实时拥挤度预测,为火车旅客提供服务
Real-time congestion prediction for train passengers.
使用无服务器的Azure技术为我们的旅行规划应用提供流式预测
与Wessel Radstok一起

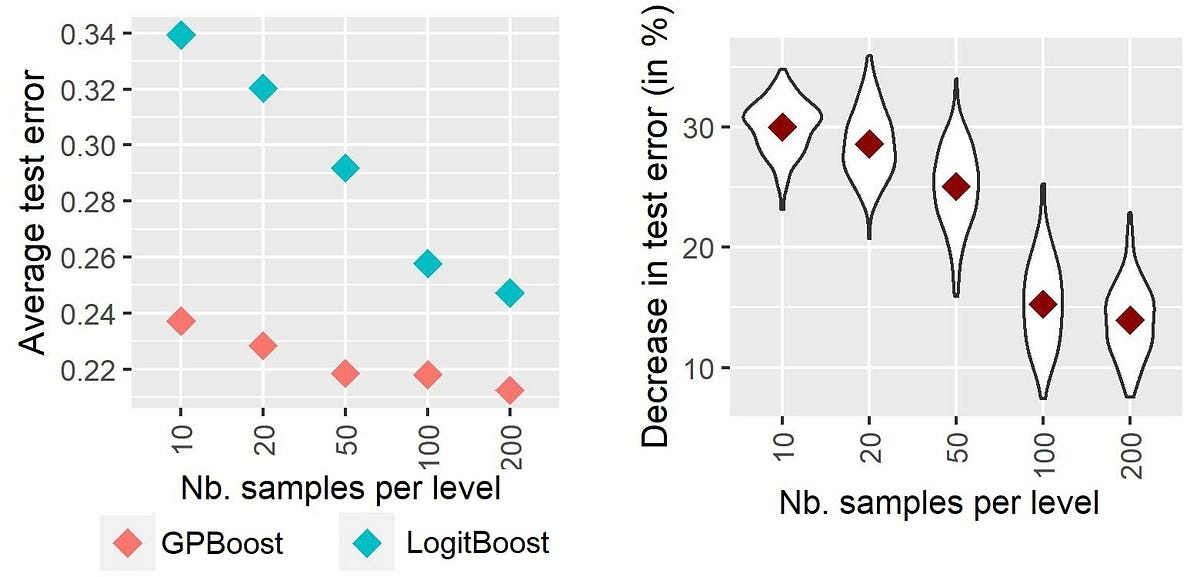
荷兰铁路上的旅客可以使用荷兰铁路机构的应用来规划他们的旅程。在规划旅程时,应用会显示有关所乘火车拥挤程度的预测。这显示为三个类别:低占用、VoAGI或高。旅客可以根据这些信息决定是否选择乘坐稍微不那么拥挤的其他火车。
这些预测是通过批处理进行的。机器学习模型定期在历史数据上进行训练,每天早上都会运行一个过程来预测未来几天的火车拥挤程度。这是通过预测预期的乘客人数并结合计划路线上的火车容量来完成的。
然而,在白天可能会发生导致火车被取消、改道的事件,或者可能计划使用双层火车,但只有单层火车可用。结果是,旅客将看到过时的拥挤程度信息。大约有20%的出发火车在旅行当天会更改容量,而且通常是在出发前不久。
在本博客中,我们将解释如何构建一个流水线,该流水线可以获取有关计划路线上的火车长度和类型的实时信息,并更新应用中的预期拥挤程度。我们采用了一个Lambda架构,其中我们的夜间预测实现了批处理层,而更新过程则实现了流处理层。该流水线目前正在生产中运行,为荷兰使用我们的应用的所有火车旅客提供了更实时的预期拥挤程度。
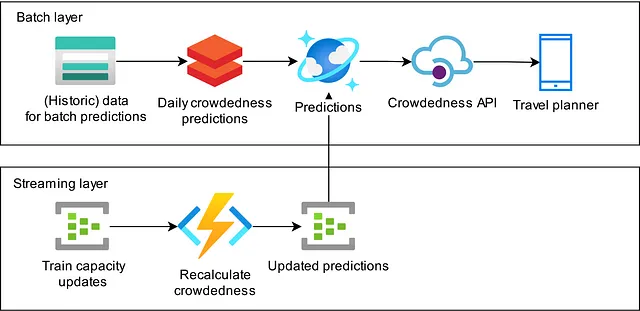
我们描述了我们采取的实现此架构的方法。我们最初的实现使用Spark Structured Streaming完成,但结果并不如我们预期的那样。基于我们的经验,我们决定采用Azure云中的无服务器资源的不同方法。
第一次尝试:Spark Structured Streaming
我们的每日拥挤程度预测在Databricks上使用Spark进行数据处理。由于Spark支持流数据处理,所以在Spark Structured Streaming中实现我们的预测的实时更新似乎是合乎逻辑的选择。这个决定给我们带来了一个优势,即该平台已经可用,我们可以使用我们已经有经验的DataFrame范式来实现逻辑。
我们从一个批处理版本的模型开始,将其转换为纯Spark Structured Streaming实现。我们最终得到了一个小笔记本来启动流处理作业,以及一个包含我们所需逻辑的自定义Python包。
在开发过程中,我们对使用Structured Streaming编程学到了几件事。首先,SQL DataFrames和Structured Streaming DataFrames的编程接口不同。在功能上,Structured Streaming受限制得多,这意味着我们无法将批处理模型一对一地以流式方式实现,我们不得不多次修改算法使其正常工作。Structured Streaming接口的有限表达能力导致的代码难以阅读,因此难以维护。
一个简单的例子是,我们想要基于时间窗口对两个数据流执行外连接。然而,Spark结构化流需要在连接条件中具有相等性,而我们没有两个具有相同数据的列。我们尝试为相等性添加两个具有相同值的文字字段到两个流中,但是Spark不那么容易被愚弄。我们最终创建了一个“千年”字段作为我们的时间戳都在第三个千年:这个方法有效,但实际上我们创建了一个“Y3K”错误。
此外,我们不得不将算法分为独立的步骤,因为模型的不同部分有不同的时间约束,我们无法在单个结构化流作业中实现这些约束。我们选择将模型拆分为几个部分,并使用Azure事件中心作为持久性存储层进行耦合。这样做的好处是每个处理部分都有一个明确的目标,并且可以单独进行测试。
我们以两种方式测试了我们的流程。对于单元测试,我们只需将流处理逻辑与手工制作的批处理Spark SQL数据框进行配对即可进行测试。这意味着我们可以在不实际启动流处理作业的情况下测试流程的一部分。这种方法可以捕捉到很多功能要求,但不会捕捉到任何时间问题。第二个测试步骤使用了Spark结构化流的内存接收器以流式模式运行查询,以捕捉一些时间效应。
最终,我们部署了我们的代码,看到我们的云费用大幅增加。我们找到了两个原因:首先,Databricks是批量分析作业的一个很好的解决方案,但连续运行用于流处理作业会很昂贵。其次,我们雇主的信息安全政策要求我们记录数据访问。由于结构化流的状态存储可能包含数据,我们也必须记录这些数据。然而,状态存储经常更新并包含许多小文件,这导致了一组昂贵的日志。
最终,我们决定放弃这种方法。我们的云成本对于我们试图解决的问题来说太高了。再加上模型实现非常难以理解和维护,因为Spark结构化流的表达能力有限,这使我们得出结论,我们不想进一步改进这种方法,而是看看是否可以以不同的方式解决这个问题。
使用无服务器技术重新设计
我们注意到流程的许多部分不需要状态,于是我们选择了一种使用Azure Functions作为计算平台的系统,以便可以单独处理每个消息。在需要状态的地方,我们使用流分析。这使我们可以比较消息、重播消息或将其与另一个流连接起来。为了快速访问辅助数据,我们使用了Cosmos数据库。我们仍然使用Azure事件中心将所有部分连接在一起。

Azure Functions
Azure Functions是一种将操作应用于事件流的简单方法。它们为流中的每个事件单独调用,这使得对业务逻辑进行推理变得容易。它们对Python有原生支持,使得编写可维护的操作变得容易。由于平台管理了所有的云连接样板代码,它们可以很容易地在本地进行开发和测试。我们在流程的各个部分中使用它们:
- 一些函数仅过滤传入的消息,减少后续步骤的计算负载,从而减少容量和成本;
- 几个函数通过将它们与其他数据源(例如Cosmos DB)连接来充实消息;
- 其他函数将消息从一种格式转换为最终输出格式;
- 最后,我们使用Azure Functions将批处理层的数据引入流处理层。
过滤、丰富和转换
执行这些步骤的函数是简单的Python代码。例如,过滤函数的主要部分只有几行:
def main(event: func.EventHubEvent, evh: func.Out[bytes]) -> None: """ 仅发送与我们的流程相关的消息。 """ message = json.loads(event.get_body().decode("utf-8")) if _is_ns_operator(message): message = _remove_keys(message) message = _add_build_id(message) evh.set(str.encode(json.dumps(message)))清单1:过滤和转换消息的示例Azure函数代码。
在这里,我们对每条消息进行过滤,仅保留与我们公司运营的列车相关的消息,并从我们不感兴趣的消息中删除键(数据字段)。最后,我们为消息添加一个构建ID元数据,以便我们有一些用于调试目的的跟踪信息。对于感兴趣的读者,JSON字符串被编码为使用str.encode() 的Bytes对象。如果将常规字符串发送到事件中心,则会自动进行漂亮的打印,这会在消息中引入大量的空格。Bytes对象保持不变地发送。
将数据摄入到快速的Cosmos数据库中
为了重新计算列车拥挤度,需要快速访问列车中预测的旅客数量、新滚动股的容量以及低、VoAGI和高分类的边界。这些数据作为批处理过程的一部分每天生成,并以parquet格式写入我们的数据湖中。每次重新计算操作都从数据湖加载这些数据太慢了。我们利用Azure Cosmos数据库键值存储,以低延迟为Azure函数重新计算列车拥挤度提供所需的静态数据。
理想情况下,我们从每晚的批处理过程触发摄入,并且还可以接收摄入是否成功或失败的信息。摄入过程还需要能够读取具有复杂类型的parquet文件,而Azure Data Factory复制活动不再支持这一功能。我们的解决方案是利用Azure Durable Functions。这是标准Azure函数平台的扩展,它使得有状态的长时间运行函数成为可能。具体而言,可靠函数支持Webhooks,这使我们能够返回信息给编排程序,以便通知摄入是否成功。
摄入的工作流程如下。每晚的批处理过程触发一个可靠函数。该可靠函数为需要摄入的数据源选择正确的活动函数,并为每个可用的parquet文件触发此活动。然后,我们使用pandas读取每个文件,执行一些简单的转换,并将记录批量插入到Cosmos数据库中。可靠函数会自动跟踪任何故障,并重试该函数。
Azure流分析
某些操作在Azure函数中无法轻松执行。这主要适用于有状态操作或将消息在时间窗口内组合的操作。
我们的每日拥挤度预测是在批处理过程中完成的,它不会即时计算预测结果。这需要一些时间,在此期间可能会发生列车容量的新更新。如果发生这种情况,我们希望先在最新的先前预测上更新拥挤度,然后在新的预测结果可用时再次更新。我们在此处使用Azure流分析来保持更新消息的状态,并在新的批处理预测可用时从某个时间戳开始重放这些消息。
Azure流分析查询是用SQL方言编写的。实现转换相对简单。但是,当消息吞吐量需要很高时,需要注意一些问题。在我们的情况下,直接实现无法跟上输入流,因此我们必须确保流分析查询能够以尴尬地并行方式运行。
尴尬地并行查询具有一些要求和限制。它们需要处理分区数据,并且需要在分区内执行有状态操作(例如连接操作)。这意味着当连接两个事件中心流时,它们必须具有相同数量的分区,并且第一个事件中心的分区1的数据只能与第二个事件中心的分区1的数据进行连接。
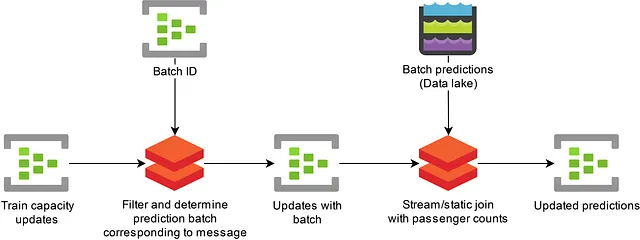
为了解决这个问题,我们在多个事件中心分区上复制了一些数据,并实际上实施了广播连接操作。我们在以下查询中说明了这一点。在这里,我们的每个拥挤度预测都被赋予了一个批次ID和批次开始时间,用于决定哪条列车容量更新消息适用于哪个预测。如果消息在计算新一组预测的过程中到达,则一条消息可能适用于多个预测。在这种情况下,会输出多条消息。每个批次ID都在多个事件中心分区上复制。
SELECT batchid.batch_id, batchid.batch_start_time, event.message, event.message_timestamp INTO [Target] FROM [SourceData] event TIMESTAMP BY event.message_timestamp PARTITION BY PartitionId JOIN [BatchId] batchid TIMESTAMP BY batchid.EventEnqueuedUtcTime PARTITION BY PartitionId ON -- 如果批次ID消息在消息之前接收到(正DATEDIFF),且 -- 当回放时,如果批次ID消息在消息之后接收到(负DATEDIFF), -- 但仅当消息在批次开始时间之后入队时。 -- 为了允许快速重新摄入数据,我们丢弃不再适用于批次的消息 DATEDIFF(HOUR, batchid, event) BETWEEN - 24 AND 24 AND CAST(batchid.batch_start_time AS datetime) <= CAST(event.message_timestamp AS datetime) AND CAST(event.message.valid_until AS datetime) >= CAST(batchid.batch_start_time AS datetime) AND event.PartitionId = batchid.PartitionId代码清单2:Azure Stream Analytics查询示例,为每条消息添加相应的批次ID。
端到端集成测试
从项目的最初提交开始,我们决定对流式处理流程进行自动化的端到端集成测试。这些测试的形式是使用我们生成的示例消息填充入口事件中心,然后验证输出事件中心创建的消息。我们还将Cosmos数据库摄入包括在这个集成测试流程中。将这些测试作为我们持续部署的一部分,使我们在进行更改时有了极高的信心,因为流程中的组件数量增加,复杂性也随之增加。
结论和主要经验教训
为了让我们的火车旅客在列车服务发生变化时也能获得最新的拥挤程度信息,我们采用了Lambda架构,在列车容量变化时更新我们的预测。
我们最初使用的Spark Structured Streaming的实现效果不如预期,因此我们转而使用Azure Event Hubs、Azure Functions、Azure Stream Analytics和Azure Cosmos DB的无服务器架构。
这种方法的主要优点包括:
- 作为开发人员,您可以控制整个过程:清楚地知道哪些部分表现不佳,哪些部分产生了最高的成本;
- 与Spark Structured Streaming相比,Azure Functions中的纯Python代码可读性、可维护性和表达性更好;
- Azure Functions对于无状态操作来说是廉价的;
- Azure Streaming Analytics是最昂贵的部分,只有在有必要时才应使用(有状态或时间窗口操作);
- 新的解决方案显著降低了云基础设施成本。
主要缺点:
- 使用Azure Functions和Azure Cosmos DB等解耦的组件可能会导致竞争条件,如果设计不考虑得很好;
- 需要管理许多基础设施和小段的代码:逻辑不集中在一个地方,需要进行更广泛的测试。