Barkour:用四足机器人进行动物级敏捷性基准测试
由Google研究科学家Ken Caluwaerts和Atil Iscen发布
创建表现出与动物或人类类似的强大且动态的运动能力的机器人一直是机器人界的一个长期目标。除了快速高效地完成任务外,敏捷性还使得腿部机器人能够在本来难以穿越的复杂环境中移动。Google的研究人员已经在多年和各种形态的机器人中追求敏捷性。然而,虽然研究人员已经使机器人越过了一些障碍物,但仍然没有普遍接受的全面衡量机器人敏捷性或机动性的基准。相反,基准测试是机器学习发展的驱动力,例如计算机视觉的ImageNet和强化学习的OpenAI Gym。
在“Barkour:使用四足机器人对动物级别的敏捷性进行基准测试”中,我们介绍了Barkour敏捷性基准测试以及基于Transformer的通用运动策略。受狗狗敏捷比赛的启发,一个有腿的机器人必须按顺序展示各种技能,包括朝不同方向移动,在不平坦的地形上穿行,并在有限的时间内跳过障碍物,以成功完成基准测试。通过提供多样化且具有挑战性的障碍物课程,Barkour基准测试鼓励研究人员开发可以以可控且多功能的方式快速移动的运动控制器。此外,通过将绩效度量与真实狗狗表现相关联,我们提供了一种直观的度量方式,以了解机器人性能与它们的动物对应物之间的关系。
| 我们邀请了一些Dooglers尝试障碍课程,以确保我们的敏捷目标是现实和具有挑战性的。小型狗完成障碍课程约需10秒,而我们机器人的典型表现大约为20秒。 |
Barkour基准测试
Barkour评分系统使用每个障碍物和整个课程的目标时间,基于新手敏捷比赛中小型狗的目标速度(约为1.7m/s)。Barkour得分范围从0到1,其中1表示机器人在约10秒的允许时间内成功穿过了沿着课程的所有障碍物,这是一个类似大小的狗穿过课程所需的平均时间。机器人跳过、失败障碍物或移动过慢都会受到惩罚。
我们的标准课程由一个5m x 5m区域内的四个独特障碍物组成。这是一个比typical dog competition更密集和更小的设置,以便在机器人实验室中轻松部署。从起始桌开始,机器人需要穿过一组杆子,爬上一个A形框架,跨过0.5m宽的障碍并踏上终点桌。我们选择了这些障碍物的子集,因为它们测试了多样的技能,同时保持了较小的占地面积。与真实的狗狗敏捷比赛一样,Barkour基准测试可以轻松地适应更大的课程区域,并可能包含各种障碍物和课程配置。
 |
| Barkour基准测试障碍课程设置的概述,包括织线杆、A形框架、宽跳跃和暂停桌。受狗狗敏捷比赛的启发,直观的评分机制平衡了速度、敏捷性和性能,并可以轻松地修改以包含其他类型的障碍或课程配置。 |
学习敏捷的运动技能
Barkour基准测试具有多样化的障碍和延迟奖励系统,训练一个可以完成整个障碍课程的单一策略面临着巨大的挑战。因此,为了设定一个强大的性能基准并展示基准测试在机器人敏捷性研究中的有效性,我们采用了一个学生-教师框架,结合了零-shot sim-to-real方法。首先,我们使用on-policy RL方法为不同障碍物训练单独的专家运动技能(教师)。特别地,我们利用最近大规模并行模拟的进展,为机器人提供包括行走、爬坡和跳跃策略在内的单独技能。
接下来,我们使用一种学生-教师框架训练一个单一策略(学生),该策略通过使用我们之前训练的专业技能来执行所有技能和转换。我们使用模拟回放来创建每个专业技能的状态-动作对数据集。然后将此数据集蒸馏成一个基于Transformer的通用运动策略,该策略可以处理各种地形并根据感知环境和机器人状态调整机器人步态。
 |
在部署期间,我们将能够执行多种技能的运动Transformer策略与提供基于机器人位置的速度命令的导航控制器配对。我们训练的策略根据机器人的环境表示为高程图、速度命令和机器人提供的板载传感器信息来控制机器人。
| 运动Transformer架构的部署流水线。在部署时,高级导航控制器通过向运动Transformer策略发送命令来引导真实机器人通过障碍课程。 |
当我们旨在获得最佳性能和最大速度时,稳健性和可重复性很难实现。有时,机器人在以敏捷的方式克服障碍物时可能会失败。为了处理故障,我们训练了一种恢复策略,该策略可以快速使机器人恢复站立状态,使其能够继续执行任务。
评估
我们使用自定义四足机器人评估基于Transformer的通用运动策略,并展示通过优化所提出的基准测试,我们在现实世界中为机器人获得了敏捷、稳健和多才多艺的技能。我们进一步为我们系统中各种设计选择及其对系统性能的影响提供了分析。
 |
| 用于评估的自定义机器人模型。 |
我们将专业和通用策略都部署到硬件上(零-shot sim-to-real)。机器人的目标轨迹由各种障碍物沿路点提供。在专业策略的情况下,我们使用手动调整的策略切换机制,在机器人的位置给定的情况下选择最合适的策略。
| 我们敏捷运动策略在Barkour基准测试中的典型性能。我们的自定义四足机器人通过在模拟环境中使用RL学习的各种技能,稳健地穿越了地形的障碍。 |
我们发现,我们的策略往往可以处理意外事件或硬件退化,从而获得良好的平均性能,但仍然可能出现故障。如下图所示,如果发生故障,我们的恢复策略可以快速使机器人恢复站立状态,使其能够继续执行任务。通过将恢复策略与简单的步行返回起点策略相结合,我们能够在最小干预下进行重复实验,以测量其稳健性。
| 强韧性和恢复行为的定性示例。机器人在向下走A字架后绊倒翻滚。这触发了恢复策略,使机器人能够重新站起来并继续行进。 |
我们发现,在大量评估中,单一的通用运动转换器策略和具有策略切换机制的专家策略实现了类似的性能。运动转换器策略的平均Barkour得分略低,但表现出更平滑的行为和步态转换。
| 在Barkour基准测试的大量运行中测量不同策略的强度。 |
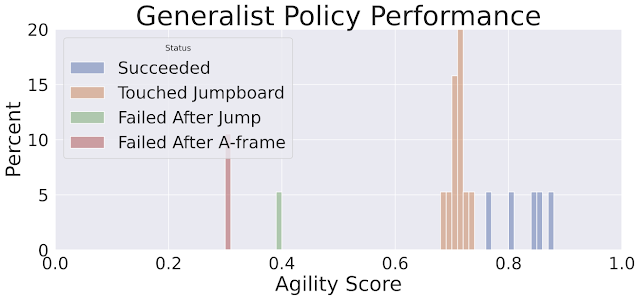 |
| 运动转换器策略的敏捷得分直方图。蓝色表示最高得分(0.75-0.9),表示机器人成功完成了所有障碍。 |
结论
我们认为,为腿式机器人开发基准测试是量化实现动物级敏捷性的重要第一步。为了建立一个强有力的基线,我们研究了一种零-shot sim-to-real方法,利用了大规模并行仿真和最近在训练基于Transformer的体系结构方面的进展。我们的研究结果表明,Barkour是一个具有挑战性的基准测试,并且可以很容易地进行定制。我们的学习方法为解决基准测试提供了一种四足机器人的单一低级别策略,可以执行各种敏捷的低级技能。
致谢
本文的作者现在是Google DeepMind的一部分。我们要感谢Google DeepMind的合作者和Google Research的合作者:余文浩,J. Chase Kew,张廷南,Daniel Freeman,李广熙,Lisa Lee,Stefano Saliceti,Vincent Zhuang,Nathan Batchelor,Steven Bohez,Federico Casarini,Jose Enrique Chen,Omar Cortes,Erwin Coumans,Adil Dostmohamed,Gabriel Dulac-Arnold,Alejandro Escontrela,Erik Frey,Roland Hafner,Deepali Jain,邝宇珩,Edward Lee,Linda Luu,Ofir Nachum,Ken Oslund,Jason Powell,Diego Reyes,Francesco Romano,Feresteh Sadeghi,Ron Sloat,Baruch Tabanpour,Daniel Zheng,Michael Neunert,Raia Hadsell,Nicolas Heess,Francesco Nori,Jeff Seto,Carolina Parada,Vikas Sindhwani,Vincent Vanhoucke和Jie Tan。我们还要感谢John Guilyard为本文中的动画创造了条件。感谢Marissa Giustina,Ben Jyenis,Gus Kouretas,Nubby Lee,James Lubin,Sherry Moore,Thinh Nguyen,Krista Reymann,Satoshi Kataoka,Trish Blazina以及Google DeepMind的机器人团队成员对该项目的贡献。
