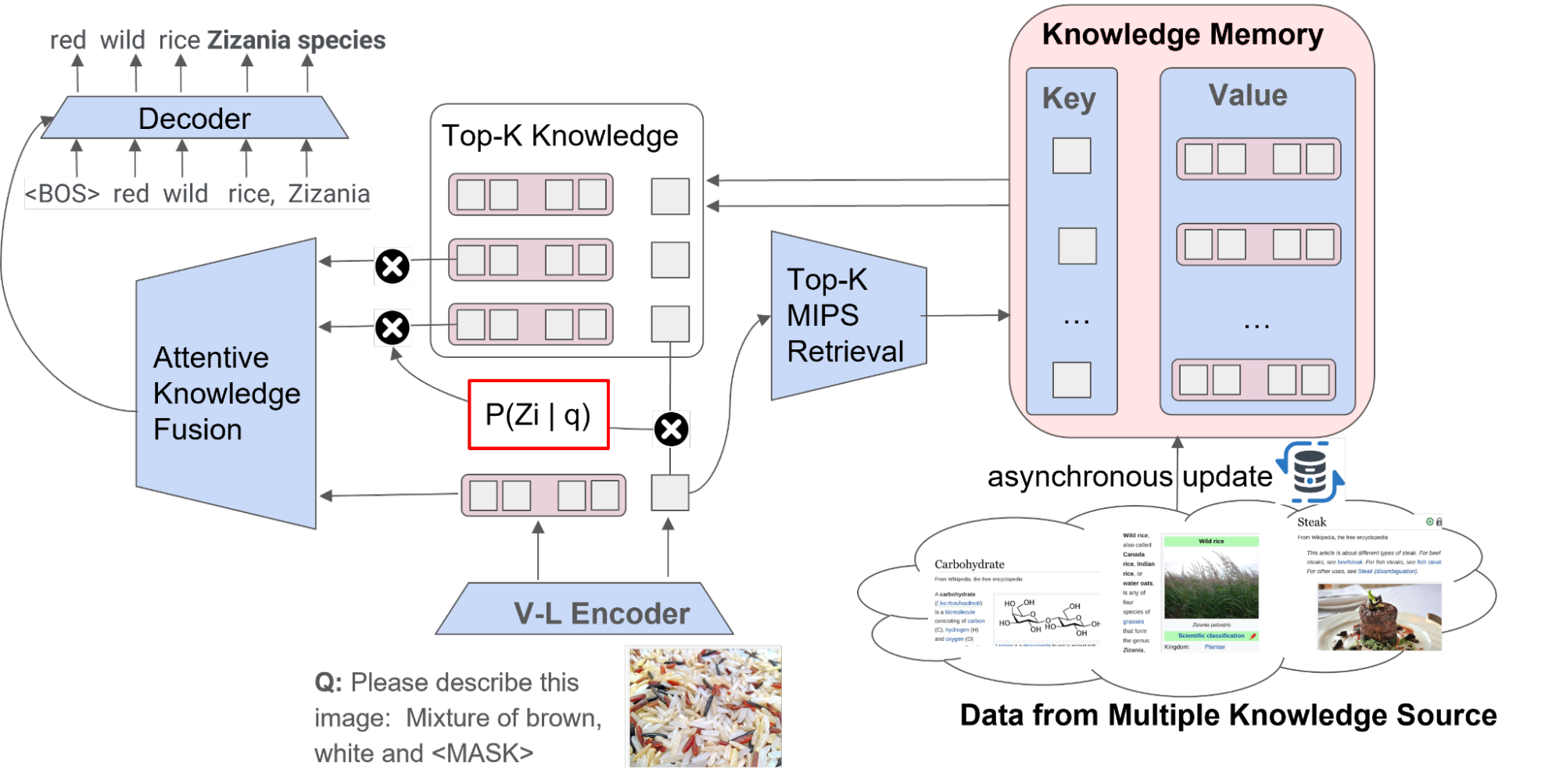 |
| REVEAL的整体工作流程。 |
结果
我们使用OK-VQA和A-OKVQA数据集对REVEAL在基于知识的视觉问答任务上进行评估。我们使用相同的生成目标在VQA任务上微调预训练模型,其中模型将图像-问题对作为输入并生成文本答案作为输出。我们证明REVEAL在A-OKVQA数据集上的结果优于早期尝试,这些尝试包括将固定知识或利用大型语言模型(例如GPT-3)作为隐含知识源的作品。
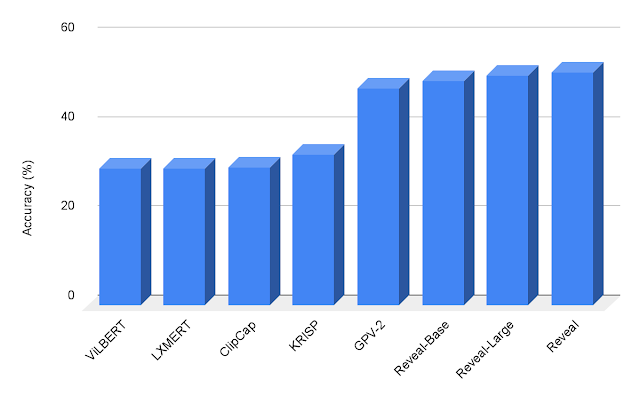 |
| A-OKVQA上的视觉问答结果。 REVEAL的准确性比之前的作品包括ViLBERT、LXMERT、ClipCap、KRISP和GPV-2都要高。 |
我们还使用MSCOCO和NoCaps数据集对REVEAL进行图像字幕基准测试。我们直接使用交叉熵生成目标在MSCOCO训练集上对REVEAL进行微调。我们使用CIDEr度量衡量我们在MSCOCO测试集和NoCaps评估集上的表现,该度量是基于这样一个想法,即好的字幕应该在词选择、语法、含义和内容方面与参考字幕相似。我们的MSCOCO字幕和NoCaps数据集的结果如下所示。
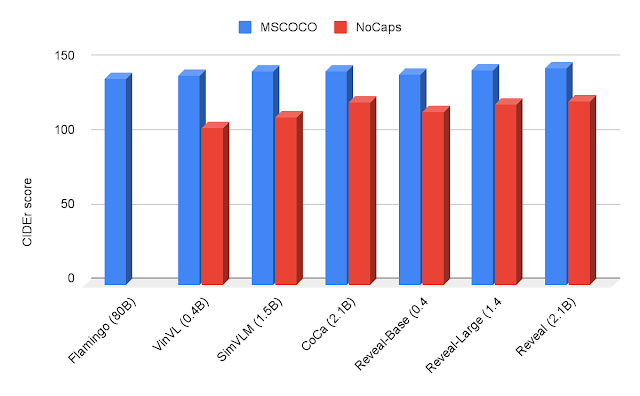 |
| 使用CIDEr度量的MSCOCO和NoCaps上的图像字幕结果。REVEAL的得分比Flamingo、VinVL、SimVLM和CoCa都要高。 |
以下是REVEAL检索相关文档以回答视觉问题的几个定性示例。
 |
| REVEAL可以使用不同来源的知识来正确回答问题。 |
结论
我们提出了一种端到端检索增强的视觉语言(REVEAL)模型,其中包含一个知识检索器,学习如何利用不同形式的各种知识源。我们使用四个不同的知识语料库对REVEAL进行训练,并在知识密集型的视觉问答和图像字幕任务上取得了最先进的结果。在未来,我们希望探索该模型在归因方面的能力,并将其应用于更广泛的多模态任务。
致谢
这项研究由胡子牛、Ahmet Iscen、孙晨、王子睿、Kai-Wei Chang、孙一舟、Cordelia Schmid、David A. Ross和Alireza Fathi进行。