释放ChatGPT分词器
Release ChatGPT tokenizer.
亲身实践!ChatGPT如何管理标记?

你是否想过ChatGPT背后的关键组成部分是什么?
我们都被告知相同的事情:ChatGPT预测下一个单词。但实际上,这个说法有点不准确。ChatGPT并不是预测下一个单词,而是预测下一个标记。
标记?是的,标记是大型语言模型(LLM)的文本单位。
确实,ChatGPT在处理任何提示时的第一步是将用户输入拆分成标记。这就是所谓的分词器的工作。
在本文中,我们将揭示ChatGPT分词器的工作原理,并通过使用OpenAI使用的原始库的实际操作来进行实践,即tiktoken库。
TikTok-en…挺有趣的:)
让我们深入了解分词器执行的实际步骤,以及它的行为如何实际影响ChatGPT输出的质量。
分词器的工作原理
在文章《精通ChatGPT:使用LLMs进行有效摘要》中,我们已经看到了ChatGPT分词器背后的一些奥秘,但让我们从头开始。
分词器出现在文本生成过程的第一步。 它负责将我们输入到ChatGPT的文本分解为单个元素,即标记,然后由语言模型处理这些标记以生成新的文本。
当分词器将文本分解为标记时,它根据一组规则进行操作,这些规则旨在识别目标语言的有意义的单元。
例如,当出现在给定句子中的单词相当常见时,每个标记很可能对应一个单词。但是,如果我们使用的提示中使用了较少使用的单词,例如在句子“Prompting as powerful developer tool”中,我们可能无法获得一对一的映射。在这种情况下,单词prompting在英语中仍然不太常见,因此实际上被分解为三个标记:“’prom”,“pt”和“ing”,因为这三个标记是常见的字母序列。
让我们看看另一个例子!
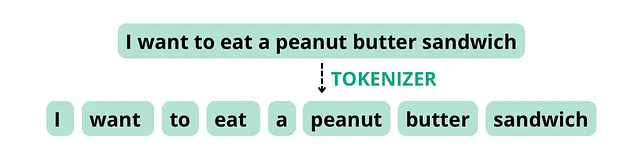
考虑以下句子:“我想吃花生酱三明治”。如果分词器根据空格和标点符号拆分标记,它可能将该句子拆分成以下标记,总词数为8,等于标记数。
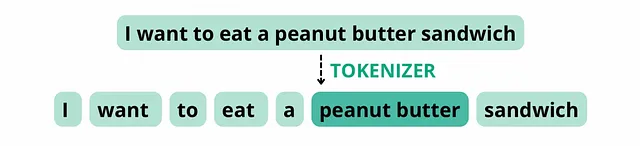
然而,如果分词器将“花生酱”视为一个复合词,因为这两个组件经常一起出现,它可能将该句子拆分成以下标记,总词数为8,但标记数为7。
在ChatGPT和标记管理的上下文中,术语编码和解码指的是将文本转换为模型可以理解的标记(编码)以及将模型的完成结果转换回可读的文本(解码)的过程。
Tiktoken库
了解ChatGPT分词器背后的理论是必要的,但在本文中,我也想专注于一些实际操作的揭示。
ChatGPT的实现使用tiktoken库来管理标记。我们可以像使用其他Python库一样启动它:
pip install --upgrade tiktoken安装完成后,获取ChatGPT使用的相同编码模型非常简单,因为有一个encoding_for_model()方法。根据名称推断,此方法会自动加载给定模型名称的正确编码。
对于给定模型的首次运行,需要通过互联网下载编码模型。后续运行不需要互联网,因为编码已经预先缓存。
对于广泛使用的gpt-3.5-turbo模型,我们可以简单地运行:
import tiktokenencoding = tiktoken.encoding_for_model("gpt-3.5-turbo")输出encoding是一个分词器对象,我们可以使用它来可视化ChatGPT实际上是如何看待我们的提示的。
更具体地说,tiktoken.encoding_for_model函数专门为gpt-3.5-turbo模型初始化一个分词和编码管道。该管道处理文本的分词和编码,为模型的输入做准备。
需要考虑的一个重要方面是,这些标记是数值表示。在我们的“Prompting as powerful developer tool”示例中,与单词“prompting”相关联的标记是“’prom”、“pt”和“ing”,但模型实际接收到的是这些序列的数值表示。
别担心!我们将在实践部分看到这是什么样子。
编码类型
tiktoken库支持多种编码类型。实际上,不同的gpt模型使用不同的编码。下表列出了最常见的编码:

编码 — 实践!
让我们继续并尝试对我们的第一个提示进行编码。给定提示“tiktoken is great!”和已加载的encoding,我们可以使用encoding.encode方法将提示拆分为标记并可视化它们的数值表示:
prompt = "tiktoken is great!"encoded_prompt = encoding.encode(prompt)print(encoded_prompt)# 输出:[83, 1609, 5963, 374, 2294, 0]是的,没错。输出[83, 1609, 5963, 374, 2294, 0]似乎并不是很有意义。但实际上,一眼就可以猜到一些东西。
<p明白了吗?
长度!我们可以快速看到我们的提示“tiktoken is great!”被分成了6个标记。在这种情况下,ChatGPT并不是基于空格将这个示例提示拆分,而是基于最常见的字母序列。
<p在我们的示例中,输出列表中的每个坐标对应于标记序列中的特定标记,即所谓的标记ID。标记ID是整数,根据模型使用的词汇表唯一标识每个标记。ID通常映射到词汇表中的单词或子单词单位。
让我们解码坐标列表,以确保它对应于我们的原始提示:
encoding.decode(encoded_prompt)# 输出:'tiktoken is great!'.decode()方法将标记整数列表转换为字符串。尽管.decode()方法可以应用于单个标记,但请注意对于不在utf-8边界上的标记,它可能会丢失信息。
现在,您可能想知道,是否有一种方法可以查看单个标记?
让我们试一试!
<p对于单个标记,.decode_single_token_bytes()方法安全地将单个整数标记转换为它所代表的字节。对于我们的示例提示:
[encoding.decode_single_token_bytes(token) for token in encoded_prompt]# 输出:[b't', b'ik', b'token', b' is', b' great', b'!']请注意,在字符串前面的b表示这些字符串是字节字符串。对于英语,一个标记大致平均对应四个字符或大约三分之四个单词。
了解文本如何分割成标记是有用的,因为GPT模型以标记形式看到文本。知道文本字符串中有多少个标记可以提供有用的信息,比如字符串是否过长以至于无法由文本模型处理,或者在使用上有多少个OpenAI API调用将会消耗,因为计费是按标记计算的,等等。
比较编码模型
正如我们所见,不同的模型使用不同的编码类型。有时,在模型之间的标记管理方面可能存在巨大差异。
不同的编码在单词分割、空格分组和处理非英文字符方面有所不同。使用上述方法,我们可以比较不同编码在几个示例字符串上提供的不同gpt模型的编码。
让我们比较上面的表格(gpt2,p50k_base和cl100k_base)的编码。为此,我们可以使用以下函数,该函数包含我们迄今为止看到的所有要素:
compare_encodings函数以一个example_string作为输入,并使用三种不同的编码方案(gpt2,p50k_base和cl100k_base)比较该字符串的编码。最后,它打印出有关编码的各种信息,包括标记的数量、标记的整数和标记的字节。
让我们尝试一些示例!

在这个第一个示例中,虽然gpt2和p50k_base模型通过将数学符号与空格合并在一起进行编码,但cl100k_base编码将它们视为单独的实体。
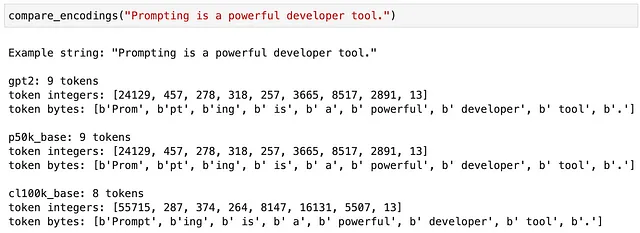
在这个示例中,分词单词Prompting的方式也取决于所选的编码。
分词器的限制

这种分词输入提示的方式有时会导致一些ChatGPT完成错误。例如,如果我们要求ChatGPT以相反的顺序书写单词lollipop,它会出错!
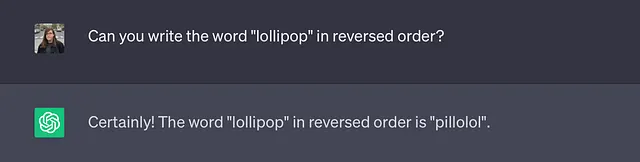
这里发生的情况是,分词器实际上将给定的单词分解为三个标记:“l”,“oll”和“ipop”。因此,ChatGPT看不到个别的字母,而是看到这三个标记,这使得按正确的顺序逆序打印出个别字母变得更加困难。
了解这些限制可以帮助你找到避免它们的解决方法。在这种情况下,如果我们在单词的每个字母之间添加连字符,我们可以强制分词器基于这些符号来拆分文本。通过稍微修改输入提示,它的表现要好得多:

使用短横线,模型可以更容易地看到每个字母,并按相反的顺序打印出来。所以请记住:如果您想使用ChatGPT玩单词游戏,如Word或Scrabble,或者基于这些原则构建一个应用程序,这个巧妙的技巧可以帮助它更好地看到单词的每个字母。
这只是一个简单的例子,ChatGPT的分词器在一个非常简单的任务中失败。您遇到过其他类似情况吗?
摘要
在本文中,我们探讨了ChatGPT如何看待用户提示并对其进行处理以生成完成输出,该输出基于其训练期间从大量语言数据中学到的统计模式。
通过使用tiktoken库,我们现在能够在将其输入ChatGPT之前评估任何提示。这有助于我们调试ChatGPT错误,因为稍微修改我们的提示可能会使ChatGPT更好地完成任务。
还有一个额外的要点:某些设计决策可能会在未来变成技术债务。就像我们在简单的棒棒糖例子中看到的,虽然该模型在令人惊叹的任务中成功了,但却无法完成简单的练习。而原因并不在于模型的能力,而是在于第一个分词步骤!
就是这些!非常感谢您的阅读!
我希望这篇文章对您在构建ChatGPT应用程序时有所帮助!
您还可以订阅我的通讯,以获取最新内容。尤其是,如果您对ChatGPT的文章感兴趣:
掌握ChatGPT:使用LLMs进行有效摘要
如何提示ChatGPT以获得高质量摘要
towardsdatascience.com
OpenAI的提示工程课程:使用ChatGPT进行推理、转换和扩展
在您的自定义应用中最大化ChatGPT的潜力
VoAGI.com
开启ChatGPT的新维度:文本到语音集成
提升ChatGPT交互中的用户体验
towardsdatascience.com
如有任何问题,请随时发送电子邮件至[email protected]: