探索营销组合建模中生成响应曲线的不同方法
比较饱和函数和偏依赖于响应曲线的生成
响应曲线是市场混合建模的一个重要组成部分,这是一种统计技术,用于分析各种营销策略和策略对销售或其他业务结果的影响。响应曲线表示营销变量(例如广告支出、价格、促销等)与产品或服务产生的销售或收入之间的关系。
响应曲线的重要性在于它们揭示了每个营销变量的有效性以及它如何对总体响应做出贡献。通过分析响应曲线,营销人员可以获得有价值的见解,了解哪些营销策略正在推动最多的销售,哪些策略没有产生预期的结果。
建立响应曲线有不同的方法,在本文中,我将探讨两种突出的方法:使用饱和变换的简单方法和基于偏依赖的方法。我使用两个不同的算法族来评估这些方法:线性回归和梯度提升。此外,我展示了当使用复杂的机器学习算法时,可以使用偏依赖方法与由SHAP值生成的响应曲线结合使用。
饱和函数/变换
建立响应曲线的简单方法涉及使用饱和函数(变换),例如Logistic、Negative Exponential或Hill。饱和函数是捕捉收益递减效应的数学函数,其中营销变量的影响随着其值的增加而饱和。通过使用饱和函数,营销变量与响应变量之间的关系可以转化为非线性形式。这使得模型能够捕捉饱和效应并更准确地表示营销努力与响应(销售或收入)之间的真实关系。
使用PyMC3建模市场混合
尝试先验、数据标准化,并将贝叶斯建模与Robyn,Facebook的开源MMM进行比较…
towardsdatascience.com
使用饱和变换的一个优点是其简单性和可解释性。响应曲线由具有固定参数的数学函数定义,结果为光滑曲线,可以轻松可视化。但是,在建模之前选择饱和函数是一个重要的考虑因素。不同的函数可能产生不同的结果,选择应基于数据的特征和模型的基本假设。
线性回归和非线性的必要性
在市场混合建模中,线性回归是一种常用的技术,用于分析营销变量和响应变量之间的关系。然而,线性回归假定预测变量和响应变量之间存在线性关系。当尝试捕捉营销数据中经常存在的非线性关系时,这可能会带来限制。
为了克服这个限制并引入非线性到建模过程中,必须将饱和函数或变换应用于营销变量。此变换允许生成一个非线性关系,否则由于线性回归的本质,该关系会是线性的。
使用平滑样条建模市场混合
捕获非线性广告饱和和递减回报,而不需要明确转换媒体变量
towardsdatascience.com
偏依赖方法
偏依赖方法是一种更通用的方法,可用于建模任何营销变量与响应之间的关系。这种方法涉及隔离一个变量的影响,同时保持所有其他变量不变。通过改变感兴趣的营销变量的值并观察相应的响应,可以创建偏依赖的绘图。
与通过饱和变换生成的光滑响应曲线不同,偏依赖方法所得到的绘图不一定是光滑的。其形状取决于基础建模算法和媒体变量与响应之间的关系。当关系是复杂和非线性时,偏依赖方法可能是有用的,它可以应用于明确使用饱和变换或当算法自然处理非线性时而不需要额外的饱和变换的情况。
利用机器学习方法改进市场组合建模
使用基于树的集成构建MMM模型并使用SHAP解释媒体渠道性能(Shapley Additive…
towardsdatascience.com
数据
我继续使用Robyn在MIT许可下提供的数据集,这些数据集与我以前的文章中的实际示例相同,并通过应用Prophet来分解趋势、季节性和假期来遵循相同的数据准备步骤。
数据集包括208周的收入(从2015年11月23日到2019年11月11日),其中包括:
- 5个媒体花费渠道:电视_S、户外_S、印刷_S、Facebook_S、搜索_S
- 2个媒体渠道还具有曝光信息(印象、点击):Facebook_I、搜索点击_P(本文未使用)
- 没有花费的有机媒体:新闻通讯
- 控制变量:事件、假期、竞争对手销售(竞争对手销售_B)
建模
我构建了一个完整的MMM管道,可以在实际场景中应用以分析媒体花费对响应变量的影响,包括以下组件:
- 具有无限衰减率(0<α<1)的Adstock变换
- 具有两个参数的饱和Hill变换:斜率/形状参数,控制曲线的陡峭程度(s>0)和半饱和点(0<k≤1)
- 来自scikit-learn的Ridge Regression
- 带有单调约束的LightGBM回归
- 基于时间的交叉验证
- Optuna超参数调整
系数说明
在scikit-learn中,Ridge Regression没有提供内置选项以强制对一些变量的系数为正。但是,一个潜在的解决方法涉及到如果发现任何媒体系数为负,则拒绝optuna解决方案。这可以通过返回一个特别大的值来实现,表示负系数是不可接受的,应从模型中排除。另一种方法可能是参考我的文章,了解如何使用Python包装R glmnet,从而使一些变量的系数受到限制。
对于Ridge Regression,我应用了饱和变换,并使用饱和函数和偏关函数方法生成响应曲线。对于LightGBM,我允许模型自然地捕捉非线性,并使用偏关函数方法生成响应曲线。 此外,我还在响应曲线上叠加SHAP值以提供进一步的洞察。
结果
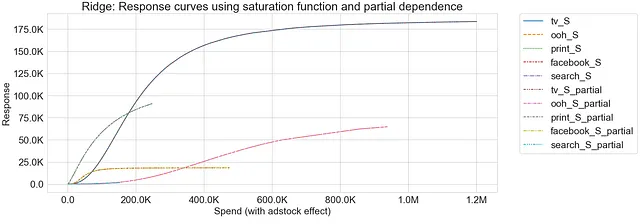
饱和变换的Ridge回归
可以看到,使用饱和函数和偏关函数生成的响应曲线都具有重叠的模式,表明两种方法捕捉到了市场变量和响应之间的相似关系。
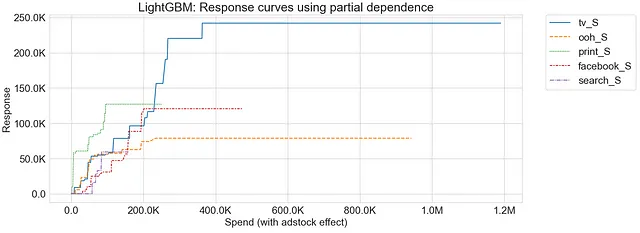
LightGBM
如前所述,使用偏关函数生成的响应曲线不一定是平滑的。其中一个原因可以归因于梯度提升算法的性质,这些算法将特征空间分成区域,并在多个决策树之间引入交互。
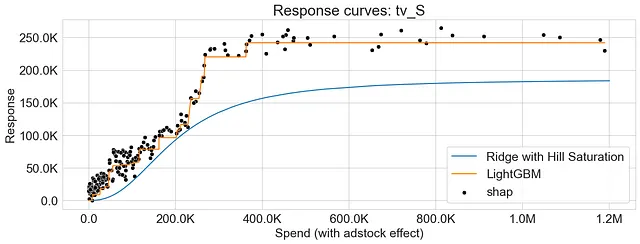
下面的图表显示了Ridge Regression和LightGBM的响应曲线,突出了两种算法在捕捉收益递减方面的差异。此外,我们观察到SHAP值提供了偏关函数方法生成的响应曲线的可靠近似。
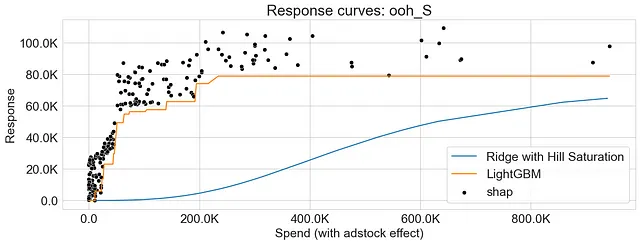
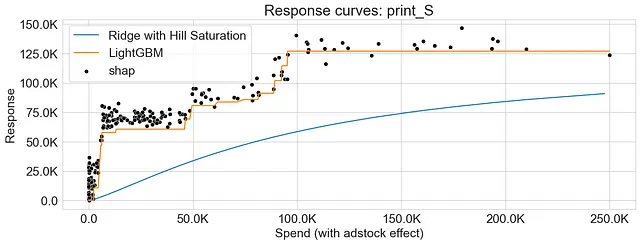
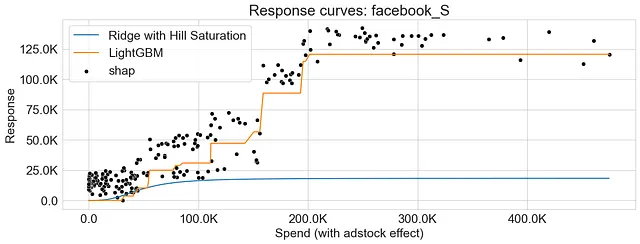
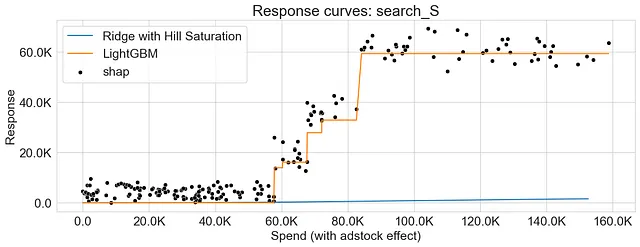
结论
响应曲线在营销组合建模中发挥着关键作用,它提供了有关不同营销变量的有效性及其对总体响应的贡献的见解。在本文中,我探讨了两种生成响应曲线的著名方法:使用饱和转换的简单方法和偏依赖方法。我使用两种算法家族,线性回归和梯度提升,评估了这些方法,并展示了不同算法捕捉非线性响应的对比方式。此外,我将使用SHAP值生成的响应与通过偏依赖方法获得的结果进行了比较。
完整代码可从我的Github库下载
感谢您的阅读!