宣布首次机器反学习挑战
Announce the first machine anti-learning challenge.
由Google的研究科学家Fabian Pedregosa和Eleni Triantafillou发布
深度学习最近在各种应用中取得了巨大的进展,从逼真的图像生成和令人印象深刻的检索系统到能够进行类似人类对话的语言模型。尽管这一进展非常令人兴奋,但广泛使用深度神经网络模型需要谨慎:根据Google的AI原则,我们致力于负责任地开发AI技术,了解和减轻潜在风险,例如不公平偏见的传播和放大以及保护用户隐私。
完全消除要删除的数据的影响是具有挑战性的,因为除了从存储它的数据库中简单删除它之外,还需要消除该数据对其他工件(例如经过训练的机器学习模型)的影响。此外,最近的研究[1,2]表明,在某些情况下,可能可以使用成员推断攻击(MIAs)以高准确度推断出一个示例是否用于训练机器学习模型。这可能引起隐私问题,因为这意味着即使个人数据从数据库中删除,仍然可能推断出个人数据是否用于训练模型。
鉴于上述情况,机器取消学习是机器学习的新兴子领域,旨在从经过训练的模型中删除特定子集的训练示例(即“遗忘集”)的影响。此外,理想的取消学习算法将消除某些示例的影响,同时保持其他有益属性,例如对其余训练集的准确性和对保留示例的泛化能力。生成这种取消学习模型的一种简单方法是在调整后的训练集上重新训练模型,该训练集不包括遗忘集中的样本。然而,由于重新训练深度模型可能会消耗大量计算资源,因此这并不总是可行的选择。理想的取消学习算法将使用已经训练好的模型作为起点,并有效地进行调整以消除所请求数据的影响。
今天,我们非常高兴地宣布,我们与广泛的学术和工业研究人员合作,组织了第一届机器取消学习挑战赛。该竞赛考虑了一个现实场景,即在训练之后,某个训练图像的特定子集必须被遗忘,以保护相关个体的隐私或权益。竞赛将在Kaggle上举办,并且提交的作品将自动以遗忘质量和模型效用进行评分。我们希望这个竞赛将有助于推动机器取消学习技术的发展,并鼓励开发高效、有效和符合道德的取消学习算法。
机器取消学习应用
机器取消学习在保护用户隐私之外还具有其他应用。例如,可以使用取消学习从经过训练的模型中删除不准确或过时的信息(例如由于标签错误或环境变化),或者删除有害、操纵或离群数据。
机器取消学习领域与差分隐私、终身学习和公平性等机器学习领域相关。差分隐私旨在确保没有特定的训练示例对训练的模型具有过大的影响;这是与取消学习相比更强的目标,取消学习仅要求消除指定的遗忘集的影响。终身学习研究旨在设计能够持续学习并保持先前获取的技能的模型。随着取消学习的进展,它还可能为改善模型的公平性提供额外的方法,例如纠正不公平的偏见或对属于不同群体(例如人口统计学、年龄组等)的成员的不公平处理。
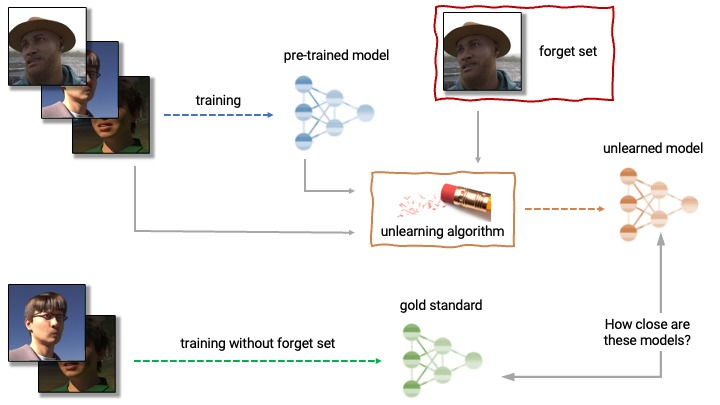 |
| 取消学习的解剖。取消学习算法以预训练模型和一个或多个要取消学习的训练集样本(即“遗忘集”)作为输入。从模型、遗忘集和保留集中,取消学习算法生成一个更新的模型。理想的取消学习算法产生的模型与没有遗忘集进行训练的模型无法区分。 |
机器遗忘的挑战
遗忘问题复杂多样,涉及到几个相互冲突的目标:遗忘请求的数据、保持模型的效用(例如在保留和保留外数据上的准确性)和效率。因此,现有的遗忘算法做出了不同的权衡。例如,完全重新训练可以实现成功的遗忘而不损害模型的效用,但效率较低,而向权重添加噪声可以在损害效用的情况下实现遗忘。
此外,文献中对遗忘算法的评估目前存在高度不一致。一些作品报告了对要遗忘的样本的分类准确率,另一些报告了与完全重新训练模型的距离,还有一些使用成员推理攻击的错误率作为遗忘质量的度量标准[4, 5, 6]。
我们认为评估指标的不一致性和缺乏标准化的协议是该领域进展的严重障碍——我们无法直接比较文献中不同的遗忘方法。这使我们对不同方法的相对优点和缺点以及开放的挑战和机会有了狭隘的看法。为了解决评估的不一致性问题,并推进机器遗忘领域的最新技术,我们与一大批学术和工业研究人员合作组织了第一届遗忘挑战赛。
宣布第一届机器遗忘挑战赛
我们很高兴宣布第一届机器遗忘挑战赛,该赛事将作为NeurIPS 2023竞赛专题的一部分举行。比赛的目标是双重的。首先,通过统一和标准化遗忘的评估指标,我们希望通过苹果对苹果的比较来确定不同算法的优势和劣势。其次,通过向所有人开放此竞赛,我们希望促进创新解决方案,并揭示开放的挑战和机会。
该比赛将在Kaggle上举办,时间为2023年7月中旬至2023年9月中旬。作为比赛的一部分,我们今天宣布了起始工具包的可用性。这个起始工具包为参与者在玩具数据集上构建和测试他们的遗忘模型提供了基础。
该比赛考虑了一个现实场景,即已经在面部图像上训练了一个年龄预测器,并且在训练之后,必须忘记训练图像的某个子集以保护相关个人的隐私或权利。为此,我们将作为起始工具包的一部分提供一个合成面部数据集(如下所示的样本),并且我们还将使用几个真实面部数据集来评估提交的结果。参赛者被要求提交代码,该代码以训练的预测器、遗忘和保留集作为输入,并输出一个已经遗忘指定遗忘集的预测器的权重。我们将根据遗忘算法的效力和模型效用评估提交的结果。我们还将强制执行一个硬性截止时间,拒绝运行速度比重新训练的时间慢的遗忘算法。该比赛的一个有价值的成果将是对不同遗忘算法的权衡进行表征。
 |
| 从面部合成数据集中摘录的图像,附有年龄注释。比赛考虑了这样一种情况:在上述面部图像上已经训练了一个年龄预测器,在训练之后,必须忘记训练图像的某个子集。 |
为了评估遗忘,我们将使用受MIAs启发的工具,例如LiRA。MIAs最初是在隐私和安全领域中开发的,它们的目标是推断哪些示例是训练集的一部分。直观地说,如果遗忘成功,遗忘的模型不包含已遗忘示例的痕迹,导致MIAs失败:攻击者将无法推断出遗忘集实际上是原始训练集的一部分。此外,我们还将使用统计测试来量化特定提交的遗忘算法产生的未学习模型的分布与从头重新训练的模型的分布有多不同。对于理想的遗忘算法,这两者将是无法区分的。
结论
机器去学习是一种强大的工具,有潜力解决机器学习中的几个开放性问题。随着对这一领域的研究不断深入,我们希望能看到更高效、更有效、更负责任的新方法。我们很高兴通过这次比赛有机会引起对这个领域的兴趣,并期待与社区分享我们的见解和发现。
致谢
本文的作者现在是Google DeepMind的一员。我们代表Unlearning Competition的组织团队撰写这篇博客文章:Eleni Triantafillou*、Fabian Pedregosa*(*相同贡献)、Meghdad Kurmanji、Kairan Zhao、Gintare Karolina Dziugaite、Peter Triantafillou、Ioannis Mitliagkas、Vincent Dumoulin、Lisheng Sun Hosoya、Peter Kairouz、Julio C. S. Jacques Junior、Jun Wan、Sergio Escalera和Isabelle Guyon。





