Learn more about Categorical Data
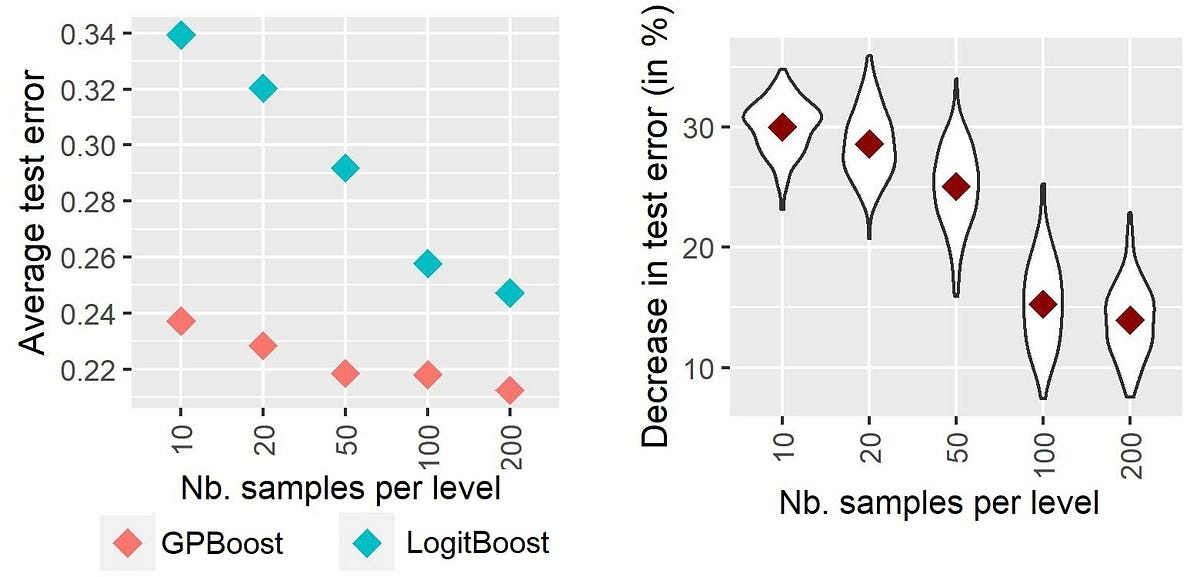
高基数分类变量的混合效应机器学习 —— 第一部分:不同方法的实证比较
机器学习中的随机效应:更好地对高基数分类变量进行建模——方法介绍与比较

- You may be interested
- DAE对话:使用扩散自编码器实现高保真度的...
- 如何创建热力图
- Microsoft研究员提出的PIT(排列不变转换...
- 用Python进行的基于量化匹配的概率机器学...
- Meta发布了更强大的人工智能技术,并不担...
- 全栈7步MLOps框架
- 回填技巧: 提升数据工程专业知识
- 使用FastAPI、AWS Lambda和AWS CDK部署大...
- Voxel51开源VoxelGPT:一种利用GPT-3.5的...
- 利用Langchain的聊天机器人解决方案强化多...
- Python 基础 语法、数据类型和控制结构
- 贝叶斯统计与频率派统计在数据科学中的应用
- 变形金刚可以生成NFL比赛:介绍QB-GPT
- “SQL中掌握移动平均和累计总和的简易指南”
- 顶级人工智能(AI)内容检测工具

