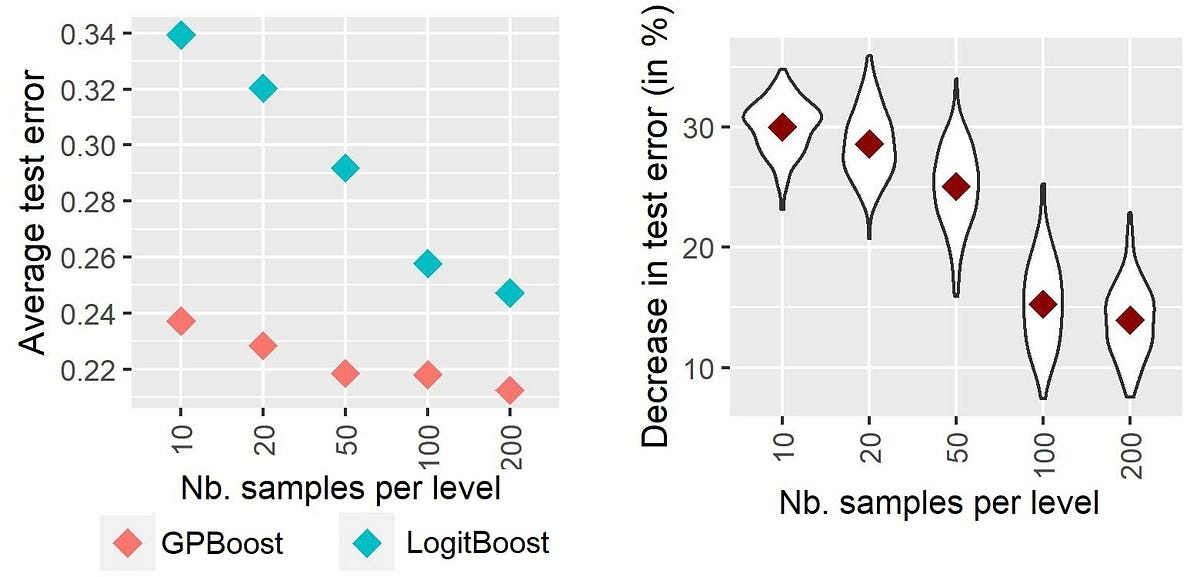
强化学习:教会计算机做出最优决策
Reinforcement Learning Teaching computers to make optimal decisions.
什么是强化学习?
强化学习是机器学习的一个分支,它处理的是通过经验学习如何与复杂环境进行交互的代理。
从在复杂棋盘游戏(如国际象棋和围棋)中玩并超越人类表现的AI代理到自主导航,强化学习具有一系列有趣且多样化的应用。
在强化学习领域中的重大突破包括DeepMind的AlphaGo Zero代理,它可以击败人类围棋冠军,以及AlphaFold,它可以预测复杂的三维蛋白质结构。
这篇指南将向您介绍强化学习范式。我们将以一个简单但富有启发性的现实世界示例来理解强化学习框架。
强化学习框架
让我们首先定义强化学习框架的组成部分。
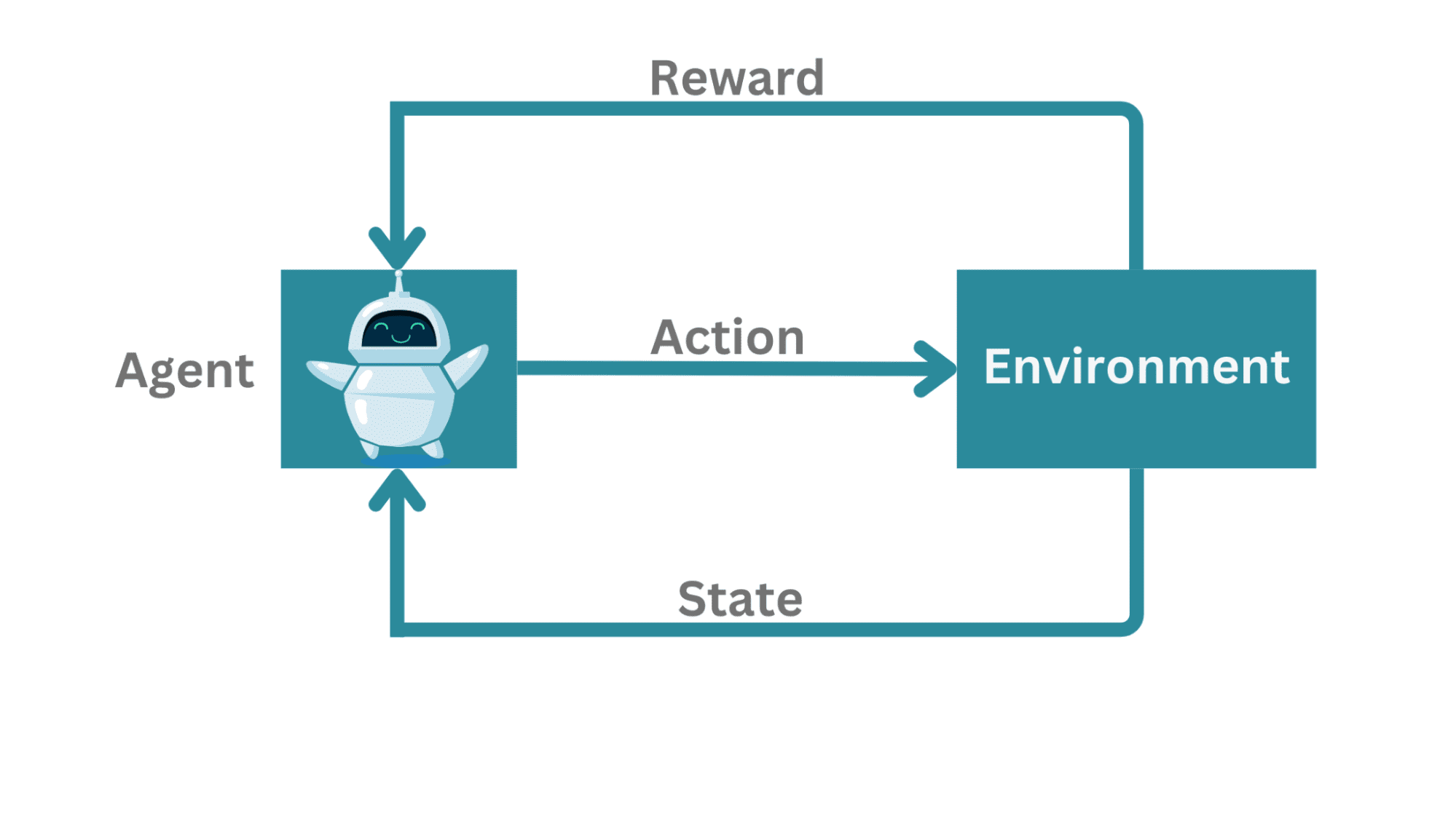
在典型的强化学习框架中:
- 有一个代理学习与环境进行交互。
- 代理可以测量其状态,采取行动,并偶尔获得奖励。
这种设置的实际示例:代理可以与对手对战(比如下国际象棋)或尝试在复杂环境中导航。
作为一个超级简化的例子,考虑一个迷宫中的老鼠。在这里,代理不是在与对手对战,而是试图找到一条通往出口的路径。如果有多条通往出口的路径,我们可能会选择最短的路径离开迷宫。

在这个例子中,老鼠是代理,试图在迷宫中导航,而这个迷宫就是环境。这里的行动是老鼠在迷宫中的移动。当它成功地导航迷宫到达出口时,它会得到一块奶酪作为奖励。
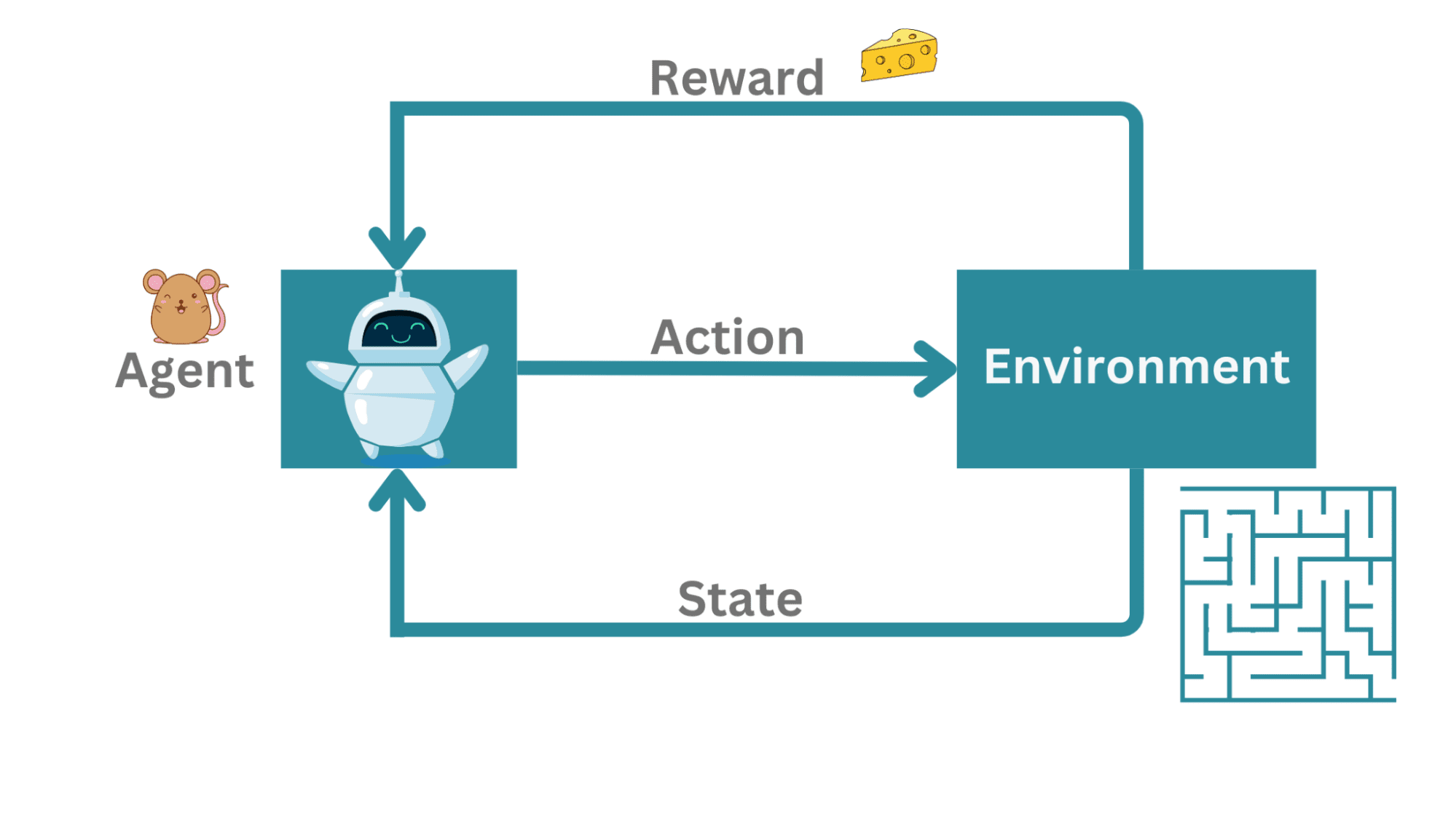
行动的序列在离散的时间步骤中发生(比如 t = 1, 2, 3,…)。在任何时间步骤 t 中,老鼠只能测量迷宫中的当前状态。它还不知道整个迷宫。
因此,代理(老鼠)在时间步骤 t 中测量其在环境中的状态 s_t,采取有效的行动 a_t 并移动到状态 s_(t + 1)。
强化学习与其他学习方法的不同之处
注意老鼠(代理)必须通过试错的方式找到迷宫的出口。如果老鼠撞到迷宫的墙壁之一,它必须尝试找到另一条路返回并选择一条不同的路径到达出口。
如果这是一个监督学习环境,每次行动之后,代理都会知道该行动是否正确,并且是否会获得奖励。监督学习就像是从一个老师那里学习。
而强化学习则是在表演结束后才会得到一个评论家的评价,告诉你你的表现好坏如何。因此,强化学习也被称为在评论家存在的情况下学习。
终止状态和回合
当老鼠到达出口时,它到达了终止状态,意味着它无法再探索更多。
从初始状态到终止状态的一系列行动被称为一个回合。对于任何学习问题,我们需要多个回合让代理学习如何导航。在这里,对于我们的代理(老鼠)学习哪些行动序列会引导它到达出口,并随后获得奶酪,我们需要多个回合。
稠密和稀疏奖励
每当Agent执行正确的动作或者正确的动作序列时,它会得到一个奖励。在这个例子中,老鼠通过迷宫(环境)到达出口,获得一块奶酪作为奖励。
在这个例子中,老鼠只在最后到达出口时才会获得一块奶酪。这是一个稀疏和延迟的奖励的例子。
如果奖励更频繁,那么我们就会有一个稠密的奖励系统。
回顾过去,我们需要弄清楚(这并不是很简单)是哪个动作或动作序列导致Agent获得奖励;这通常被称为信用分配问题。
策略、价值函数和优化问题
环境通常不是确定性的,而是概率性的,策略也是如此。给定一个状态s_t,Agent采取一个动作,并以一定的概率转移到另一个状态s_(t+1)。
策略帮助定义了从可能状态集合到动作的映射。它有助于回答以下问题:
- 为了最大化预期的奖励,应该采取哪些动作?
- 或者更好的是:给定一个状态,Agent可以采取的最佳动作是什么,以便最大化预期的奖励?
所以你可以把Agent视为执行策略π:

另一个相关且有用的概念是价值函数。价值函数由以下公式给出:

这表示在给定策略π的情况下,处于某个状态的价值。该量表示Agent从当前状态开始并执行策略π后未来的预期奖励。
总而言之,强化学习的目标是优化策略以最大化未来的预期奖励。因此,我们可以将其视为一个解决策略π的优化问题。
折扣因子
请注意,我们有一个新的量ɣ。它代表什么?ɣ被称为折扣因子,它是一个介于0和1之间的量。这意味着未来的奖励会被折扣(因为现在比很久以后更重要)。
探索与利用的权衡
回到老鼠在迷宫中寻找食物的例子:如果老鼠能够找到一条到达A出口的路径并获得一块小奶酪,它可以重复这个路径并收集奶酪。
但是,如果迷宫中还有另一个出口B,有一块更大的奶酪(更大的奖励),那么只要老鼠继续利用当前的策略而不探索新的策略,它就无法获得更大的奖励。
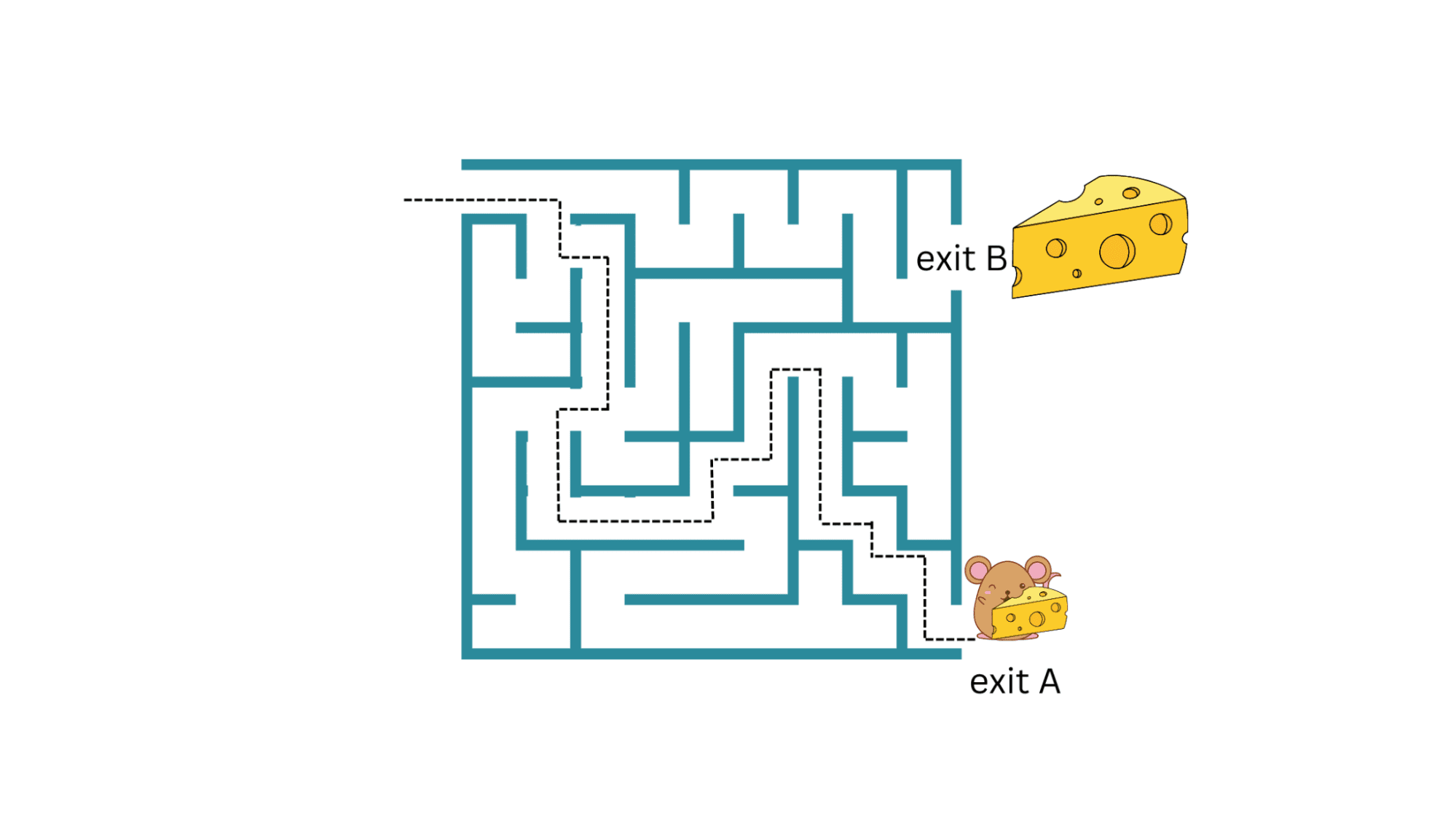
但探索新策略和未来奖励的不确定性更大。那么我们如何利用和探索?这种在利用当前策略和探索可能具有更好奖励的新策略之间的权衡被称为探索与利用的权衡。
一种可能的方法是ε-贪婪搜索。给定一组所有可能的动作,ε-贪婪搜索以概率ε探索其中一个可能的动作,以概率1 – ε利用当前策略。
总结和下一步
让我们总结一下我们到目前为止学到的内容。我们了解了强化学习框架的组成部分:
- Agent与环境进行交互,测量当前状态,采取行动,并获得正面强化的奖励。该框架是概率性的。
- 然后我们讨论了价值函数和策略,以及优化问题通常归结为找到最优策略来最大化未来预期奖励。
你已经学会了足够的知识来了解强化学习的领域。接下来该如何进行?在本指南中,我们没有讨论强化学习算法,因此你可以探索一些基本算法:
- 如果我们对环境了解得非常透彻(并且能够完全建模),我们可以使用基于模型的算法,如策略迭代和值迭代。
- 然而,在大多数情况下,我们可能无法完全建模环境。在这种情况下,你可以看一下无模型算法,比如优化状态-动作对的Q学习。
如果你想进一步了解强化学习,可以参考David Silver在YouTube上的强化学习讲座和Hugging Face的深度强化学习课程,这些都是一些不错的资源。Bala Priya C是来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉领域工作。她的兴趣和专长包括DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过撰写教程、指南、观点文章等来学习并与开发者社区分享她的知识。