高基数分类变量的混合效应机器学习 —— 第一部分:不同方法的实证比较
High-dimensional mixed effects machine learning for categorical variables - Part 1 Empirical comparison of different methods.
为什么随机效应对于机器学习模型很有用
高基数分类变量是指其不同级别的数量相对于数据集的样本量较大,换句话说,每个分类变量级别的数据点较少。机器学习方法在处理高基数变量时可能会遇到困难。在本文中,我们认为随机效应是在机器学习模型中对高基数分类变量进行建模的有效工具。具体而言,我们通过使用多个表格数据集与高基数分类变量,对两种最成功的机器学习方法,树提升和深度神经网络,以及线性混合效应模型进行了实证比较。我们的结果表明,首先,具有随机效应的机器学习模型表现更好,其次,具有随机效应的树提升模型优于具有随机效应的深度神经网络。
目录
· 1 引言 · 2 用于建模高基数分类变量的随机效应 · 3 使用真实数据集的不同方法的比较 · 4 结论 · 参考文献
1 引言
处理分类变量的一个简单策略是使用独热编码或虚拟变量。但是,由于以下原因,这种方法通常对于高基数分类变量效果不佳。对于神经网络,经常采用的解决方案是实体嵌入 [Guo and Berkhahn, 2016],它将分类变量的每个级别映射到低维欧几里得空间。对于树提升,一种简单的方法是为分类变量的每个级别分配一个数字,然后将其视为一维数值变量。LightGBM提升库 [Ke et al., 2017] 中实现的另一种方法是在构建树的算法中使用近似方法 [Fisher, 1958],将所有级别分为两个子集。此外,CatBoost提升库 [Prokhorenkova et al., 2018] 使用基于使用训练数据的随机分区计算的有序目标统计量的方法来处理分类预测变量。
2 用于建模高基数分类变量的随机效应
随机效应可以作为对高基数分类变量进行建模的有效工具。在单个高基数分类变量的回归情况下,随机效应模型可以写为
- MIT科学家们构建了一个能够为生物学研究生成AI模型的系统
- 认识JourneyDB:一个包含400万多样化和高质量生成图像的大规模数据集,旨在为多模态视觉理解而精心策划
- 这篇AI论文介绍了DreamDiffusion:一种通过脑电图信号直接生成高质量图像的思维转图模型
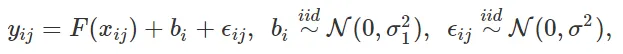
其中 j=1,…,ni 是在级别 i 中的样本索引,ni 是分类变量取得级别 i 的样本数,i 表示级别,q 表示分类变量的总级别数。因此,样本总数为 n = n0 + n1 + … + nq。这样的模型也被称为混合效应模型,因为它包含固定效应 F(xij) 和随机效应 bi。xij 是固定效应预测变量或特征。混合效应模型可以扩展到其他响应变量分布(例如分类)和多个分类变量。
传统上,在线性模型中使用随机效应,其中假设 F 是线性函数。在过去的几年中,线性混合效应模型已经被扩展到非线性模型,使用随机森林 [Hajjem et al., 2014]、树提升 [Sigrist, 2022 , 2023a ],以及最近(以第一篇公开预印本为准)深度神经网络 [Simchoni and Rosset, 2021 , 2023 ]。与传统的独立机器学习模型相比,随机效应引入了样本之间的相关性。
为什么对于高基数的分类变量,随机效应很有用?
对于高基数的分类变量,每个级别的数据很少。直观地说,如果响应变量在许多级别上有不同的(条件)均值,传统的机器学习模型(如独热编码、嵌入或简单的一维数值变量)可能在处理此类数据时存在过拟合或欠拟合的问题。从经典的偏差-方差权衡的角度来看,独立的机器学习模型可能很难平衡这种权衡并找到适当的正则化量。例如,可能会发生过拟合,这意味着模型的偏差较低但方差较高。
广义地说,随机效应充当一个先验或正则化器,用于模拟函数中的难以处理的部分,即其“维度”与总样本量类似的部分,并通过这样做来提供一种有效的方法来平衡过拟合和欠拟合或偏差和方差之间的关系。例如,对于单个分类变量,随机效应模型会将组截距效应的估计值收缩到全局均值。这个过程有时也被称为“信息汇聚”。它代表了完全忽略分类变量(欠拟合/高偏差和低方差)和在估计中给予分类变量的每个级别“完全自由”(过拟合/低偏差和高方差)之间的权衡。重要的是,正则化的程度由模型的方差参数从数据中学习得到。具体来说,在上述单层随机效应模型中,对于具有预测变量xp和分类变量具有级别i的样本,响应变量的(点)预测由以下公式给出
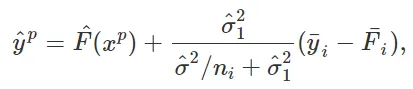
其中F(xp)是在xp处评估的训练函数,σ²_1和σ²是方差估计,yi和Fi分别是yij和F(xij)的样本均值,忽略分类变量将给出预测值yp = F(xp),没有正则化的完全灵活模型给出yp = F(xp) + ( yi — Fi)。即,这两种极端情况与随机效应模型之间的差异是收缩因子σ²_1 / (σ²/ni + σ²_1和σ²)(如果级别i的样本数量ni较大,则该因子趋近于零)。与此相关的是,随机效应模型允许更有效(即方差较低)地估计固定效应函数F(.) [Sigrist, 2022]。
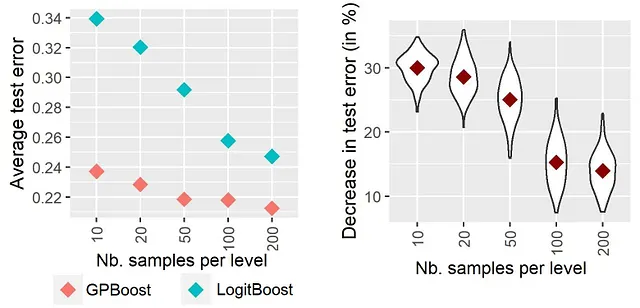
根据这个论证,Sigrist [2023a,第4.1节]在实证实验中发现,结合随机效应的树提升(“GPBoost”)相对于传统的独立树提升(“LogitBoost”)在每个分类变量级别的样本数量越低(即分类变量的基数越高)时表现得更好。这些结果在上图1中再现。这些结果是通过使用5000个样本、非线性预测函数和具有逐渐增多级别的分类变量(即每个级别的样本较少)来模拟二元分类数据获得的;有关更多细节,请参阅Sigrist [2023a]。结果显示,GPBoost和LogitBoost的测试误差差异越大,每个分类变量级别的样本越少(即级别的数量越高)。
3 使用真实数据集比较不同方法
接下来,我们使用多个具有高基数分类变量的真实数据集来比较几种方法。我们使用Simchoni和Rosset [2021, 2023]的所有公开可用的表格数据集,并采用与Simchoni和Rosset [2021, 2023]相同的实验设置。此外,我们还包括在Sigrist [2022]中分析的Wages数据集。
我们考虑以下方法:
- ‘线性’:线性混合效应模型
- ‘NN嵌入’:具有嵌入的深度神经网络
- ‘LMMNN’:结合深度神经网络和随机效应[Simchoni和Rosset,2021,2023]
- ‘LGBM_Num’:通过为每个分类变量的级别分配一个数字,并将其视为一维数值变量来进行树提升
- ‘LGBM_Cat’:使用
LightGBM[Ke等人,2017]中的方法来进行树提升的分类变量 - ‘CatBoost’:使用
CatBoost[Prokhorenkova等人,2018]中的方法来进行树提升的分类变量 - ‘GPBoost’:结合树提升和随机效应[Sigrist,2022,2023a]
请注意,最近的版本(1.6及更高版本)中,XGBoost库[Chen和Guestrin,2016]也实现了与LightGBM相同的处理分类变量的方法。我们在此不将此视为一个单独的方法。
我们使用以下数据集:
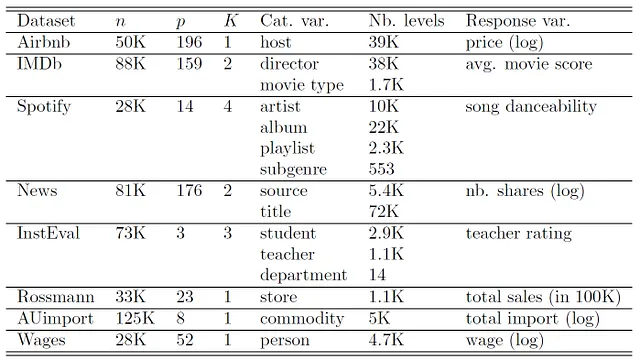
对于所有具有随机效应的方法,我们在表1中提到的每个分类变量中包括随机效应,随机效应之间没有先验相关性。Rossmann、AUImport和Wages数据集是纵向数据集。对于这些数据集,我们还包括线性和二次随机斜率;请参阅本系列的(未来)第三部分。有关数据集的详细信息,请参阅Simchoni和Rosset [2021, 2023]以及Sigrist [2023b]。
我们对每个数据集进行5折交叉验证(CV),使用测试均方误差(MSE)来衡量预测准确性。有关实验设置的详细信息,请参阅Sigrist [2023b]。有关如何预处理数据以及如何下载数据和运行实验的代码的说明,请在此处找到。对于原始来源许可证允许的数据集,模型化的预处理数据也可以在上述网页中找到。
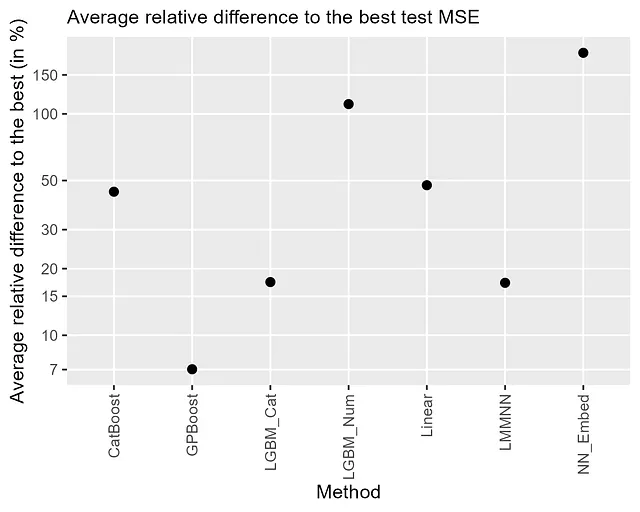
结果总结在图2中,显示了与最低测试MSE的平均相对差异。首先,对于每个数据集,首先计算方法的测试MSE与最低MSE的相对差异,然后对所有数据集取平均值。详细结果可以在Sigrist [2023b]中找到。我们观察到,结合树提升和随机效应(GPBoost)具有最高的预测准确性,与最佳结果的平均相对差异约为7%。第二好的结果是LightGBM的分类变量方法(LGMB_Cat)和具有随机效应的神经网络(LMMNN),两者相对于最佳方法的平均相对差异约为17%。CatBoost和线性混合效应模型的表现要差得多,相对于最佳方法的平均相对差异接近50%。考虑到CatBoost“试图解决分类特征”(截至2023年7月6日的维基百科),这有些令人沮丧。总体而言,具有嵌入的神经网络的表现最差,与最佳结果的平均相对差异超过150%。将分类变量转换为一维数值变量的树提升(LGBM_Num)稍微好一些,与最佳结果的平均相对差异约为100%。在其在线文档中,LightGBM建议“对于基数较高的分类特征,将其视为数值特征效果最好”(截至2023年7月6日)。我们明显得出了不同的结论。
4 结论
我们在具有高基数分类变量的表格数据上进行了实证比较多种方法。我们的结果显示,首先,具有随机效应的机器学习模型比没有随机效应的模型表现更好;其次,具有随机效应的树提升的性能优于具有随机效应的深度神经网络。虽然对于后一项发现可能有几个可能的原因,但这与Grinsztajn等人的最新研究结果[2022]一致,他们发现树提升在没有高基数分类变量的表格数据上优于深度神经网络(以及随机森林)。同样,Shwartz-Ziv和Armon [2022]得出结论,树提升“在表格数据上优于深度模型。”
在本系列的第二部分中,我们将展示如何使用 GPBoost 库来应用其中一个上述提到的真实数据集的演示。在第三部分中,我们将展示如何使用 GPBoost 库对纵向数据,也就是面板数据进行建模。
参考文献
- T. Chen 和 C. Guestrin. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794. ACM, 2016.
- W. D. Fisher. On grouping for maximum homogeneity. Journal of the American statistical Association, 53(284):789–798, 1958.
- L. Grinsztajn, E. Oyallon, 和 G. Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data? In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, 和 A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 507–520. Curran Associates, Inc., 2022.
- C. Guo 和 F. Berkhahn. Entity embeddings of categorical variables. arXiv preprint arXiv:1604.06737, 2016.
- A. Hajjem, F. Bellavance, 和 D. Larocque. Mixed-effects random forest for clustered data. Journal of Statistical Computation and Simulation, 84(6):1313–1328, 2014.
- G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, 和 T.-Y. Liu. LightGBM: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems, pages 3149–3157, 2017.
- L. Prokhorenkova, G. Gusev, A. Vorobev, A. V. Dorogush, 和 A. Gulin. CatBoost: unbiased boosting with categorical features. In Advances in Neural Information Processing Systems, pages 6638–6648, 2018.
- R. Shwartz-Ziv 和 A. Armon. Tabular data: Deep learning is not all you need. Information Fusion, 81:84–90, 2022.
- F. Sigrist. Gaussian Process Boosting. The Journal of Machine Learning Research, 23(1):10565–10610, 2022.
- F. Sigrist. Latent Gaussian Model Boosting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):1894–1905, 2023a.
- F. Sigrist. A Comparison of Machine Learning Methods for Data with High-Cardinality Categorical Variables. arXiv preprint arXiv::2307.02071 2023b.
- G. Simchoni 和 S. Rosset. Using random effects to account for high-cardinality categorical features and repeated measures in deep neural networks. Advances in Neural Information Processing Systems, 34:25111–25122, 2021.
- G. Simchoni 和 S. Rosset. Integrating Random Effects in Deep Neural Networks. Journal of Machine Learning Research, 24(156):1–57, 2023.