基于图表推理的基础模型
由Google Research的研究软件工程师Julian Eisenschlos发布
视觉语言是一种依赖于图像符号而非文本来传达信息的通信形式。它在我们的数字生活中无处不在,以图标、信息图、表格、图、图表等形式存在,延伸到现实世界中的街道标志、漫画书、食品标签等。因此,让计算机更好地理解这种类型的媒体有助于科学交流和发现、可访问性和数据透明度。
尽管自ImageNet问世以来,基于学习的解决方案已经使计算机视觉模型取得了巨大进展,但重点是自然图像,其中定义、研究和在某些情况下推进了各种任务,例如分类、视觉问答(VQA)、字幕、检测和分割等,已经达到了人类的表现。然而,视觉语言并没有得到类似的关注,可能是因为这个领域缺乏大规模的训练集。但是,在过去的几年中,已经创建了新的学术数据集,旨在在视觉语言图像上评估问答系统,例如PlotQA、InfographicsVQA和ChartQA。
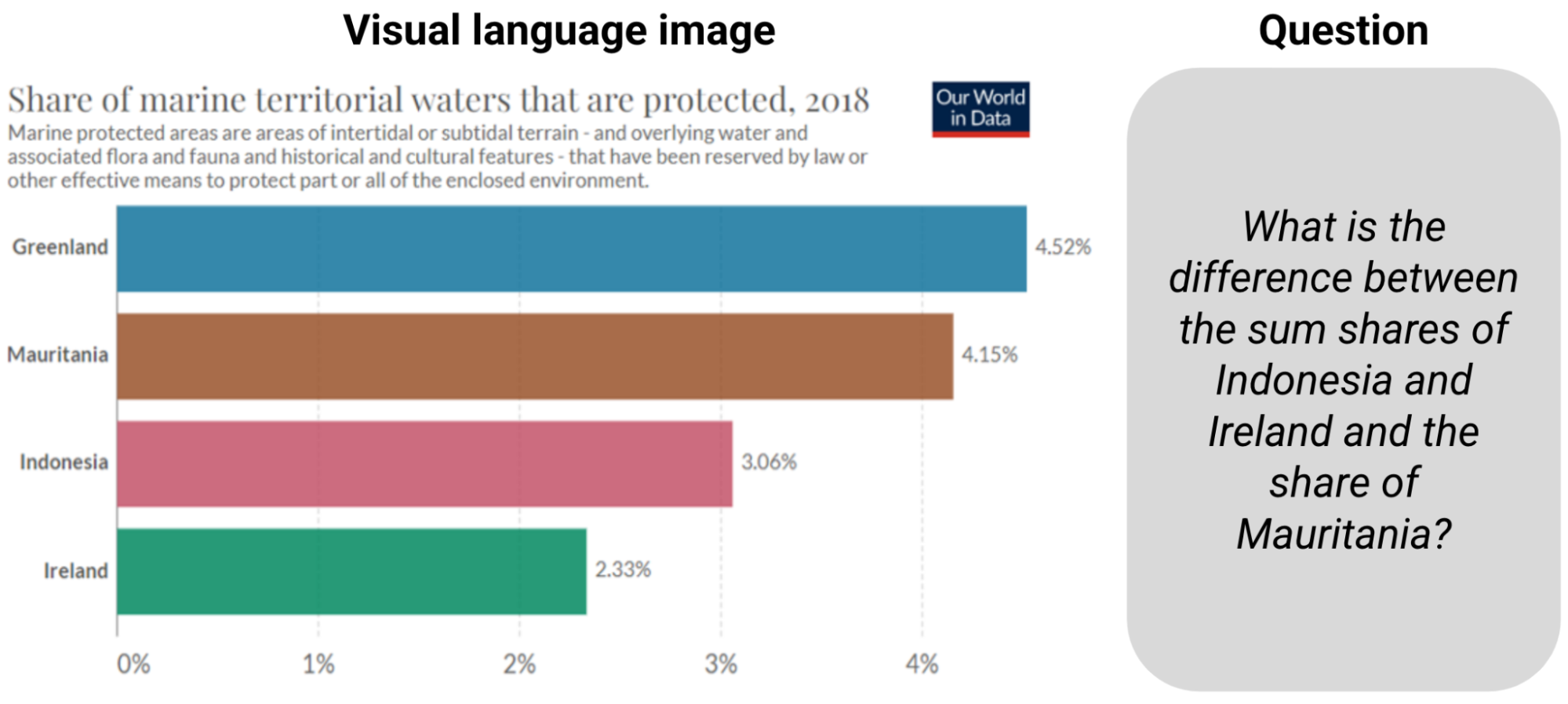 |
| 来自ChartQA的示例。回答问题需要阅读信息并计算总和和差。 |
为这些任务构建的现有模型依赖于将光学字符识别(OCR)信息及其坐标集成到更大的管道中,但这个过程容易出错、速度慢且泛化能力差。这些方法的普及是因为基于卷积神经网络(CNN)或变换器预训练的现有端到端计算机视觉模型不能轻松地适应视觉语言。但是,现有模型对于回答图表问题的挑战并不准备充分,包括阅读条形图的相对高度或饼图中切片的角度,理解轴刻度,将象形图与其传说值与颜色、大小和纹理正确映射,最后对提取的数字执行数值操作。
考虑到这些挑战,我们提出了“MatCha:增强数学推理和图表解除的视觉语言预训练”。MatCha代表数学和图表,是一个像素到文本的基础模型(一个预训练模型,具有内置的归纳偏差,可以为多个应用程序进行微调),它在两个互补的任务上进行了训练:(a)图表解除和(b)数学推理。在图表解除中,给定一个图或表,图像到文本模型需要生成其基础数据表或用于呈现它的代码。对于数学推理预训练,我们选择了文本数值推理数据集,并将输入渲染成图像,图像到文本模型需要解码以获取答案。我们还提出了“DePlot:通过将图表翻译为表格进行一次性视觉语言推理”的模型,该模型建立在MatCha之上,用于通过将图表翻译为表格进行一次性推理。通过这些方法,我们超过了ChartQA先前的最新技术水平20%以上,并匹配了具有1000倍参数的最佳总结系统。这两篇论文将在ACL2023上展示。
图表解除
图和表通常是由基础数据表和一段代码生成的。代码定义了图的整体布局(例如类型、方向、颜色/形状方案),而基础数据表则建立了实际的数字及其分组。数据和代码都会被发送到编译器/渲染引擎以创建最终的图像。要理解一个图表,需要发现图像中的视觉模式,并有效地解析和分组它们以提取关键信息。反转绘图渲染过程要求具备所有这些能力,因此可以作为一种理想的预训练任务。
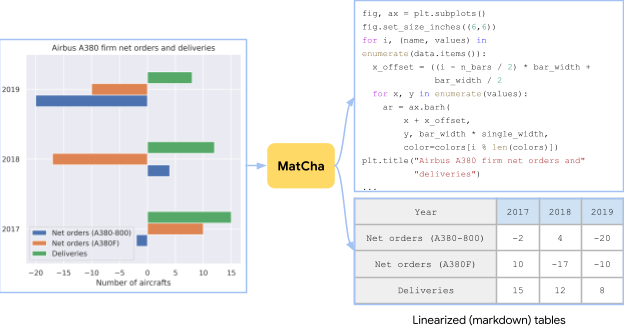 |
| 该图表是使用随机绘图选项从Airbus A380维基百科页面中的表格创建的。MatCha的预训练任务包括从图像中恢复源表格或源代码。 |
实际上,同时获取图表、其基础数据表和渲染代码是具有挑战性的。为了收集足够的预训练数据,我们独立收集[图表、代码]和[图表、表格]对。对于[图表、代码],我们爬取所有带有适当许可证的GitHub IPython笔记本,并提取图表块。图和紧随其后的代码块被保存为一个[图表、代码]对。对于[图表、表格]对,我们探索了两个来源。对于第一个来源,即合成数据,我们手动编写代码,将从TaPas代码库中爬取的维基百科表格转换为图表。我们根据列类型从多个绘图选项中进行抽样和组合。此外,我们还添加了在PlotQA中生成的[图表、表格]对,以使预训练语料库多样化。第二个来源是爬取的[图表、表格]对。我们直接使用ChartQA训练集中爬取的[图表、表格]对,该训练集共包含来自四个网站的约20k个对:Statista、Pew、Our World in Data和OECD。
数学推理
我们通过从文本数学数据集中学习数学推理技能,将数值推理知识融入到MatCha中。我们使用两个现有的文本数学推理数据集,MATH和DROP进行预训练。MATH是合成的,每个模块(类型)的问题包含200万个训练示例。DROP是一种阅读理解式QA数据集,其中输入是段落上下文和一个问题。
为了解决DROP中的问题,模型需要阅读段落,提取相关数字并执行数值计算。我们发现这两个数据集是互补的。MATH包含大量不同类别的问题,这有助于我们确定需要显式注入模型中的数学操作。DROP的阅读理解格式类似于典型的QA格式,其中模型同时执行信息提取和推理。在实践中,我们将两个数据集的输入呈现为图像。模型受过训练以解码答案。
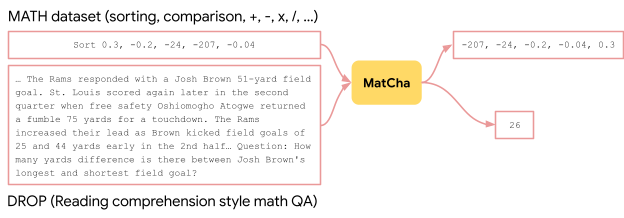 |
| 为了提高MatCha的数学推理能力,我们将MATH和DROP的示例合并到预训练目标中,将输入文本呈现为图像。 |
端到端结果
我们使用Pix2Struct模型骨干,这是一种针对网站理解的图像到文本变换器,并对其进行上述两个任务的预训练。我们通过在几项视觉语言任务上进行微调,展示了MatCha的优势——这些任务涉及用于问答和摘要的图表和绘图,其中不能访问底层表格。MatCha在性能上大幅超过了以前的模型,并且也优于以前的最先进技术,该技术假设可以访问底层表格。
在下图中,我们首先评估了两个基线模型,这些模型将来自OCR管道的信息纳入其中,直到最近这是处理图表的标准方法。第一个基于T5,第二个基于VisionTaPas。我们还与PaLI-17B进行比较,该模型是一个大型(比其他模型大约1000倍)的图像加文本到文本的转换器,训练了多种任务,但对于阅读文本和其他形式的视觉语言的能力有限。最后,我们报告了Pix2Struct和MatCha模型的结果。
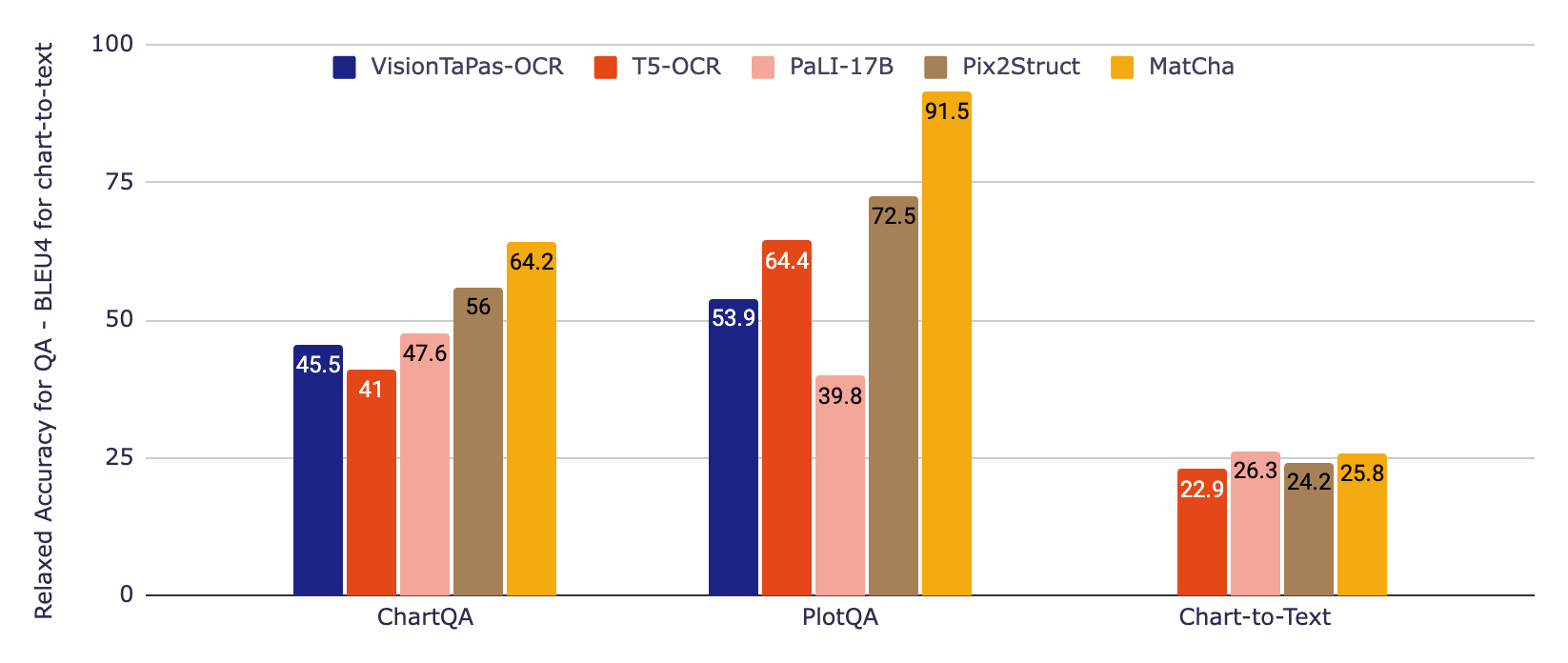 |
| 使用宽松精度的QA基准ChartQA和PlotQA(使用)和图表摘要基准chart-to-text(使用BLEU4)的实验结果。与较大的模型相比,Matcha在QA方面取得了显着的改进,并在摘要方面与这些较大的模型相匹配。 |
对于QA数据集,我们使用官方宽松精度度量,允许数值输出中的小相对误差。对于图表到文本摘要,我们报告BLEU分数。在问答方面,MatCha取得了明显的改进,并且在摘要方面与PaLI相当,其中大尺寸和广泛的长文本/字幕生成预训练对于这种长形文本生成非常有优势。
去渲染加大型语言模型链
虽然对于其参数数量而言极具性能,尤其是在抽取任务上,但我们观察到微调的MatCha模型仍可能难以进行端到端的复杂推理(例如,涉及大量数字或多个步骤的数学运算)。因此,我们还提出了一个两步方法来解决这个问题:1)模型读取图表,然后输出底层表格,2)大型语言模型(LLM)读取此输出,然后尝试仅基于文本输入回答问题。
对于第一个模型,我们仅将MatCha微调到图表到表格任务上,将输出序列长度增加以确保可以恢复图表中的所有或大部分信息。DePlot是结果模型。在第二阶段,可以使用任何LLM(例如FlanPaLM或Codex)来完成任务,并且我们可以依赖于标准方法来提高LLM的性能,例如思维链和自一致性。我们还尝试了思考程序,其中模型生成可执行的Python代码来卸载复杂计算。
 |
| DePlot + LLM方法的说明。这是使用FlanPaLM和Codex的真实示例。蓝色框是LLM的输入,红色框包含LLM生成的答案。我们在每个答案中突出显示了一些关键推理步骤。 |
如上例所示,DePlot模型与LLMs的组合在ChartQA的人类来源部分表现优异,特别是在需要更困难推理但问题更自然的情况下。此外,DePlot+LLM可以在没有训练数据的情况下实现此目标。
我们已经在我们的GitHub上发布了新的模型和代码,你可以在colab上自己尝试。请查看MatCha和DePlot论文以获取更多实验结果的详细信息。我们希望我们的结果能够有益于研究社区,并使图表中的信息对每个人更加易于访问。
致谢
此工作由我们的语言团队中的Fangyu Liu、Julian Martin Eisenschlos、Francesco Piccinno、Syrine Krichene、Chenxi Pang、Kenton Lee、Mandar Joshi、Wenhu Chen和Yasemin Altun作为Fangyu的实习项目进行。来自剑桥的Nigel Collier也是合作者。我们要感谢Joshua Howland、Alex Polozov、Shrestha Basu Mallick、Massimo Nicosia和William Cohen对我们宝贵的意见和建议。





