将Falcon-7B部署到生产环境中
Deploy Falcon-7B to production environment.
逐步教程
在云中作为微服务运行Falcon-7B

背景
到目前为止,我们已经看到了ChatGPT的能力和它所提供的内容。然而,对于企业使用来说,像ChatGPT这样的闭源模型可能会带来风险,因为企业无法控制其数据。OpenAI声称用户数据不会被存储或用于训练模型,但不能保证数据不会以某种方式泄露。
为了解决与闭源模型相关的一些问题,研究人员正在争相构建与ChatGPT等模型媲美的开源LLM。通过使用开源模型,企业可以在安全的云环境中托管模型,从而减少数据泄露的风险。此外,您可以完全透明地了解模型的内部工作原理,这有助于建立更多对AI的信任。
随着开源LLM的最新进展,尝试新模型并了解它们与ChatGPT等闭源模型的差异变得很诱人。
然而,运行开源模型目前存在重大障碍。调用ChatGPT API比弄清楚如何运行开源LLM要容易得多。
在本文中,我旨在打破这些障碍,展示如何在云中以生产环境的方式运行开源模型,例如Falcon-7B模型。我们将能够通过类似ChatGPT的API端点访问这些模型。
挑战
运行开源模型的一个重大挑战是缺乏计算资源。即使像Falcon 7B这样的“小”模型也需要GPU才能运行。
为了解决这个问题,我们可以利用云中的GPU。但这又带来了另一个挑战。我们如何将我们的LLM容器化?我们如何启用GPU支持?启用GPU支持可能很棘手,因为它需要了解CUDA。使用CUDA可能会非常麻烦,因为您必须弄清楚如何安装正确的CUDA依赖项以及哪些版本是兼容的。
因此,为了避免CUDA陷阱,许多公司已经创建了解决方案,可以轻松地将模型容器化并启用GPU支持。在本博客文章中,我们将使用一个名为Truss的开源工具,帮助我们轻松地将LLM容器化,而不需要太多麻烦。
Truss允许开发人员轻松地将使用任何框架构建的模型容器化。
为什么使用Truss?
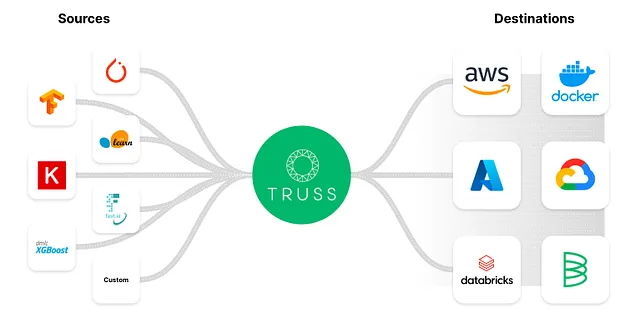
Truss具有很多有用的功能,例如:
- 将Python模型转换为带有生产就绪API端点的微服务
- 通过Docker冻结依赖项
- 支持在GPU上进行推理
- 模型的简单预处理和后处理
- 简单且安全的密钥管理
我之前使用过Truss部署机器学习模型,这个过程非常顺利和简单。Truss会自动创建您的dockerfile并管理Python依赖项。我们只需提供我们模型的代码。
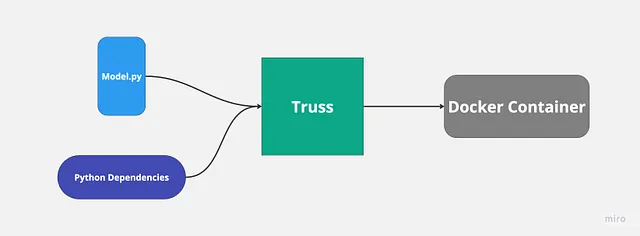
我们想使用类似Truss这样的工具的主要原因是,它能够更容易地部署支持GPU的模型。
注意:我没有收到Baseten的任何赞助来推广他们的内容,也与他们没有任何关联。我在任何方面都不受Baseten或Truss的任何影响,我只是发现他们的开源项目很酷和有用。
计划
以下是我在这篇博客文章中将要涵盖的内容:
- 使用Truss在本地设置Falcon 7B
- 如果你有GPU,可以在本地运行模型(我有一块RTX 3080)
- 将模型打包为容器并使用docker运行
- 在Google Cloud上创建一个启用GPU的Kubernetes集群来运行我们的模型
如果你在第2步没有GPU,不用担心,你仍然可以在云端运行模型。
如果你想跟着操作,这是包含代码的GitHub仓库:
GitHub – htrivedi99/falcon-7b-truss
通过在GitHub上创建一个账户来对htrivedi99/falcon-7b-truss进行贡献。
github.com
让我们开始吧!
步骤1:使用Truss进行Falcon 7B本地设置
首先,我们需要创建一个Python版本≥3.8的项目
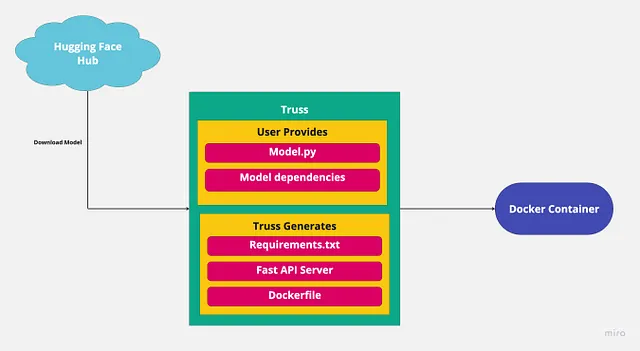
我们将从Hugging Face下载模型,并使用Truss进行打包。以下是我们需要安装的依赖项:
pip install truss在你的Python项目中创建一个名为main.py的脚本。这是我们将使用来处理Truss的临时脚本。
接下来,我们将通过在终端中运行以下命令来设置Truss包:
truss init falcon_7b_truss如果提示你创建一个新的truss,请按‘y’。完成后,你应该会看到一个名为falcon_7b_truss的新目录。在该目录下,会有一些自动生成的文件和文件夹。我们需要填写其中的一些内容:model.py在model包下,以及config.yaml。
├── falcon_7b_truss│ ├── config.yaml│ ├── data│ ├── examples.yaml│ ├── model│ │ ├── __init__.py│ │ └── model.py│ └── packages└── main.py正如我之前提到的,Truss只需要我们模型的代码,它会自动处理其他所有事情。我们将在model.py中编写代码,但是它必须按照特定的格式编写。
Truss希望每个模型至少支持三个函数:__init__,load和predict。
__init__主要用于创建类变量load用于从Hugging Face下载模型predict用于调用我们的模型
以下是model.py的完整代码:
import torchfrom transformers import AutoTokenizer, AutoModelForCausalLM, pipelinefrom typing import DictMODEL_NAME = "tiiuae/falcon-7b-instruct"DEFAULT_MAX_LENGTH = 128class Model: def __init__(self, data_dir: str, config: Dict, **kwargs) -> None: self._data_dir = data_dir self._config = config self.device = "cuda" if torch.cuda.is_available() else "cpu" print("运行推理的设备是:", self.device) self.tokenizer = None self.pipeline = None def load(self): self.tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) model_8bit = AutoModelForCausalLM.from_pretrained( MODEL_NAME, device_map="auto", load_in_8bit=True, trust_remote_code=True) self.pipeline = pipeline( "text-generation", model=model_8bit, tokenizer=self.tokenizer, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto", ) def predict(self, request: Dict) -> Dict: with torch.no_grad(): try: prompt = request.pop("prompt") data = self.pipeline( prompt, eos_token_id=self.tokenizer.eos_token_id, max_length=DEFAULT_MAX_LENGTH, **request )[0] return {"data": data} except Exception as exc: return {"status": "error", "data": None, "message": str(exc)}这里发生了什么:
MODEL_NAME是我们将使用的模型,我们的情况下是falcon-7b-instruct模型- 在
load中,我们以8位字节从Hugging Face下载模型。我们想要8位字节的原因是,当量化时,模型在GPU上使用的内存显着减少。 - 此外,如果要在显存小于13GB的GPU上本地运行模型,必须以8位字节加载模型。
predict函数接受一个JSON请求作为参数,并使用self.pipeline调用模型。torch.no_grad告诉Pytorch我们处于推理模式,而不是训练模式。
太酷了!这就是我们设置模型所需的全部内容。
步骤2:在本地运行模型(可选)
如果您拥有一块具有8GB以上显存的Nvidia GPU,您将能够在本地运行此模型。
如果没有,请随意继续下一步。
我们需要下载一些附加依赖项以在本地运行模型。在下载依赖项之前,您需要确保已安装CUDA和正确的CUDA驱动程序。
因为我们试图在本地运行模型,Truss将无法帮助我们管理CUDA的混乱。
pip install transformerspip install torchpip install peftpip install bitsandbytespip install einopspip install scipy 接下来,在位于 falcon_7b_truss 目录外创建的 main.py 脚本中,我们需要加载我们的 truss。
这是 main.py 的代码:
import trussfrom pathlib import Pathimport requeststr = truss.load("./falcon_7b_truss")output = tr.predict({"prompt": "Hi there how are you?"})print(output)这里发生了什么:
- 如果您还记得,
falcon_7b_truss目录是由 truss 创建的。我们可以使用truss.load加载整个包,包括模型和依赖项。 - 一旦我们加载了我们的包,我们只需要调用
predict方法即可获得模型的输出
运行 main.py 以获得模型的输出。
这些模型文件大小约为15GB,因此可能需要5-10分钟来下载模型。运行脚本后,您应该会看到类似以下输出:
{'data': {'generated_text': "Hi there how are you?\nI'm doing well. I'm in the middle of a move, so I'm a bit tired. I'm also a bit overwhelmed. I'm not sure how to get started. I'm not sure what I'm doing. I'm not sure if I'm doing it right. I'm not sure if I'm doing it wrong. I'm not sure if I'm doing it at all.\nI'm not sure if I'm doing it right. I'm not sure if I'm doing it wrong. I"}}步骤3:使用Docker容器化模型
通常,当人们将模型容器化时,他们会将模型二进制文件和Python依赖项捆绑在一起,并使用Flask或Fast API服务器进行封装。
其中很多都是样板代码,我们不想自己做。Truss将会处理它。我们已经提供了模型,Truss将创建服务器,因此剩下的唯一要做的就是提供Python依赖项。
config.yaml 包含我们模型的配置。这是我们可以添加模型依赖项的地方。配置文件已经包含了我们大部分所需的内容,但我们还需要添加一些内容。
这是您需要添加到 config.yaml 的内容:
apply_library_patches: truebundled_packages_dir: packagesdata_dir: datadescription: nullenvironment_variables: {}examples_filename: examples.yamlexternal_package_dirs: []input_type: Anylive_reload: falsemodel_class_filename: model.pymodel_class_name: Modelmodel_framework: custommodel_metadata: {}model_module_dir: modelmodel_name: Falcon-7Bmodel_type: custompython_version: py39requirements:- torch- peft- sentencepiece- accelerate- bitsandbytes- einops- scipy- git+https://github.com/huggingface/transformers.gitresources: use_gpu: true cpu: "3" memory: 14Gisecrets: {}spec_version: '2.0'system_packages: []所以我们添加的主要内容是 requirements 。列出的所有依赖都是下载和运行模型所需的。
我们添加的另一个重要内容是 resources 。use_gpu: true 是必需的,因为这告诉 Truss 为我们创建一个启用了 GPU 支持的 Dockerfile。
配置就这样了。
接下来,我们将把我们的模型打包成容器。如果你不知道如何使用 Docker 将模型容器化,不用担心,Truss 已经帮你搞定了。
在 main.py 文件中,我们将告诉 Truss 将所有内容一起打包。以下是你需要的代码:
import trussfrom pathlib import Pathimport requeststr = truss.load("./falcon_7b_truss")command = tr.docker_build_setup(build_dir=Path("./falcon_7b_truss"))print(command)正在发生的事情:
- 首先,我们加载我们的
falcon_7b_truss - 接下来,
docker_build_setup函数处理所有复杂的事情,比如创建 Dockerfile 和设置 Fast API 服务器。 - 如果你查看一下你的
falcon_7b_truss目录,你会看到生成了更多文件。我们不需要担心这些文件的工作原理,因为一切都会在幕后管理。 - 在运行结束时,我们会得到一个 docker 命令来构建我们的 docker 镜像:
docker build falcon_7b_truss -t falcon-7b-model:latest
如果你想构建 docker 镜像,请继续运行构建命令。镜像大小约为 9 GB,所以构建可能需要一些时间。如果你不想构建它,但想跟随进行,你可以使用我的镜像:htrivedi05/truss-falcon-7b:latest 。
如果你正在构建镜像自己,你需要为它打上标签并将其推送到 docker hub,以便我们在云中的容器可以拉取镜像。这是构建完镜像后需要运行的命令:
docker tag falcon-7b-model <docker_user_id>/falcon-7b-model
docker push <docker_user_id>/falcon-7b-model太棒了!我们已经准备好在云中运行我们的模型了!
(以下是在本地使用 GPU 运行镜像的可选步骤)
如果你有一块 Nvidia GPU,并且想要在本地使用 GPU 支持运行容器化的模型,你需要确保 Docker 配置为使用你的 GPU。
打开一个终端并运行以下命令:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) && curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - && curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
apt-get updateapt-get install -y nvidia-docker2
sudo systemctl restart docker现在你的 Docker 已经配置为访问你的 GPU,这是如何运行容器的方法:
docker run --gpus all -d -p 8080:8080 falcon-7b-model同样,下载模型可能需要一些时间。为了确保一切正常工作,你可以检查容器日志,你应该会看到 “THE DEVICE INFERENCE IS RUNNING ON IS: cuda”。
你可以通过 API 端点调用模型,像这样:
import requestsdata = {"prompt": "Hi there, how's it going?"}res = requests.post("http://127.0.0.1:8080/v1/models/model:predict", json=data)print(res.json())第4步:将模型部署到生产环境
在这里,我比较宽松地使用了“生产”一词。我们将在Kubernetes中运行我们的模型,它可以轻松扩展和处理可变的流量量。
话虽如此,Kubernetes有很多配置选项,例如网络策略、存储、配置映射、负载均衡、秘密管理等等。
尽管Kubernetes被构建为“扩展”和运行“生产”工作负载,但你需要的许多生产级配置并不是开箱即用的。涵盖这些高级Kubernetes主题超出了本文的范围,也会偏离我们在此处要完成的目标。所以在这篇博客文章中,我们将创建一个没有繁琐功能的最小集群。
言归正传,让我们创建我们的集群!
前提条件:
- 拥有一个带有项目的Google Cloud帐户
- 在您的机器上安装了gcloud命令行工具
- 确保您有足够的配额来运行启用GPU的机器。您可以在IAM & Admin下检查您的配额。
创建我们的GKE集群
我们将使用谷歌的Kubernetes引擎来创建和管理我们的集群。好了,是时候了解一些重要信息:
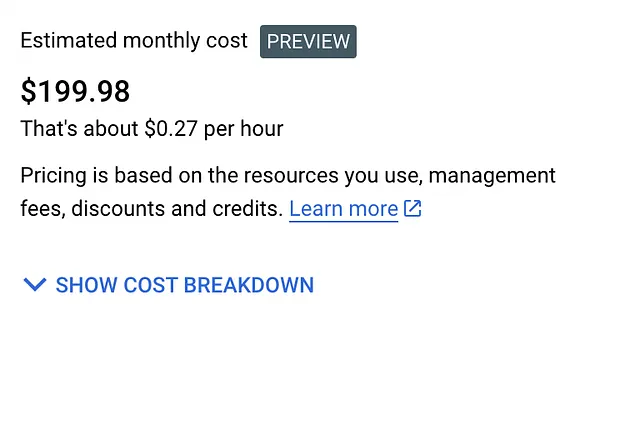
谷歌的Kubernetes引擎不是免费的。谷歌不会免费提供强大的GPU。话虽如此,我们将创建一个带有较低性能GPU的单节点集群。这个实验应该不会花费您超过1-2美元。
这是我们将要运行的Kubernetes集群的配置:
- 1个节点,标准的Kubernetes集群(非自动驾驶)
- 1个Nvidia T4 GPU
- n1-standard-4机器(4个vCPU,15GB内存)
- 所有这些都将在spot实例上运行
注意:如果您在另一个地区并且没有访问相同资源的权限,可以随意进行修改。
创建集群的步骤:
- 前往谷歌云控制台,搜索名为Kubernetes Engine的服务
2. 点击“CREATE”按钮
- 确保您创建的是标准集群,而不是自动驾驶集群。在顶部应该显示“创建一个Kubernetes集群”。
3. 集群基本信息
- 在集群基本信息选项卡中,我们不需要做太多更改。只需给集群命名即可。您不需要更改区域或控制平面。
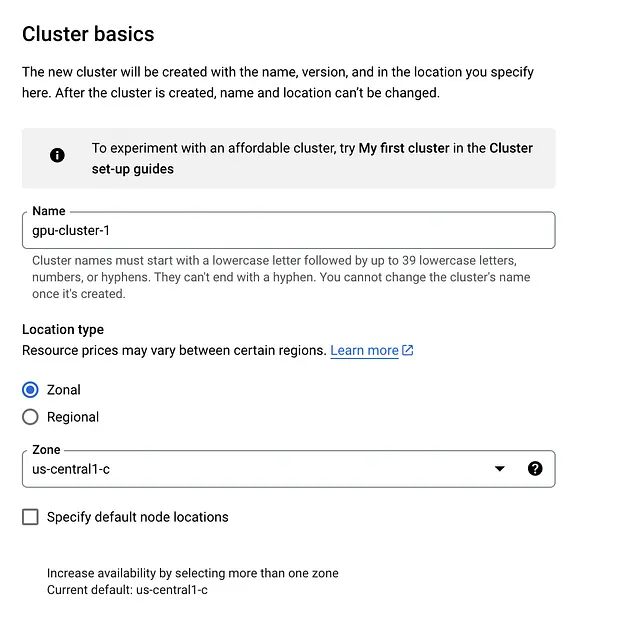
4. 点击“default-pool”选项卡,将节点数量更改为1
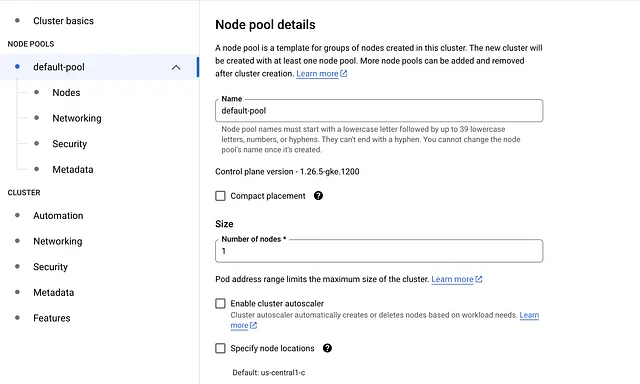
5. 在“default-pool”下点击左侧边栏中的“Nodes”选项卡
- 将“Machine Configuration”从“通用型”更改为“GPU”
- 选择“Nvidia T4”作为“GPU类型”,并设置数量为“1”
- 启用GPU共享(即使我们不会使用此功能)
- 将“Max shared clients per GPU”设置为8
- 对于“Machine Type”,选择“n1-standard-4(4个vCPU,15GB内存)”
- 将“Boot disk size”更改为50
- 滚动到底部,选中“启用spot VM上的节点”
这里是我为这个集群获得的估计价格的截图:
一旦您配置了集群,请继续创建它。
谷歌需要几分钟来设置所有内容。在您的终端中打开并运行以下命令:
gcloud config set compute/zone us-central1-c
gcloud container clusters get-credentials gpu-cluster-1如果您使用了不同的集群名称或区域,请相应地更新这些信息。要检查是否连接成功,请运行以下命令:
kubectl get nodes您应该在终端中看到1个节点。尽管我们的集群有一个GPU,但缺少一些Nvidia驱动程序,我们需要安装它们。幸运的是,安装它们很容易。运行以下命令以安装驱动程序:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml太棒了!我们终于准备好部署我们的模型了。
部署模型
要将模型部署到集群上,我们需要创建一个Kubernetes部署。Kubernetes部署允许我们管理容器化模型的实例。我不会深入介绍Kubernetes或如何编写YAML文件,因为这超出了范围。
您需要创建一个名为truss-falcon-deployment.yaml的文件。打开该文件并粘贴以下内容:
apiVersion: apps/v1kind: Deploymentmetadata: name: truss-falcon-7b namespace: defaultspec: replicas: 1 selector: matchLabels: component: truss-falcon-7b-layer template: metadata: labels: component: truss-falcon-7b-layer spec: containers: - name: truss-falcon-7b-container image: <your_docker_id>/falcon-7b-model:latest ports: - containerPort: 8080 resources: limits: nvidia.com/gpu: 1---apiVersion: v1kind: Servicemetadata: name: truss-falcon-7b-service namespace: defaultspec: type: ClusterIP selector: component: truss-falcon-7b-layer ports: - port: 8080 protocol: TCP targetPort: 8080发生了什么:
- 我们告诉Kubernetes我们想要使用
falcon-7b-model图像创建Pod。确保将<your_docker_id>替换为您的实际ID。如果您没有创建自己的Docker镜像并希望使用我的,请将其替换为以下内容:htrivedi05/truss-falcon-7b:latest - 我们通过设置资源限制
nvidia.com/gpu: 1来为容器启用GPU访问。这告诉Kubernetes为我们的容器请求一个GPU - 为了与我们的模型交互,我们需要创建一个在端口8080上运行的Kubernetes服务
通过在终端中运行以下命令来创建部署:
kubectl create -f truss-falcon-deployment.yaml如果运行以下命令:
kubectl get deployments您应该会看到类似如下的结果:
名称 就绪 最新 可用 年龄truss-falcon-7b 0/1 1 0 8秒部署需要几分钟时间才能变为就绪状态。请记住,每次容器重新启动时,模型都必须从Hugging Face下载。您可以通过运行以下命令来检查容器的进度:
kubectl get pods
kubectl logs truss-falcon-7b-8fbb476f4-bggts根据实际情况更改 pod 名称。
日志中有几个要注意的事项:
- 查找打印语句THE DEVICE INFERENCE IS RUNNING ON IS: cuda。这确认了我们的容器已正确连接到GPU。
- 接下来,您应该看到一些关于模型文件下载的打印语句
正在下载 (…)model.bin.index.json: 100%|██████████| 16.9k/16.9k [00:00<00:00, 1.92MB/s]正在下载 (…)l-00001-of-00002.bin: 100%|██████████| 9.95G/9.95G [02:37<00:00, 63.1MB/s]正在下载 (…)l-00002-of-00002.bin: 100%|██████████| 4.48G/4.48G [01:04<00:00, 69.2MB/s]正在下载 shards: 100%|██████████| 2/2 [03:42<00:00, 111.31s/it][01:04<00:00, 71.3MB/s]- 一旦模型下载完毕并且 Truss 创建了微服务,您应该在日志末尾看到以下输出:
{"asctime": "2023-06-29 21:40:40,646", "levelname": "INFO", "message": "Completed model.load() execution in 330588 ms"}通过这个消息,我们可以确认模型已加载并准备进行推理。
模型推理
我们不能直接调用模型,而是必须调用模型的服务
运行以下命令以获取您的服务名称:
kubectl get svc输出:
名称 类型 集群IP 外部IP 端口 年龄kubernetes ClusterIP 10.80.0.1 <none> 443/TCP 46mtruss-falcon-7b-service ClusterIP 10.80.1.96 <none> 8080/TCP 6m19struss-falcon-7b-service 是我们要调用的服务。为了使服务可访问,我们需要使用以下命令进行端口转发:
kubectl port-forward svc/truss-falcon-7b-service 8080输出:
Forwarding from 127.0.0.1:8080 -> 8080Forwarding from [::1]:8080 -> 8080太棒了,我们的模型作为 REST API 端点可在 127.0.0.1:8080 上访问。打开任何 Python 脚本,如 main.py,并运行以下代码:
import requestsdata = {"prompt": "Whats the most interesting thing about a falcon?"}res = requests.post("http://127.0.0.1:8080/v1/models/model:predict", json=data)print(res.json())输出:
{'data': {'generated_text': 'Whats the most interesting thing about a falcon?\nFalcons are known for their incredible speed and agility in the air, as well as their impressive hunting skills. They are also known for their distinctive feathering, which can vary greatly depending on the species.'}}哇喔!我们已成功将 Falcon 7B 模型容器化,并将其部署为生产中的微服务!
随意尝试不同的提示,看模型返回什么。
关闭集群
当你玩弄Falcon 7B玩够了之后,可以运行以下命令来删除部署:
kubectl delete -f truss-falcon-deployment.yaml接下来,转到Google云的Kubernetes引擎,并删除Kubernetes集群。
注意:除非另有说明,所有图片都由作者提供
结论
运行和管理像ChatGPT这样的生产级模型并不容易。然而,随着时间的推移,开发人员将会有更好的工具来部署自己的模型到云端。
在这篇博文中,我们基本介绍了将LLM部署到生产环境所需的所有内容。我们使用Truss打包模型,使用Docker将其容器化,并使用Kubernetes在云端部署。我知道这是一项需要理解的复杂任务,但我们还是做到了。
希望你从这篇博文中学到了一些有趣的东西。感谢阅读!
和平。