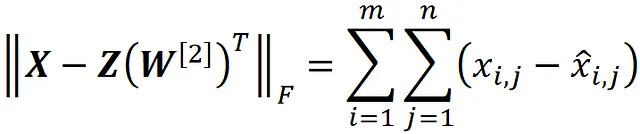深入探究自编码器及其与PCA和SVD的关系
深度探究自编码器和降维

自编码器是一种神经网络,它学习重构其输入。它由一个编码器网络和一个解码器网络组成,其中编码器网络将输入数据压缩到低维空间中,而解码器网络则从该空间重构输入数据。编码器和解码器共同训练,以最小化输入数据与其重构之间的重构误差。
自编码器可用于各种任务,例如数据压缩、去噪、特征提取、异常检测和生成建模。它们在计算机视觉、自然语言处理和语音识别等广泛领域中都有应用。自编码器还可用于降维。事实上,自编码器的主要目的之一就是学习输入数据的压缩表示,这可用作一种降维形式。
本文将讨论自编码器背后的数学原理,并探讨它们如何进行降维。我们还将研究自编码器、主成分分析(PCA)和奇异值分解(SVD)之间的关系。我们还将展示如何在Pytorch中实现线性和非线性自编码器。
自编码器架构
图1显示了自编码器的架构。如前所述,自编码器学习重构其输入数据,因此输入和输出层的大小始终相同(n)。由于自编码器学习自身输入,因此不需要标记数据进行训练。因此,它是一种无监督学习算法。
但是学习同一输入数据有什么意义呢?正如您所看到的,该架构中的隐藏层呈双面漏斗形状,从第一个隐藏层到被称为瓶颈层的层时,每层中的神经元数量都会减少。这一层具有最少的神经元数。然后,神经元的数量再次从瓶颈层增加,并以与输入层中的节点相同数量的输出层结束。重要的是要注意,瓶颈层中的神经元数量小于n。
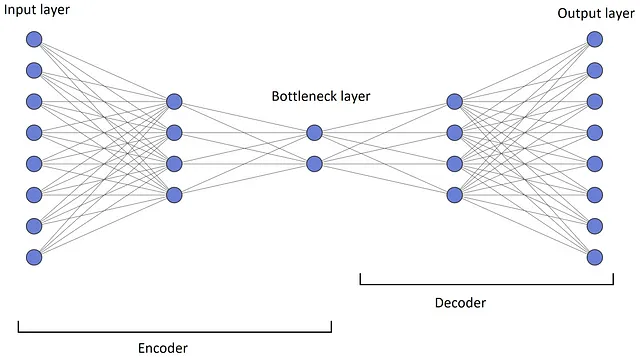
在神经网络中,每一层都学习输入空间的抽象表示,因此瓶颈层实际上是输入和输出层之间传输的信息的瓶颈。该层学习与其他层相比最紧凑的输入数据表示,并学习提取输入数据的最重要特征。这些新特征(也称为潜在变量)是将输入数据点转换为连续较低维空间的结果。事实上,潜在变量可以以更简单的方式描述或解释输入数据。瓶颈层中的神经元的输出表示这些潜在变量的值。
瓶颈层的存在是该架构的关键特征。如果网络中的所有层具有相同数量的神经元,则网络可以轻松地通过将它们全部沿网络传递来学习记忆输入数据值。
自编码器可以分为两个网络:
- 编码器网络:从输入层开始,到达瓶颈层。它将高维输入数据转换为由潜在变量形成的低维空间。瓶颈层中的神经元的输出表示这些潜在变量的值。
- 解码器网络:从瓶颈层之后开始,到达输出层。它接收来自瓶颈层的低维潜在变量的值,并从中重构原始的高维输入数据。
本文将讨论自编码器和PCA之间的相似之处。为了理解PCA,我们需要一些线性代数的概念。因此,我们首先回顾线性代数。
线性代数回顾:基、维数和秩
如果向量空间 V 由一组向量 { v ₁, v ₂, …, v_ n } 线性独立生成,则该组向量是向量空间 V 的一组基。如果一组向量线性独立,那么在该组向量中没有一个向量可以被其他向量的线性组合表示。如果一组向量 { v ₁, v ₂, …, v_ n } 能够生成向量空间,则该向量空间中的任何其他向量都可以写成该组向量的线性组合。因此,向量空间 V 中的任何向量x 都可以表示为:

其中 a₁、a₂、……、a_n 是一些常数。向量空间 V 可以有许多不同的向量基,但每个基总是具有相同数量的向量。向量空间的基向量数量称为该向量空间的维度。当所有向量均被归一化(归一化向量的长度为1)且互相垂直时,基向量 { v ₁, v ₂, …, v_ n } 称为规范正交基向量。在欧几里得空间 R² 中,向量:
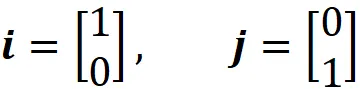
形成一个规范正交基向量,称为标准基向量。它们线性独立且可以生成 R² 中的任何向量。由于基只有两个向量,因此 R² 的维数为 2。如果我们有另一对线性独立的向量并且可以生成 R²,则该对也可以是 R² 的基。例如:
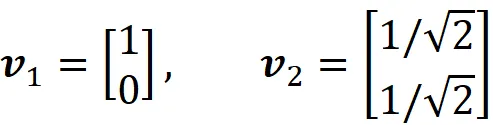
也是一组基,但不是规范正交基向量,因为这些向量不正交。更一般地,我们可以定义 R^n 的标准基向量:
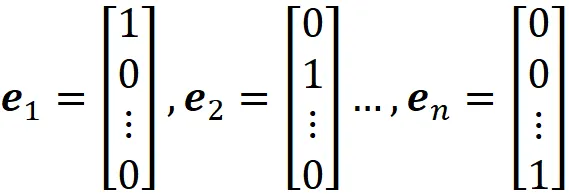
其中 eᵢ 的第 i 个元素为1,所有其他元素为零。
设向量集 B={ v ₁, v ₂, …, v_ n } 是向量空间的一组基,则可以用基向量表示该空间中的任何向量x:
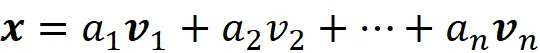
因此,相对于该基 B,向量x 的坐标可以写成:
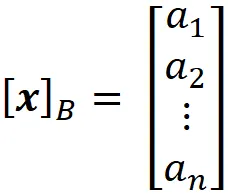
实际上,当我们定义 R² 中的一个向量时,如下所示:
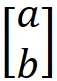
该向量的元素是相对于标准基向量的坐标:
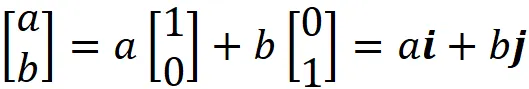
我们可以轻松地找到向量相对于另一组基的坐标。假设我们有向量:
其中 B ={ v ₁, v ₂, …, v_ n } 是一个基。现在我们可以写成:
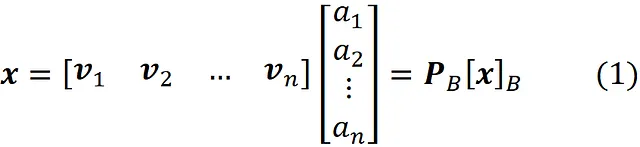
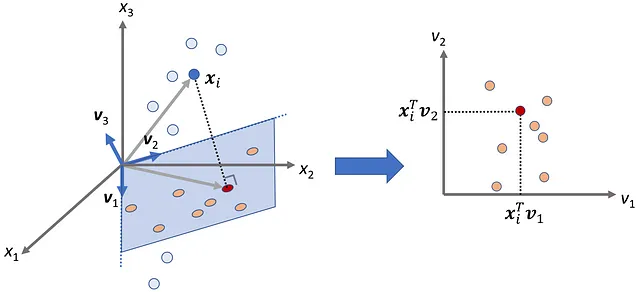
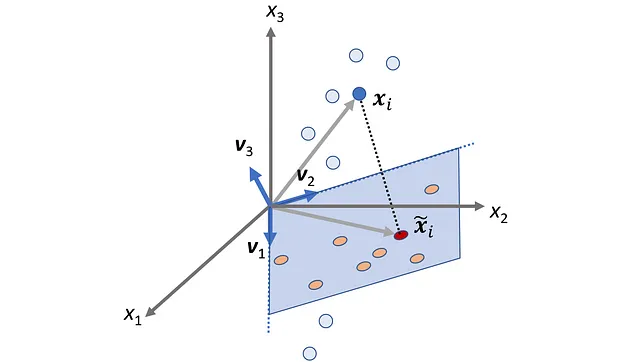
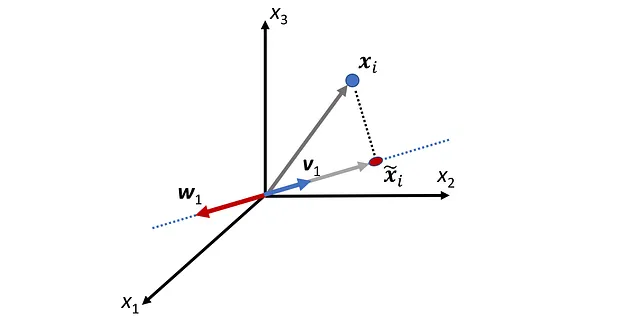
这里 P_ B 被称为坐标变换矩阵,它的列是基 B 中的向量。因此,如果我们有相对于基 B 的坐标,则可以使用等式 1 计算其相对于标准基的坐标。图 2 显示了一个例子。这里 B ={ v ₁, v ₂} 是 R² 的基。向量 x 定义如下:
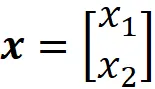
相对于 B 的 x 的坐标为:

因此,我们有:
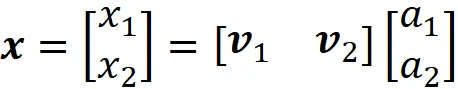
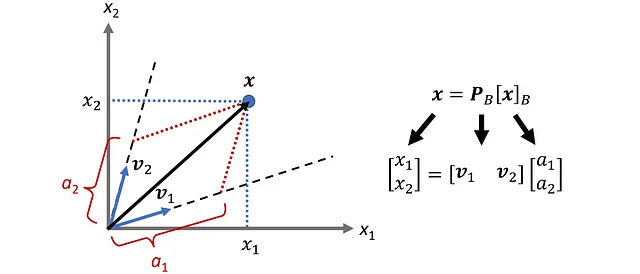
矩阵 A 的列空间(也称为 Col A)是所有列的线性组合的集合。假设我们用向量 a ₁ , a ₂ , … a_ n 表示矩阵 A 的列。现在对于任何向量如 u,Au 可以写成:
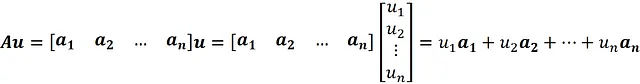
因此,Au 是 A 的列的线性组合,而列空间是可以被写成 Au 的向量的集合。
矩阵 A 的行空间是所有行的线性组合的集合。假设我们用向量 a ₁ ᵀ, a ₂ ᵀ, … a_m ᵀ 表示矩阵 A 的行:

A 的行空间是所有可以写成:
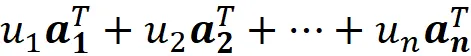
的向量的集合。
Col A 的基向量数量或 Col A 的维数被称为 A 的秩。矩阵 A 的秩还是 A 线性无关列的最大数量。也可以证明矩阵 A 的秩等于其行空间的维数,同样,它等于 A 线性无关行的最大数量。因此,矩阵的秩不能超过其行或列的数量。例如,对于一个 m × n 的矩阵,其秩不能大于 min(m, n)。
PCA:一篇综述
主成分分析(PCA)是一种线性技术。它找到数据中捕捉最多变化的方向,然后将数据投影到由这些方向张成的低维子空间上。PCA是一种广泛用于降低数据维数的方法。
PCA将数据转换为一个新的正交坐标系。该坐标系的选择是使得投影数据点到第一个坐标轴上(称为第一个主成分)的方差最大化。在第一个主成分正交的所有可能方向中,投影数据点到第二个坐标轴(称为第二个主成分)的方差最大化,更一般地,投影数据点到每个坐标轴的方差在所有正交于前一个主成分的可能方向中最大化。
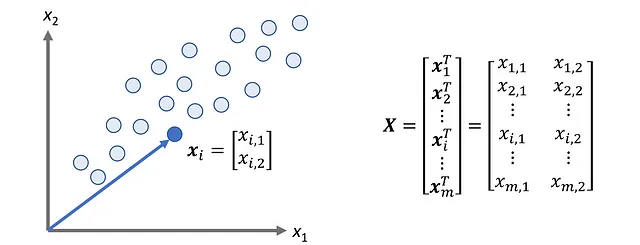
假设我们有一个具有n个特征和m个数据点或观测值的数据集。我们可以使用m×n矩阵
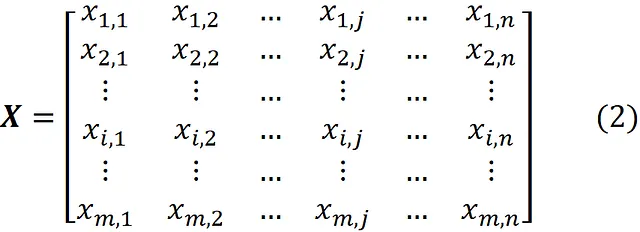
来表示这个数据集,我们称之为设计矩阵。因此,X的每一行表示一个数据点,每一列表示一个特征。我们也可以将X写成

其中每个列向量
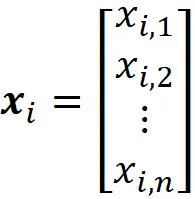
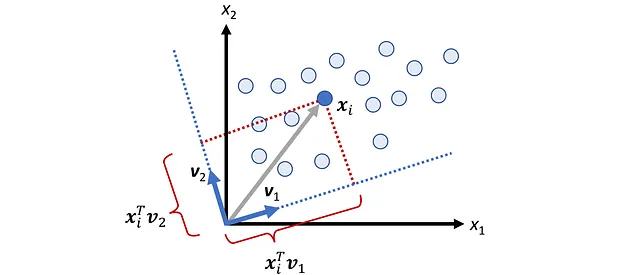
表示该数据集中的一个观测(或数据点)。因此,我们可以将我们的数据集视为R ^ n中m个向量的集合。图3显示了n = 2的示例。在这里,我们可以将每个观测作为R²中的向量(或简单地作为一个点)进行绘制。
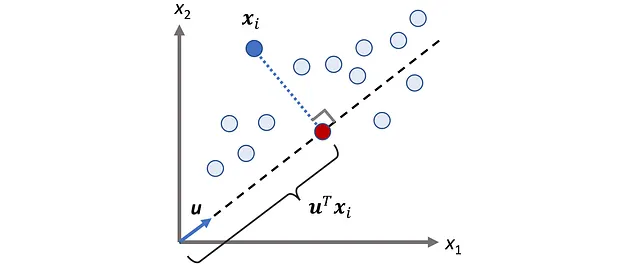
设u是一个单位向量,因此我们有:
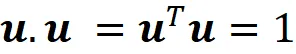
每个数据点xᵢ在向量u上的标量投影是:
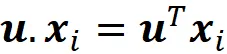
图4显示了n = 2的示例。
我们将X的每一列的平均值表示为

然后数据集的平均值定义为:
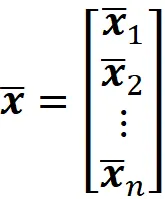
我们也可以将其写成:
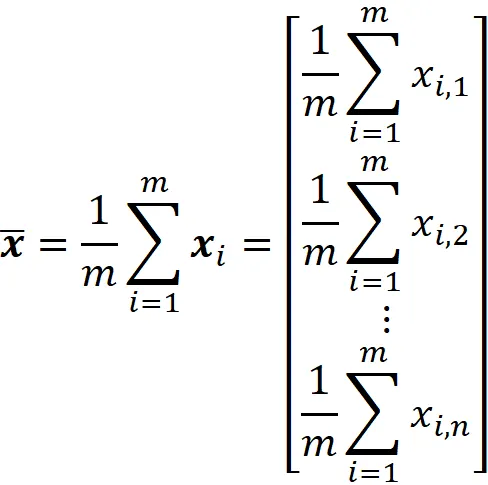
现在这些投影数据点的方差定义为:
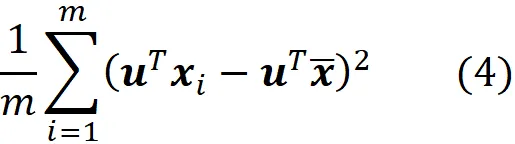
式子 1 可以进一步简化。该项

是一个标量(因为 a 的结果是标量量级)。此外,我们知道标量量的转置等于其本身。因此,我们可以得到

因此,数据点在 X 上的标量投影的方差可以写成
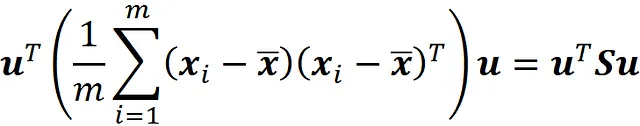
其中

被称为协方差矩阵(图 5)。
通过简化式子 5,可以证明协方差矩阵可以写成:
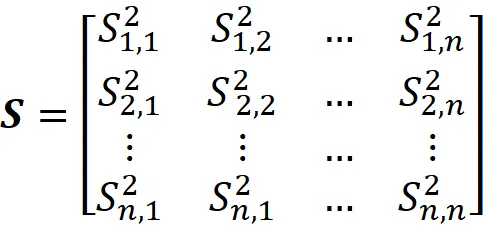
其中
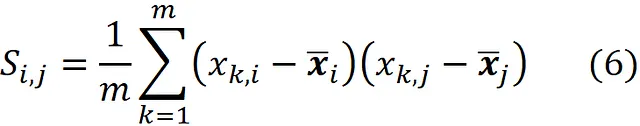
这里 xᵢ , ₖ 是设计矩阵 X 的(i,k)元素(或简单地说是向量 x ᵢ 的第 k 个元素)。
对于具有 n 个特征的数据集,协方差矩阵是一个 n × n 矩阵。此外,根据式子 6 中 Sᵢ , ⱼ 的定义,我们有:
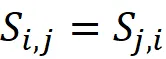
因此,它的(i,j)元素等于其(j,i)元素,这意味着协方差矩阵是对称矩阵,并且等于其转置:

现在我们找到向量 u ₁,使其最大化
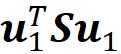
由于 u ₁ 是一个归一化向量,因此我们将其添加到优化问题中:

我们可以通过添加拉格朗日乘数 λ ₁ 来解决这个优化问题,并最大化
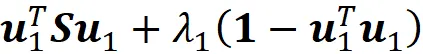
为此,我们将这个项相对于 u ₁ 的导数设置为零:
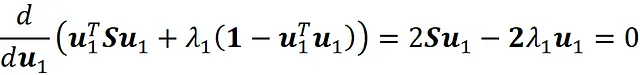
我们得到:

这意味着u₁是协方差矩阵S的一个特征向量,λ₁是它相应的特征值。我们称特征向量u₁为第一个主成分。接下来,我们想找到单位向量u₂,它在第一个主成分正交的所有可能方向中最大化u₂ᵀSu₂。因此,我们需要找到向量u₂,它满足以下约束条件最大化u₂ᵀSu₂:
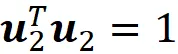

可以证明u₂是以下方程的解:
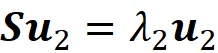
因此,我们得出结论,u₂也是S的一个特征向量,λ₂是它相应的特征值(附录中给出证明)。更一般地,我们要找到单位向量uᵢ,它在前面的主成分u₁…uᵢ₋₁正交的所有可能方向中最大化uᵢᵀSuᵢ。因此,我们需要找到向量uᵢ,它满足以下约束条件最大化:
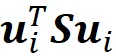
这些约束条件如下:
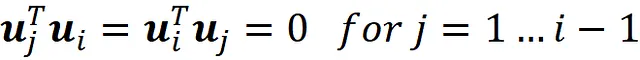

同样可以证明,uᵢ是以下方程的解:
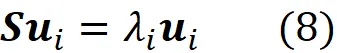
因此,uᵢ是S的一个特征向量,λᵢ是它相应的特征值(附录中给出证明)。向量uᵢ称为第i个主成分。如果我们将上一个方程乘以uⱼᵀ,我们得到:
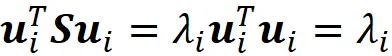
因此,我们得出结论,数据点在X上的标量投影的方差,投影在特征向量uᵢ上,等于它相应的特征值。
如果我们有一个具有n个特征的数据集,则协方差矩阵将是一个n×n的对称矩阵。这里,每个数据点可以用R^n中的向量(xᵢ)表示。如前所述,R^n中向量的元素给出其相对于标准基的坐标。
可以证明,一个n×n的对称矩阵具有n个实特征值,以及n个线性无关且正交的相应特征向量(谱定理)。这些n个正交特征向量是此数据集的主成分。可以证明,一组n个正交向量可以形成R^n的基。因此,这些主成分形成一个正交基,并可以用于为数据点定义新的坐标系(图6)。
我们可以轻松地计算每个数据点xᵢ相对于这个新坐标系的坐标。设B={ v₁, v₂, …, vn }是主成分的集合。我们首先用基向量来表示xᵢ:
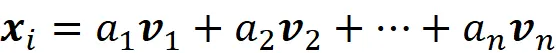
现在,如果我们将这个等式的两边都乘以vᵢᵀ,我们有:
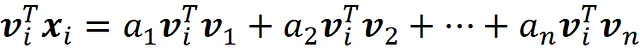
由于我们有一个正交基:
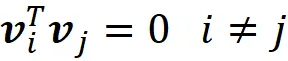
因此,它遵循:
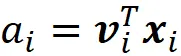
由于点积是交换的,我们也可以写成:
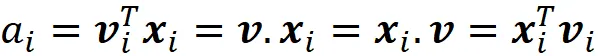
因此,xᵢ相对于B的坐标为:
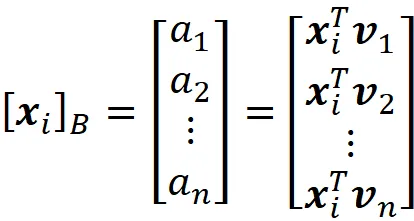
并且设计矩阵可以写成新坐标系下的形式:
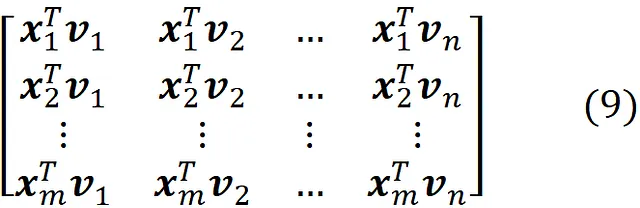
这里每行表示新坐标系下的数据点(观测值)。图6展示了n=2的一个例子。
数据点在每个特征向量(主成分)的标量投影的方差等于其对应的特征值。第一主成分具有最大的特征值(方差)。第二主成分具有第二大的特征值,依此类推。现在,我们可以选择前d个主成分并将原始数据点投影到由它们张成的子空间上。
因此,我们将原始数据点(具有n个特征)转换为属于d维子空间的这些投影数据点。通过这种方式,我们将原始数据集的维数从n降至d,同时最大化投影数据的方差。现在方程式9的前d列给出了投影数据点的坐标:
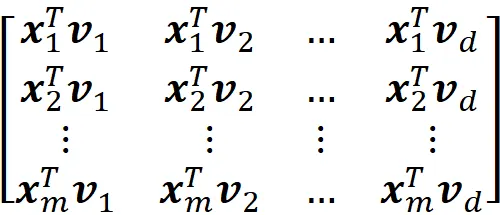
图7给出了这种转换的一个例子。原始数据集有3个特征(n=3),我们通过将数据点投影到由前两个主成分(v₁、v₂)形成的平面上来将其维数降至d=2。在由v₁和v₂张成的子空间中,每个数据点xᵢ的坐标是:
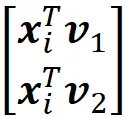
在进行PCA分析之前,通常会将数据集围绕零进行居中处理。为此,我们首先创建代表数据集的设计矩阵X(方程2)。然后从每列的元素中减去该列的平均值,创建一个新矩阵Y
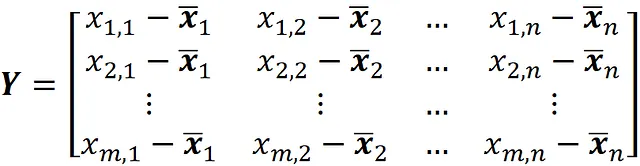
矩阵 Y 代表居中的数据集。在这个新矩阵中,每列的平均值为零:
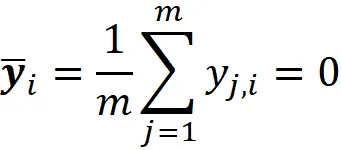
因此,数据集的平均值也为零:
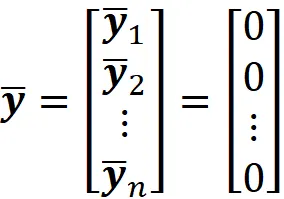
现在假设我们从居中的设计矩阵X开始并希望计算其协方差矩阵。因此,X的每列均值为零。从方程6中,我们得到:
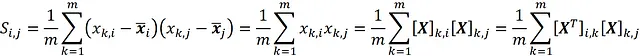
其中 [ X ]_ k , j 表示矩阵X的( k , j )元素。通过使用矩阵乘法的定义,我们得到
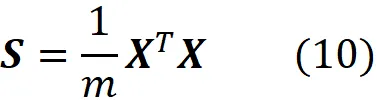
请注意,此方程式仅在设计矩阵(X)为居中时有效。
PCA和奇异值分解(SVD)之间的关系
假设A是一个m×n矩阵。然后,AᵀA将是一个n×n方阵,并且可以轻松地证明它是一个对称矩阵。由于AᵀA是对称的,因此它具有n个实特征值和n个线性无关且正交的特征向量(谱定理)。我们称这些特征向量为v₁,v₂,…,v_n,并假设它们已经归一化。可以证明AᵀA的特征值都是正的。现在假设我们按递减顺序标记它们,因此:
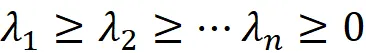
让v₁,v₂,…,v_n为对应于这些特征值的AᵀA的特征向量。我们将矩阵A的奇异值(表示为σᵢ)定义为λᵢ的平方根。因此,我们有
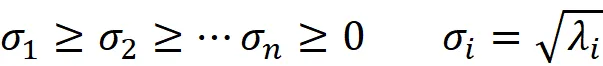
现在假设A的秩为r。然后可以证明AᵀA的非零特征值的数量或A的非零奇异值的数量为r:
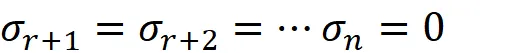
现在,矩阵A的奇异值分解(SVD)可以写成:

这里V是一个n×n矩阵,其列为vᵢ:
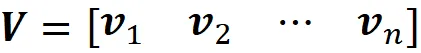
Σ是一个m×n的对角线矩阵,Σ的所有元素都为零,除了前r个对角线元素,这些元素等于A的奇异值。我们将矩阵U定义为:
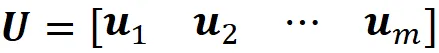
我们将u₁到ur定义为:

我们可以轻松地证明这些向量是正交的:
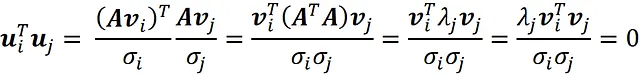
这里我们使用了vj是AᵀA的特征向量,这些特征向量是正交的这一事实。由于这些向量是正交的,它们也是线性无关的。其他的uᵢ向量(r<i≤m)定义为u₁,u₂,…,um形成一个m维向量空间(Rm)的基础。
设X是一个中心化的设计矩阵,其SVD分解如下:

如前所述,v₁,v₂,…,vn是XᵀX的特征向量,奇异值是对应特征值的平方根。因此,我们有:
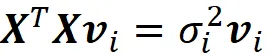
现在,我们可以将上一个等式的两侧除以m(其中m是数据点的数量),并使用方程10,得到:
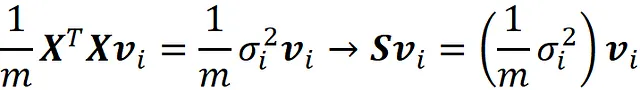
因此,vᵢ是协方差矩阵的特征向量,其对应的特征值是其对应奇异值的平方除以m。因此,SVD方程中的矩阵V给出了X的主成分,通过使用Σ中的奇异值,我们可以轻松地计算出特征值。总之,我们可以使用SVD来执行PCA。
让我们看看我们可以从SVD方程中得到什么。我们可以使用方程3和11来简化方程12中的UΣ:

与方程式9相比,我们得出结论,UΣ的第i行给出了数据点xᵢ相对于由主成分定义的基底的坐标。
现在假设在方程式12中,我们只保留U的前k列,V的前k行,以及Σ的前k行和列。如果我们将它们相乘,我们得到:
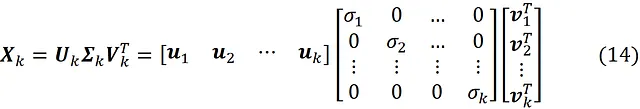
请注意,Xk仍然是一个m×n矩阵。如果我们用具有n个元素的向量b乘以Xk,我们得到:
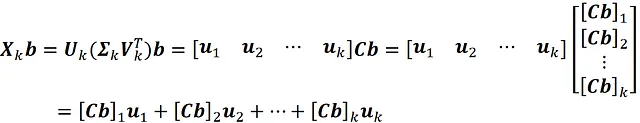
其中[Cb]ᵢ是向量Cb的第i个元素。由于u₁,u₂,…,uk是线性无关的向量(记住它们构成一个基底,所以它们应该是线性无关的),并且它们跨越Xkb,我们得出它们构成了Xkb的一组基底。这个基底有k个向量,因此Xk的列空间的维数是k。因此,Xk是一个秩为k的矩阵。
但是Xk代表什么呢?使用等式13,我们可以写成:
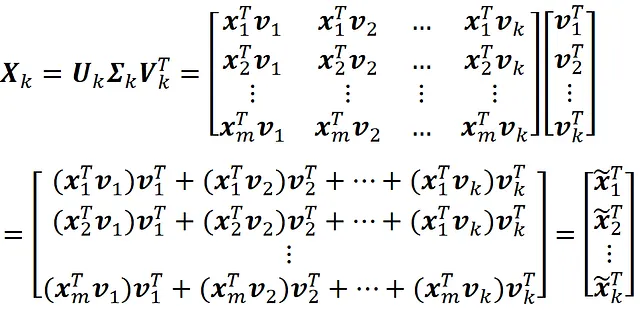
因此,Xk的第i行是:
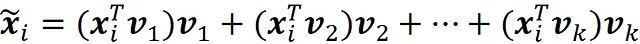
它是数据点xᵢ在由主成分v₁,v₂,…vk跨越的子空间上的向量投影。请记住,v₁,v₂,…vn是我们原始数据集的基底。此外,相对于这个基底,xᵢ的坐标是:
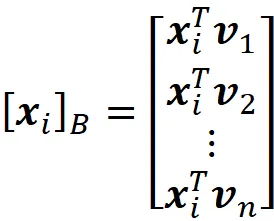
因此,使用等式1,我们可以将xᵢ写成:
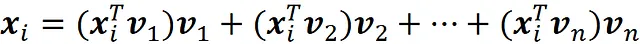
现在我们可以将xᵢ分解为两个向量。一个在由向量v₁,v₂,…vk定义的子空间中,另一个在其余向量定义的子空间中。
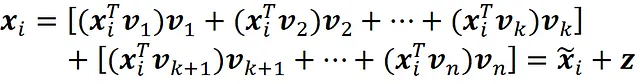
第一个向量是xᵢ在由向量v₁,v₂,…vk定义的子空间中的投影,等于x̃ᵢ。
请记住,设计矩阵 X 的每一行都代表一个原始数据点。同样,Xₖ 的每一行代表相同的数据点在由主成分 v₁、v₂、… vₖ (图 8) 张成的子空间上的投影。
现在我们可以计算原始数据点 (xi) 和投影数据点 (x̃i) 之间的距离。向量 xi 和 x̃i 的距离的平方为:

如果我们将所有数据点的距离的平方相加,得到:
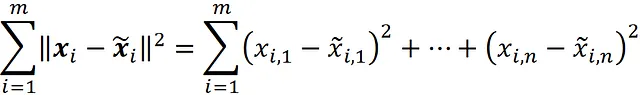
一个 m × n 矩阵 C 的 Frobenius 范数定义为:
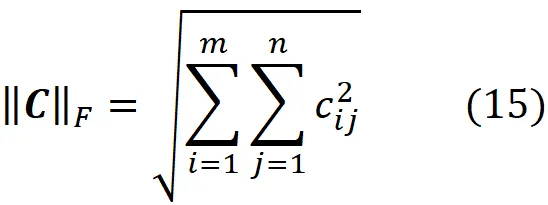
由于向量 xi 和 x̃i 是矩阵 X 和 Xₖ 的行的转置,我们可以得到:
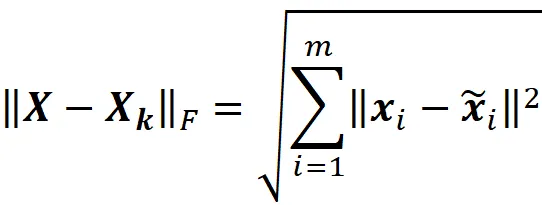
因此,X – Xₖ 的 Frobenius 范数与原始数据点和投影数据点之间距离的平方和成比例 (图 9),而随着投影数据点接近原始数据点,||X – Xₖ||F 减小。
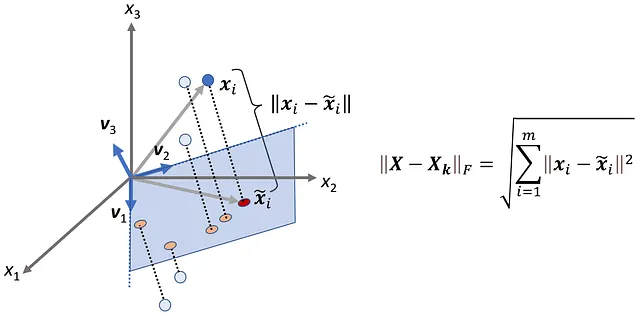
我们希望投影点是原始数据点的一个良好逼近,因此我们希望 Xₖ 在所有秩为 k 的矩阵中给出 X – Xₖ 的最低值。
假设我们有秩为 r 的 m × n 矩阵 X,并且X的奇异值已排序,则我们有:
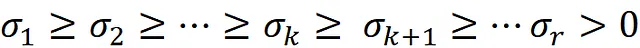
可以证明,Xₖ 在所有秩为 k 的 m × n 矩阵中最小化了 X – A 的 Frobenius 范数。数学上表达为:

Xₖ 是所有秩为 k 的矩阵中距离 X 最近的矩阵,可以被视为设计矩阵 X 的最佳秩为 k 的逼近。这也意味着由 Xₖ 表示的投影数据点是由 X 表示的原始数据点的最佳秩为 k 的逼近(就总误差而言)。
现在我们可以尝试以不同的格式写出先前的等式。假设 Z 是一个 m × k 的矩阵,W 是一个 k × n 的矩阵。我们可以证明
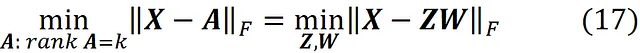
所以找到一个秩为 k 的矩阵 A ,使 || X – A ||_ F 最小化等价于找到最小化 || X – ZW ||_ F 的矩阵 Z 和 W (附录中给出了证明)。因此,我们可以写成
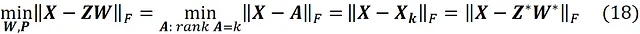
其中 Z * (一个 m × k 矩阵)和 W * (一个 k × n 矩阵)是最小化问题的解,我们有
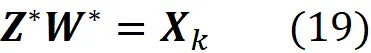
现在根据公式 13 和 14,我们可以写成:
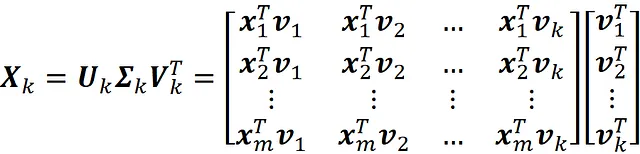
因此,如果我们使用 SVD 解决公式 18 中的最小化问题,则可以得到 Z * 和 W * 的以下值:
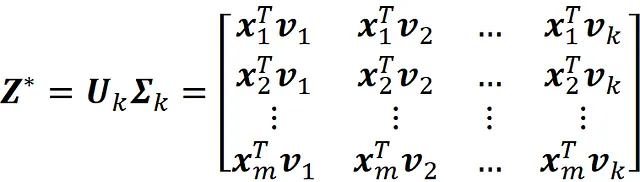
和

W * 的行给出了主成分的转置,Z * 的行给出了每个投影数据点相对于这些主成分形成的基的坐标的转置。重要的是要注意,主成分形成一个正交基(因此主成分既归一化又正交)。实际上,我们可以假设 PCA 只寻找一个矩阵 W,其中行形成一个正交集。我们知道当两个向量正交时,它们的内积为零,因此我们可以说 PCA(或 SVD)解决了带有这个约束的最小化问题:
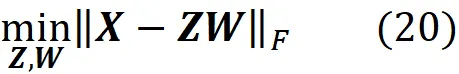
其中 Z 和 W 是 m × k 和 k × n 矩阵。此外,如果 Z * 和 W * 是最小化问题的解,则我们有
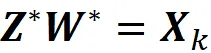
这个公式非常重要,因为它允许我们建立 PCA 和自编码器之间的联系。
PCA 和自编码器之间的关系
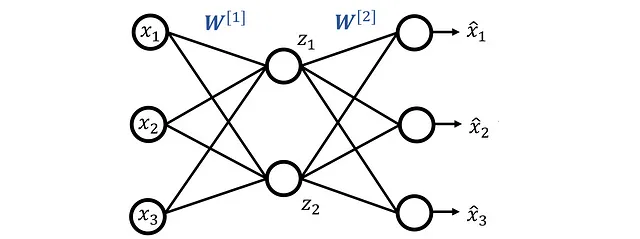
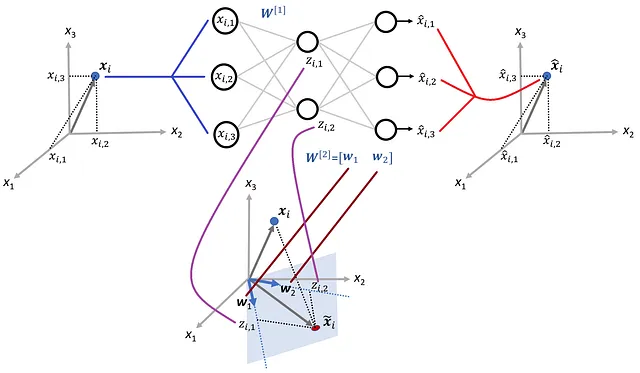
我们从一个只有三层的自编码器开始,如图 10 所示。这个网络有 n 个输入特征,用 x ₁… x_n 表示,输出层有 n 个神经元,输出用 x^ ₁… x^_n 表示。隐藏层有 k 个神经元(其中 k < n),隐藏层的输出用 z ₁… zₖ 表示。矩阵 W^ [1] 和 W^ [2] 包含隐藏层和输出层的权重。
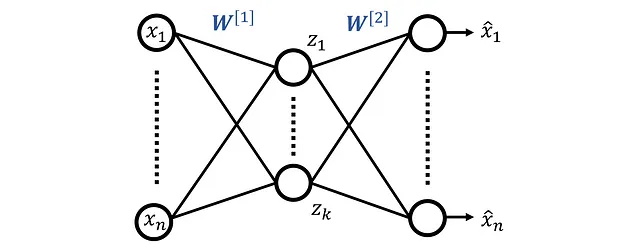
这里
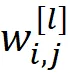
表示第i个神经元在第l层(假设l=1为隐藏层,l=2为输出层)中的第j个输入(来自第l-1层的第j个神经元)的权重(图11)。
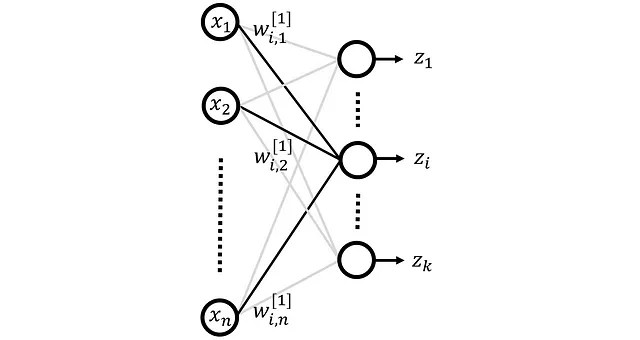
因此,隐藏层的权重为:
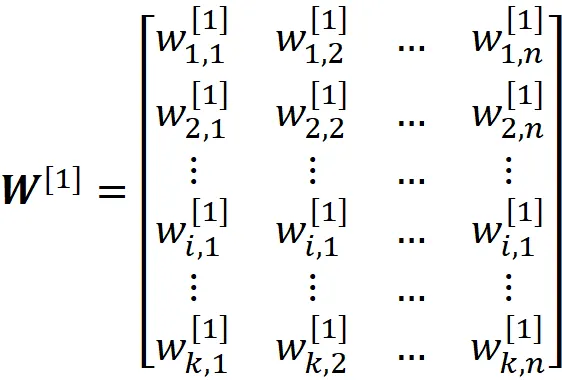
这个矩阵的第i行给出了隐藏层中第i个神经元的所有权重。同样,输出层的权重为:
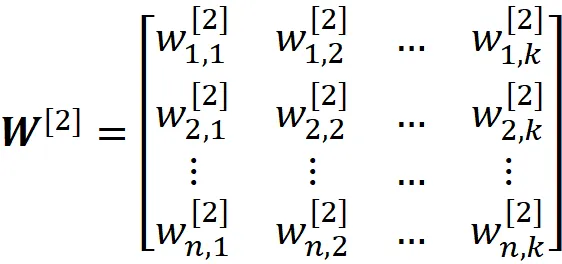
每个神经元都有一个激活函数。我们可以使用权重矩阵W^ [1]和输入特征计算隐藏层中神经元的输出(该神经元的激活):
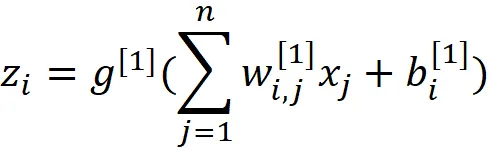
其中bᵢ ^[1]是第i个神经元的偏差,g^ [1]是第1层中神经元的激活函数。我们可以将这个方程以向量化的形式写出:
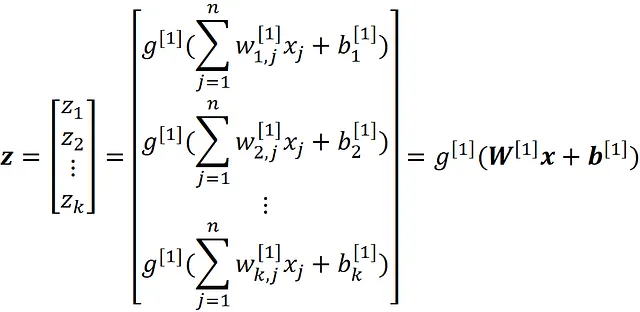
其中b是偏差向量:
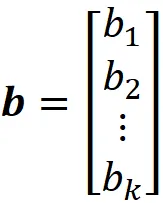
而x是输入特征向量:
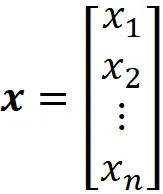
类似地,我们可以将输出层中第i个神经元的输出写为:
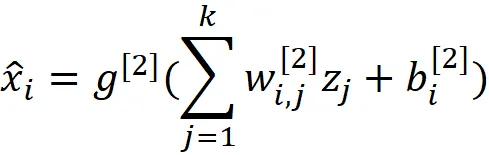
向量化形式如下:

现在假设我们使用以下设计矩阵作为训练数据集来训练此网络:
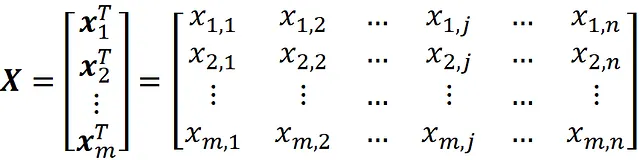
因此,训练数据集有m个观测值(示例)和n个特征。请记住,第i个观测值由向量表示
如果我们将这个向量输入到网络中,网络的输出用这个向量表示:

我们还需要做出以下假设,以确保自编码器模拟 PCA:
1-训练数据集被居中,因此每一列的X的平均值为零:

2-隐藏层和输出层的激活函数是线性的,所有神经元的偏差都为零。这意味着我们在这个网络中使用了一个线性编码器和解码器。因此,我们有:
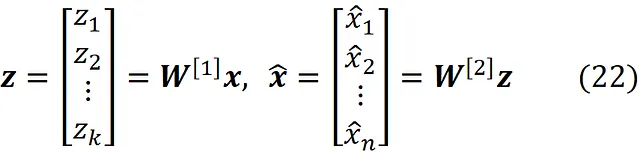
3-我们使用二次损失函数来训练这个网络。因此,成本函数是均方误差(MSE),定义为:
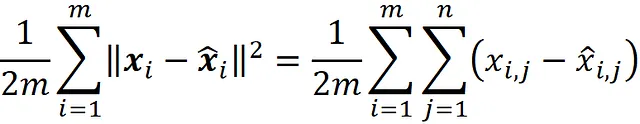
现在我们可以表明:
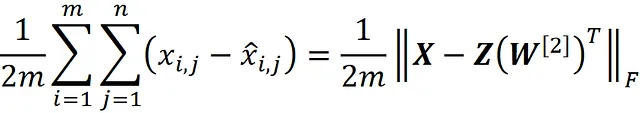
其中 Z 定义为:
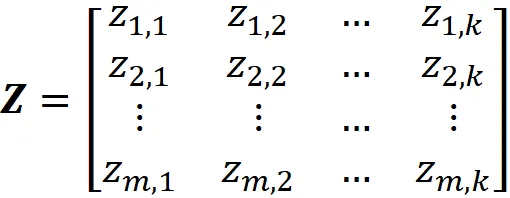
附录中给出了证明。这里的第 i 行 Z 给出了将第 i 个观测值馈入网络时隐藏层的输出。因此,最小化这个网络的成本函数与最小化以下成本函数相同:
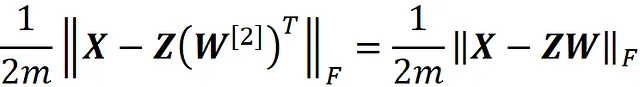
其中我们将矩阵 W 定义为
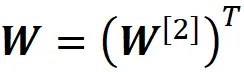
请注意,W ^[2] 的每一行都是 W 的一列。
我们知道,如果我们用正数乘以函数,其最小值不会改变。因此,当我们最小化成本函数时,可以去掉乘数 1/(2 m )。因此,通过训练这个网络,我们正在解决这个最小化问题:
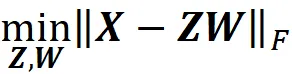
其中 Z 和 W 是 m × k 和 k × n 矩阵。如果我们将这个方程与方程 20 进行比较,我们会发现它是与 PCA 的相同最小化问题。因此,解决方案应该与方程 20 的解决方案相同:
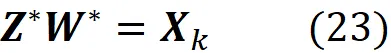
然而,这里有一个重要的区别。方程 21 的约束条件在这里没有应用。所以问题来了。自编码器找到的最优值 Z 和 W 是否与 PCA 的最优值相同?W 的行是否应该始终形成一个正交集合?
首先,让我们扩展之前的方程。
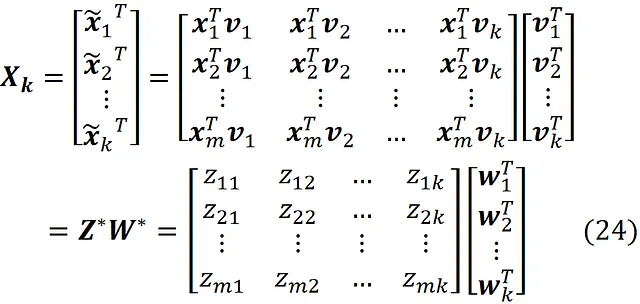
我们知道,Xₖ的第i行是以下的转置:
这是数据点xᵢ在由主成分v₁,v₂,…vₖ张成的子空间上的向量投影。因此,x̃ᵢ属于一个k维子空间。向量w₁,w₂,…,wₖ应该是线性无关的。否则,W *的秩将小于k(请记住,W *的秩等于W *的最大线性无关行数),并且根据公式A.3,Xₖ的秩将小于k。可以证明,一组k个线性无关向量形成k维子空间的基础。因此,我们得出结论,向量w₁,w₂,…,wₖ也形成了由主成分张成的相同子空间的基础。现在我们可以使用公式24来写出Xₖ的第i行,以向量w₁,w₂,…,wₖ为基础。
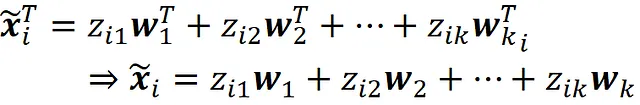
这意味着Z *的第i行只是相对于由向量w₁,w₂,…,wₖ张成的基础的坐标的x̃ᵢ的坐标。图12展示了一个k=2的例子。

综上所述,由自动编码器找到的矩阵Z *和W *可以生成由主成分张成的相同子空间。我们也得到了与PCA相同的投影数据点,因为:
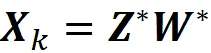
然而,这些矩阵为该子空间定义了一个新的基础。与PCA找到的主成分不同,这个新基础的向量不一定正交。W *的行给出了新基础向量的转置,Z *的行给出了相对于该基础的每个数据点的坐标的转置。
因此,我们得出结论,线性自动编码器无法找到主成分,但是可以使用不同的基础找到张成它们的子空间。这里有一个例外。假设我们只想保留第一个主成分v₁。因此,我们想将原始数据集的维数从n降低到1。在这种情况下,子空间只是由第一个主成分张成的直线。线性自动编码器也将找到具有不同基础向量w₁的相同直线。这个基础向量不一定被规范化,可能具有与v₁相反的方向,但它仍然在同一条直线(子空间)上。这在图13中得到了证明。现在,如果我们对w₁进行规范化,我们将得到数据集的第一个主成分。因此,在这种情况下,线性自动编码器间接地找到了第一个主成分。
到目前为止,我们已经讨论了自编码器和PCA背后的理论。现在让我们看一个Python的例子。在下一节中,我们将使用Pytorch创建一个自编码器,并将其与PCA进行比较。
案例研究:PCA vs 自编码器
我们首先需要创建一个数据集。第一个代码清单创建了一个具有3个特征的简单数据集。前两个特征(x₁和x₂)具有2d多元正态分布,第三个特征(x₃)等于x₂的一半。这个数据集存储在数组X中,它起到设计矩阵的作用。我们还将设计矩阵居中。
# 第一个代码清单import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.decomposition import PCAfrom scipy.stats import multivariate_normalimport torchimport torch.nn as nnfrom numpy import linalg as LAfrom sklearn.preprocessing import MinMaxScalerimport random%matplotlib inlinenp.random.seed(1)mu = [0, 0]Sigma = [[1, 1], [1, 2.5]] # X is the design matrix and each row of X is an exampleX = np.random.multivariate_normal(mu, Sigma, 10000)X = np.concatenate([X, X[:, 0].reshape(len(X), 1)], axis=1)X[:, 2] = X[:, 1] / 2X = (X - X.mean(axis=0))x, y, z = X.T第二个代码清单创建了这个数据集的3d图,结果如图14所示。
# 第二个代码清单fig = plt.figure(figsize=(10, 10))ax1 = fig.add_subplot(111, projection='3d')ax1.scatter(x, y, z, color = 'blue')ax1.view_init(20, 185)ax1.set_xlabel("$x_1$", fontsize=20)ax1.set_ylabel("$x_2$", fontsize=20)ax1.set_zlabel("$x_3$", fontsize=20)ax1.set_xlim([-5, 5])ax1.set_ylim([-7, 7])ax1.set_zlim([-4, 4])plt.show()
正如您所看到的,这个数据集定义在由x₃ = x₁/2表示的平面上。现在我们开始PCA分析。
pca = PCA(n_components=3)pca.fit(X)我们可以使用components_字段轻松获取主成分(即X的特征向量)。它返回一个数组,其中每一行代表一个主成分。
# 每一行都给出了一个主成分(特征向量)pca.components_
array([[-0.38830581, -0.824242 , -0.412121 ], [-0.92153057, 0.34731128, 0.17365564], [ 0. , -0.4472136 , 0.89442719]])我们还可以使用explained_variance_字段查看它们对应的特征值。请记住,数据点在特征向量uᵢ上的标量投影的方差等于其对应的特征值。
pca.explained_variance_
array([3.64826952e+00, 5.13762062e-01, 3.20547162e-32])请注意,特征值按降序排列。因此,pca.components_的第一行给出了第一个主成分。第三个代码清单绘制了主成分和数据点(图15)。
# 第三个代码清单v1 = pca.components_[0]v2 = pca.components_[1]v3 = pca.components_[2]fig = plt.figure(figsize=(10, 10))ax1 = fig.add_subplot(111, projection='3d')ax1.scatter(x, y, z, color = 'blue', alpha= 0.1)ax1.plot([0, v1[0]], [0, v1[1]], [0, v1[2]], color="black", zorder=6)ax1.plot([0, v2[0]], [0, v2[1]], [0, v2[2]], color="black", zorder=6)ax1.plot([0, v3[0]], [0, v3[1]], [0, v3[2]], color="black", zorder=6)ax1.scatter(x, y, z, color = 'blue', alpha= 0.1)ax1.plot([0, 7*v1[0]], [0, 7*v1[1]], [0, 7*v1[2]], color="gray", zorder=5)ax1.plot([0, 5*v2[0]], [0, 5*v2[1]], [0, 5*v2[2]], color="gray", zorder=5)ax1.plot([0, 3*v3[0]], [0, 3*v3[1]], [0, 3*v3[2]], color="gray", zorder=5)ax1.text(v1[0], v1[1]-0.2, v1[2], "$\mathregular{v}_1$", fontsize=20, color='red', weight="bold", style="italic", zorder=9)ax1.text(v2[0], v2[1]+1.3, v2[2], "$\mathregular{v}_2$", fontsize=20, color='red', weight="bold", style="italic", zorder=9)ax1.text(v3[0], v3[1], v3[2], "$\mathregular{v}_3$", fontsize=20, color='red', weight="bold", style="italic", zorder=9)ax1.view_init(20, 185)ax1.set_xlabel("$x_1$", fontsize=20, zorder=2)ax1.set_ylabel("$x_2$", fontsize=20)ax1.set_zlabel("$x_3$", fontsize=20)ax1.set_xlim([-5, 5])ax1.set_ylim([-7, 7])ax1.set_zlim([-4, 4])plt.show()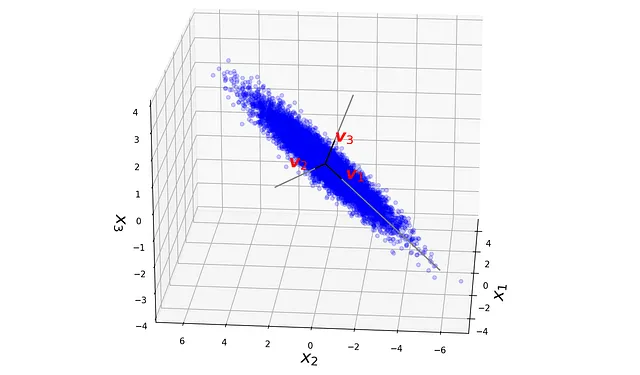
请注意,第三个特征值几乎为零。这是因为数据集位于一个二维平面上 ( x₃= x₁/2),如图15所示,沿着 v₃没有方差。我们可以使用transform() 方法获得每个数据点相对于主成分定义的新坐标系的坐标。 transform() 返回的数组的每一行给出了一个数据点的坐标。
# 代码清单 4# Z* = UΣpca.transform(X)
([[ 3.09698570e+00, -3.75386182e-01, -2.06378618e-17], [-9.49162774e-01, -7.96300950e-01, -5.13280752e-18], [ 1.79290419e+00, -1.62352748e+00, 2.41135694e-18], ..., [ 2.14708946e+00, -6.35303400e-01, 4.34271577e-17], [ 1.25724271e+00, 1.76475781e+00, -1.18976523e-17], [ 1.64921984e+00, -3.71612351e-02, -5.03148111e-17]])现在,我们可以选择前两个主成分,并将原始数据点投影到由它们跨越的子空间上。因此,我们将原始数据点 (具有 3 个特征) 转换为这些属于二维子空间的投影数据点。只需要删除pca.transform(X) 返回的数组的第三列即可。这意味着我们将原始数据集的维数从 3 降低到 2,同时最大化投影数据的方差。清单 5 绘制了这个二维数据集,结果如图16所示。
# 代码清单 5fig = plt.figure(figsize=(8, 6))plt.scatter(pca.transform(X)[:,0], pca.transform(X)[:,1])plt.axis('equal')plt.axhline(y=0, color='gray')plt.axvline(x=0, color='gray')plt.xlabel("$v_1$", fontsize=20)plt.ylabel("$v_2$", fontsize=20)plt.xlim([-8.5, 8.5])plt.ylim([-4, 4])plt.show()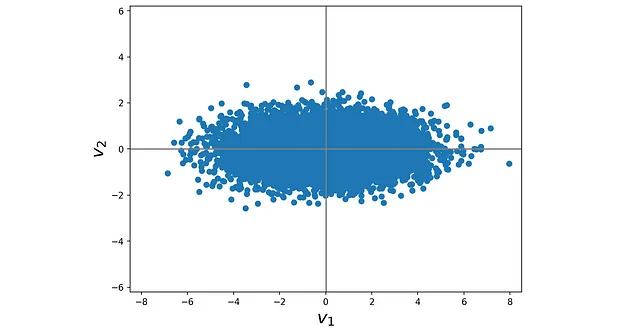
我们也可以使用奇异值分解 (SVD) 获得相同的结果。清单 6 使用numpy中的svd() 函数进行X 的奇异值分解。
# 代码清单 6U, s, VT = LA.svd(X)print("U=", np.round(U, 4))print("Σ的对角线元素=", np.round(s, 4))print("V^T=", np.round(VT, 4))
U= [[ 1.620e-02 -5.200e-03 1.130e-02 ... -2.800e-03 -2.100e-02 -6.200e-03] [-5.000e-03 -1.110e-02 9.895e-01 ... 1.500e-03 -3.000e-04 1.100e-03] [ 9.400e-03 -2.270e-02 5.000e-04 ... -1.570e-02 1.510e-02 -7.100e-03] ... [ 1.120e-02 -8.900e-03 -1.800e-03 ... 9.998e-01 2.000e-04 -1.000e-04] [ 6.600e-03 2.460e-02 1.100e-03 ... 1.000e-04 9.993e-01 -0.000e+00] [ 8.600e-03 -5.000e-04 -1.100e-03 ... -1.000e-04 -0.000e+00 9.999e-01]]Σ的对角线元素= [190.9949 71.6736 0. ]V^T= [[-0.3883 -0.8242 -0.4121] [-0.9215 0.3473 0.1737] [ 0. -0.4472 0.8944]]此函数返回矩阵 U 和 V ᵀ以及对角线元素 Σ(请注意,Σ 的其他元素为零)。请注意,V ᵀ 的行给出了 pca.omponents_ 返回的相同主成分。
现在,要获取 X ₖ,我们只需保留 U 和 V 的前两列以及 Σ 的前两行和列(方程14)。如果将它们相乘,我们得到:
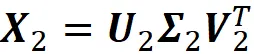
清单7 计算了这个矩阵:
# 清单7k = 2Sigma = np.zeros((X.shape[0], X.shape[1]))Sigma[:min(X.shape[0], X.shape[1]), :min(X.shape[0], X.shape[1])] = np.diag(s)X2 = U[:, :k] @ Sigma[:k, :k] @ VT[:k, :]X2
array([[-0.85665, -2.68304, -1.34152], [ 1.10238, 0.50578, 0.25289], [ 0.79994, -2.04166, -1.02083], ..., [-0.24828, -1.99037, -0.99518], [-2.11447, -0.42335, -0.21168], [-0.60616, -1.37226, -0.68613]])Z *= U ₂ Σ ₂ 的每一行都给出一个投影数据点相对于由前两个主成分形成的基的坐标。清单8 计算 Z *= U ₂ Σ ₂。请注意,它给出了清单4 中 pca.transform(X) 的前两列。因此,PCA 和 SVD 都找到了相同的子空间和相同的投影数据点。
# 清单8# Z*=U_k Σ_k 的每一行都给出了相应行的 X 在秩为 k 的子空间上的投影坐标U[:, :k] @ Sigma[:k, :k]
array([[ 3.0969857 , -0.37538618], [-0.94916277, -0.79630095], [ 1.79290419, -1.62352748], ..., [ 2.14708946, -0.6353034 ], [ 1.25724271, 1.76475781], [ 1.64921984, -0.03716124]])现在,我们创建一个自编码器并用此数据集对其进行训练,以后将与 PCA 进行比较。图17 显示了网络架构。瓶颈层有两个神经元,因为我们想要将数据点投影到二维子空间。
清单9 在 Pytorch 中定义了这个架构。所有层中的神经元都具有线性激活函数和零偏差。
# 清单9seed = 9 np.random.seed(seed)torch.manual_seed(seed)np.random.seed(seed)class Autoencoder(nn.Module): def __init__(self): super(Autoencoder, self).__init__() ## encoder self.encoder = nn.Linear(3, 2, bias=False) ## decoder self.decoder = nn.Linear(2, 3, bias=False) def forward(self, x): encoded = self.encoder(x) decoded = self.decoder(encoded) return encoded, decoded # initialize the NNmodel1 = Autoencoder().double()print(model1)我们使用 MSE 损失函数和 Adam 优化器。
# 列表10# 指定二次损失函数loss_func = nn.MSELoss()# 定义优化器optimizer = torch.optim.Adam(model1.parameters(), lr=0.001)我们使用列表1中定义的设计矩阵来训练此模型。
X_train = torch.from_numpy(X) 然后我们训练它3000个时期:
# 列表11def train(model, loss_func, optimizer, n_epochs, X_train): model.train() for epoch in range(1, n_epochs + 1): optimizer.zero_grad() encoded, decoded = model(X_train) loss = loss_func(decoded, X_train) loss.backward() optimizer.step() if epoch % int(0.1*n_epochs) == 0: print(f'epoch {epoch} \t Loss: {loss.item():.4g}') return encoded, decodedencoded, decoded = train(model1, loss_func, optimizer, 3000, X_train)
epoch 300 Loss: 0.4452epoch 600 Loss: 0.1401epoch 900 Loss: 0.05161epoch 1200 Loss: 0.01191epoch 1500 Loss: 0.003353epoch 1800 Loss: 0.0009412epoch 2100 Loss: 0.0002304epoch 2400 Loss: 4.509e-05epoch 2700 Loss: 6.658e-06epoch 3000 Loss: 7.02e-07Pytorch张量encoded存储隐藏层的输出(z₁,z₂),张量decoded存储自编码器的输出(x^₁,x^₂,x^₃)。我们首先将它们转换为numpy数组。
encoded = encoded.detach().numpy()decoded = decoded.detach().numpy()如前所述,具有中心数据集和MSE成本函数的线性自编码器解决以下最小化问题:
其中
而Z包含训练数据集中所有示例的瓶颈层的输出。我们还看到该最小化的解决方案由方程23给出。因此,在这种情况下,我们有:

一旦我们训练了自编码器,我们就可以检索矩阵Z *和W *。数组encoded给出矩阵Z *:
# Z*值。每行给出一个#投影数据点的坐标Zstar = encodedZstar
array([[ 2.57510917, -3.13073321], [-0.20285442, 1.38040138], [ 2.39553775, -1.16300036], ..., [ 2.0265917 , -1.99727172], [-0.18811382, -2.15635479], [ 1.26660007, -1.74235118]])列表12检索矩阵W^ [2]:
# 列表12# W^[2]的每一行都给出一个神经元的权重#输出层W2 = model1.decoder.weightW2 = W2.detach().numpy()W2
array([[ 0.77703505, 0.91276084], [-0.72734132, 0.25882988], [-0.36143178, 0.13109568]])为了获得W *,我们可以写成:
#每一行的Pstar(或W2的列)是基向量之一
Wstar = W2.T
array([[ 0.77703505, -0.72734132, -0.36143178], [ 0.91276084, 0.25882988, 0.13109568]])每一行的W*代表其中一个基向量(wᵢ),由于瓶颈层有两个神经元,因此我们得到了两个基向量(w₁,w₂)。我们可以很容易地看出w₁和w₂不构成正交基,因为它们的内积不为零:
w1 = Wstar[0]
w2 = Wstar[1]
# p1 and p2 are not orthogonal since thier inner product is not zero
np.dot(w1, w2)
0.47360735759现在我们可以使用公式25轻松地计算X₂:
# X2 = Zstar @ Pstar
Zstar @ Wstar
array([[-0.8566606 , -2.68331059, -1.34115189], [ 1.10235133, 0.50483352, 0.25428269], [ 0.7998756 , -2.04339283, -1.0182878 ], ..., [-0.24829863, -1.99097748, -0.99430834], [-2.11440724, -0.42130609, -0.21469848], [-0.60615728, -1.37222311, -0.68620423]])请注意,这个数组和使用列表7中的SVD计算出的数组X2是相同的(由于数值误差,它们之间存在一些小差异)。如前所述,Z*的每一行给出了相对于向量w₁和w₂形成的基向量的投影数据点(x̃ᵢ)的坐标。
列表13绘制了数据集、其主要成分v₁和v₂以及新的基向量w₁和w₂在两个不同的视图中。结果如图18所示。请注意,数据点和基向量都位于同一平面上。请注意,训练自编码器始于权重的随机初始化,因此如果我们在列表9中不使用随机种子,则向量w₁和w₂将是不同的,但是它们始终位于主成分的同一平面上。
#列表13
fig = plt.figure(figsize=(18, 14))
plt.subplots_adjust(wspace = 0.01)
origin = [0], [0], [0]
ax1 = fig.add_subplot(121, projection='3d')
ax2 = fig.add_subplot(122, projection='3d')
ax1.set_aspect('auto')
ax2.set_aspect('auto')
def plot_view(ax, view1, view2):
ax.scatter(x, y, z, color = 'blue', alpha= 0.1)
#主成分
ax.plot([0, pca.components_[0,0]], [0, pca.components_[0,1]],
[0, pca.components_[0,2]],
color="black", zorder=5)
ax.plot([0, pca.components_[1,0]], [0, pca.components_[1,1]],
[0, pca.components_[1,2]],
color="black", zorder=5)
ax.text(pca.components_[0,0], pca.components_[0,1],
pca.components_[0,2]-0.5, "$\mathregular{v}_1$",
fontsize=18, color='black', weight="bold",
style="italic")
ax.text(pca.components_[1,0], pca.components_[1,1]+0.7,
pca.components_[1,2], "$\mathregular{v}_2$",
fontsize=18, color='black', weight="bold",
style="italic")
#自编码器找到的新基向量
ax.plot([0, w1[0]], [0, w1[1]], [0, w1[2]],
color="darkred", zorder=5)
ax.plot([0, w2[0]], [0, w2[1]], [0, w2[2]],
color="darkred", zorder=5)
ax.text(w1[0], w1[1]-0.2, w1[2]+0.1,
"$\mathregular{w}_1$", fontsize=18, color='darkred',
weight="bold", style="italic")
ax.text(w2[0], w2[1], w2[2]+0.3,
"$\mathregular{w}_2$", fontsize=18, color='darkred',
weight="bold", style="italic")
ax.view_init(view1, view2)
ax.set_xlabel("$x_1$", fontsize=20, zorder=2)
ax.set_ylabel("$x_2$", fontsize=20)
ax.set_zlabel("$x_3$", fontsize=20)
ax.set_xlim([-3, 5])
ax.set_ylim([-5, 5])
ax.set_zlim([-4, 4])
plot_view(ax1, 25, 195)
plot_view(ax2, 0, 180)
plt.show()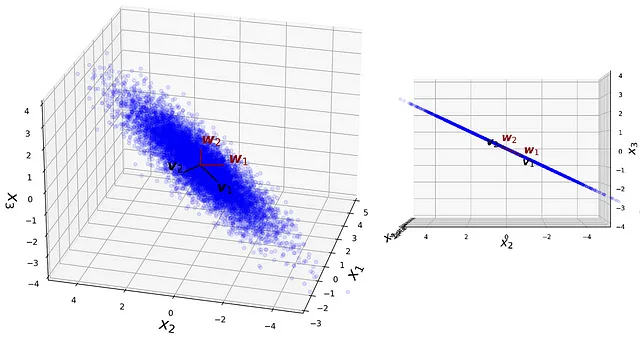
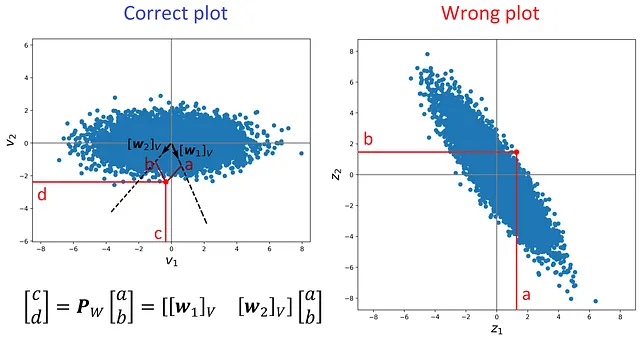
清单14绘制了Z *的行,结果显示在图19中。这些行代表编码数据点。需要注意的是,如果我们将此图与图16进行比较,它们看起来不同。我们知道自编码器和PCA都会给出相同的投影数据点(相同的X₂),但是当我们将这些投影数据点绘制在2d空间中时,它们看起来不同。为什么?
# 清单14# 这不是在2d空间中绘制投影数据点的正确方法,因为{w1,w2}不是正交基fig = plt.figure(figsize=(8, 8))plt.scatter(Zstar[:, 0], Zstar[:, 1])i= 6452plt.scatter(Zstar[i, 0], Zstar[i, 1], color='red', s=60)plt.axis('equal')plt.axhline(y=0, color='gray')plt.axvline(x=0, color='gray')plt.xlabel("$z_1$", fontsize=20)plt.ylabel("$z_2$", fontsize=20)plt.xlim([-9,9])plt.ylim([-9,9])plt.show()
原因是每个图都有不同的基础。在图16中,我们有相对于由v₁和v₂形成的正交基的投影数据点的坐标。然而,在图19中,投影数据点的坐标相对于不正交的w₁和w₂。因此,如果我们尝试使用正交坐标系(如图19)绘制它们,我们会得到一个失真的图。这也在图20中证明了。
为了正确绘制Z *的行,我们首先需要找到向量w₁和w₂相对于由V = {v₁,v₂}形成的正交基的坐标。
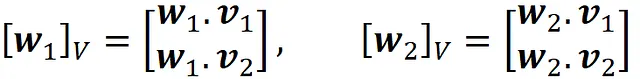
我们知道Z *的每一行的转置给出了相对于由W = {w₁,w₂}形成的基的投影数据点的坐标。因此,我们可以使用公式1来获得相同数据点相对于正交基V = {v₁,v₂}的坐标。
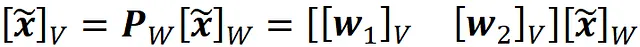
其中
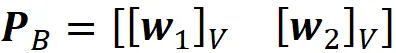
是坐标变换矩阵。清单15使用这些方程将Z *的行相对于由V = {v₁,v₂}形成的正交基绘制出来。结果显示在图21中,现在它看起来与使用SVD生成的图15完全相同。
# 列表15w1_V = np.array([np.dot(w1, v1), np.dot(w1, v2)])w2_V = np.array([np.dot(w2, v1), np.dot(w2, v2)])P_W = np.array([w1_V, w2_V]).TZstar_V = np.zeros((Zstar.shape[0], Zstar.shape[1]))for i in range(len(Zstar_B)): Zstar_V[i] = P_W @ Zstar[i]fig = plt.figure(figsize=(8, 6))plt.scatter(Zstar_V[:, 0], Zstar_V[:, 1])plt.axis('equal')plt.axhline(y=0, color='gray')plt.axvline(x=0, color='gray')plt.scatter(Zstar_V[i, 0], Zstar_V[i, 1], color='red', s=60)plt.quiver(0, 0, w1_V[0], w1_V[1], color=['black'], width=0.007, angles='xy', scale_units='xy', scale=1)plt.quiver(0, 0, w2_V[0], w2_V[1], color=['black'], width=0.007, angles='xy', scale_units='xy', scale=1)plt.text(w1_V[0]+0.1, w2_V[1]-0.2, "$[\mathregular{w}_1]_V$", weight="bold", style="italic", color='black', fontsize=20)plt.text(w2_V[0]-2.25, w2_V[1]+0.1, "$[\mathregular{w}_2]_V$", weight="bold", style="italic", color='black', fontsize=20)plt.xlim([-8.5, 8.5])plt.xlabel("$v_1$", fontsize=20)plt.ylabel("$v_2$", fontsize=20)plt.show()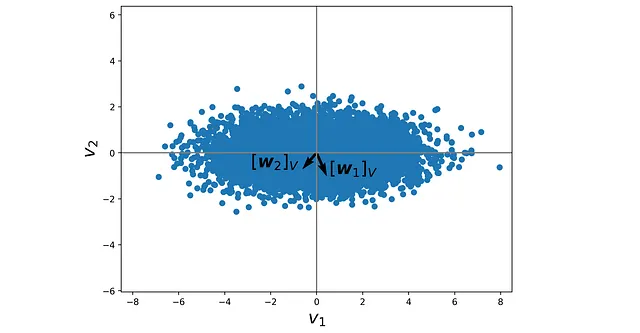
图22演示了在这个案例研究中创建的线性自编码器的不同组件以及它们的值的几何解释。
非线性自编码器
尽管自编码器无法找到数据集的主成分,但与PCA相比,它仍然是一种更强大的降维工具。在本节中,我们将讨论非线性自编码器,并将看到一个例子,其中PCA失败,但非线性自编码器仍然可以进行降维。PCA的一个问题是假设投影的数据点的最大方差沿着主成分。换句话说,它假设它们都沿着直线,而在许多实际应用中,这并不是真的。
让我们看一个例子。列表16生成一个名为X_circ的随机圆形数据集,并在图23中绘制它。该数据集有70个数据点。X_circ是一个2d数组,其中每行表示其中一个数据点(观测)。我们还为每个数据点分配颜色。颜色不用于建模,我们只是添加它以保持数据点的顺序。
# 列表16np.random.seed(0)n = 90theta = np.sort(np.random.uniform(0, 2*np.pi, n))colors = np.linspace(1, 15, num=n) x1 = np.sqrt(2) * np.cos(theta)x2 = np.sqrt(2) * np.sin(theta)X_circ = np.array([x1, x2]).Tfig = plt.figure(figsize=(8, 6))plt.axis('equal')plt.scatter(X_circ[:,0], X_circ[:,1], c=colors, cmap=plt.cm.jet) plt.xlabel("$x_1$", fontsize= 18)plt.ylabel("$x_2$", fontsize= 18)plt.show()
接下来,我们使用 PCA 找到此数据集的主成分。列表 17 找到主成分并将其绘制在图 24 中。
# 列表 17pca = PCA(n_components=2, random_state = 1)pca.fit(X_circ)fig = plt.figure(figsize=(8, 6))plt.axis('equal')plt.scatter(X_circ[:,0], X_circ[:,1], c=colors, cmap=plt.cm.jet)plt.quiver(0, 0, pca.components_[0,0], pca.components_[0,1], color=['black'], width=0.01, angles='xy', scale_units='xy', scale=1.5)plt.quiver(0, 0, pca.components_[1,0], pca.components_[1,1], color=['black'], width=0.01, angles='xy', scale_units='xy', scale=1.5)plt.plot([-2*pca.components_[0,0], 2*pca.components_[0,0]], [-2*pca.components_[0,1], 2*pca.components_[0,1]], color='gray')plt.text(0.5*pca.components_[0,0], 0.8*pca.components_[0,1], "$\mathregular{v}_1$", color='black', fontsize=20)plt.text(0.8*pca.components_[1,0], 0.8*pca.components_[1,1], "$\mathregular{v}_2$", color='black', fontsize=20)plt.show()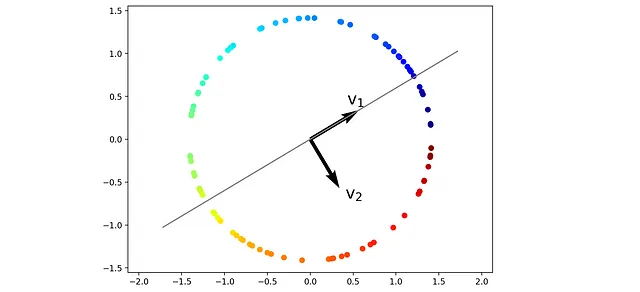
在此数据集中,最大的方差在圆形而不是直线上。然而,PCA 仍然假定投影后数据点的最大方差沿着向量 v ₁(第一个主成分)。
代码 18 计算了数据点在 v ₁ 上的投影坐标,并在图 25 中绘制了它们。
# 列表 18projected_points = pca.transform(X_circ)[:,0]fig = plt.figure(figsize=(16, 2))frame = plt.gca()plt.scatter(projected_points, [0]*len(projected_points), c=colors, cmap=plt.cm.jet, alpha =0.7)plt.axhline(y=0, color='grey')plt.xlabel("$v_1$", fontsize=18)#plt.xlim([-1.6, 1.7])frame.axes.get_yaxis().set_visible(False)plt.show()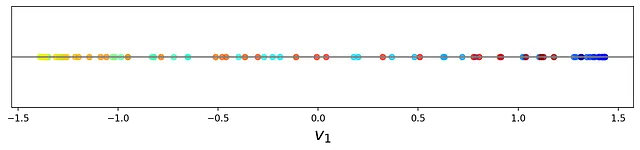
如您所见,投影后的数据点已经失去了它们的顺序并且颜色混合。现在我们在这个数据集上训练一个非线性自编码器。图 26 显示了它的架构。该网络有两个输入特征和两个输出层神经元。它有 5 个隐藏层,隐藏层中的神经元数量分别是 64、32、1、32 和 64。因此,瓶颈层只有一个神经元,这意味着我们希望将训练数据集的维数从 2 降至 1。
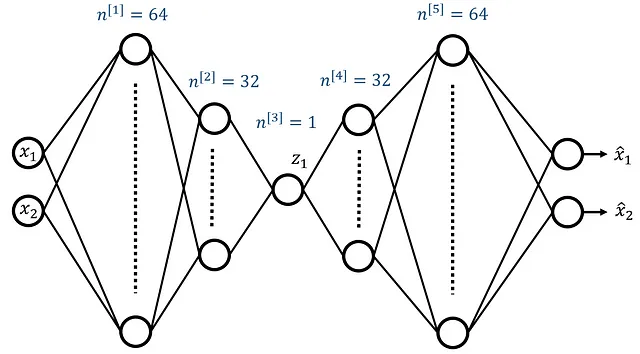
您可能已经注意到的一件事是,第一隐藏层中的神经元数量增加了。因此,只有隐藏层具有双面漏斗形状。因为我们只有两个输入特征,所以需要在第一隐藏层中添加更多的神经元以获得足够的神经元来训练网络。代码 19 定义了 PyTorch 中的自编码器网络。
# 列表 19seed = 3np.random.seed(seed)torch.manual_seed(seed)np.random.seed(seed)class Autoencoder(nn.Module): def __init__(self, in_shape, enc_shape): super(Autoencoder, self).__init__() # 编码器 self.encoder = nn.Sequential( nn.Linear(in_shape, 64), nn.ReLU(True), nn.Dropout(0.1), nn.Linear(64, 32), nn.ReLU(True), nn.Dropout(0.1), nn.Linear(32, enc_shape), ) #解码器 self.decoder = nn.Sequential( nn.BatchNorm1d(enc_shape), nn.Linear(enc_shape, 32), nn.ReLU(True), nn.Dropout(0.1), nn.Linear(32, 64), nn.ReLU(True), nn.Dropout(0.1), nn.Linear(64, in_shape) ) def forward(self, x): encoded = self.encoder(x) decoded = self.decoder(encoded) return encoded, decoded model2 = Autoencoder(in_shape=2, enc_shape=1).double()print(model2)现在,所有的隐藏层都有非线性的RELU激活函数。我们仍然使用MSE损失函数和Adam优化器。
loss_func = nn.MSELoss()optimizer = torch.optim.Adam(model2.parameters())我们使用X_circ作为训练数据集,但我们使用MinMaxScaler()将所有特征缩放到[0,1]范围内。
X_circ_scaled = MinMaxScaler().fit_transform(X_circ)X_circ_train = torch.from_numpy(X_circ_scaled)接下来,我们进行5000个epoch的模型训练。
# Listing 20def train(model, loss_func, optimizer, n_epochs, X_train): model.train() for epoch in range(1, n_epochs + 1): optimizer.zero_grad() encoded, decoded = model(X_train) loss = loss_func(decoded, X_train) loss.backward() optimizer.step() if epoch % int(0.1*n_epochs) == 0: print(f'epoch {epoch} \t Loss: {loss.item():.4g}') return encoded, decodedencoded, decoded = train(model2, loss_func, optimizer, 5000, X_circ_train)
epoch 500 Loss: 0.01391epoch 1000 Loss: 0.005599epoch 1500 Loss: 0.007459epoch 2000 Loss: 0.005192epoch 2500 Loss: 0.005775epoch 3000 Loss: 0.005295epoch 3500 Loss: 0.005112epoch 4000 Loss: 0.004366epoch 4500 Loss: 0.003526epoch 5000 Loss: 0.003085最后,我们将训练数据集中所有观测值的瓶颈层中的单个神经元的值(编码数据)绘制出来。记住,我们为训练数据集中的每个数据点分配了一种颜色。现在,我们使用相同的颜色来表示编码后的数据点。这个图像显示在Figure 27中,与PCA生成的投影数据点(Figure 25)相比,大多数投影数据点都有正确的顺序。
encoded = encoded.detach().numpy()fig = plt.figure(figsize=(16, 2))frame = plt.gca()plt.scatter(encoded.flatten(), [0]*len(encoded.flatten()), c=colors, cmap=plt.cm.jet, alpha =0.7)plt.axhline(y=0, color='grey')plt.xlabel("$z_1$", fontsize=18)frame.axes.get_yaxis().set_visible(False)plt.show()
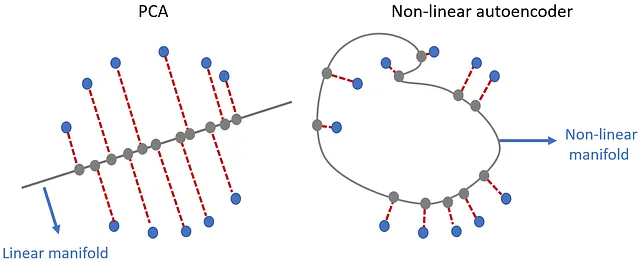
这是因为非线性自编码器不再将原始数据点投影到一条直线上。自编码器试图找到一条曲线(也称为非线性流形),沿着这条曲线,投影数据点的方差最大,并将输入数据点投影在这些曲线上(Figure 28)。这个例子清楚地展示了自编码器比PCA的优点。PCA是线性变换,因此不适用于具有非线性相关性的数据集。另一方面,我们可以在自编码器中使用非线性激活函数。这使我们能够使用自编码器进行非线性降维。
在本文中,我们讨论了PCA、SVD和自编码器背后的数学原理。PCA为数据集找到一个新的正交坐标系。这个坐标系的每个轴都称为主成分。选择主成分的方法是使得投影到每个坐标轴上的数据点的方差在已经考虑的主成分的所有正交方向中最大。
线性自编码器和PCA有一些相似之处。我们看到,具有中心化输入特征、线性激活和MSE损失函数的自编码器可以找到与主成分张成的子空间相同的子空间。我们也得到了与PCA相同的投影数据点。但是,它不能找到主成分本身。事实上,它返回的基向量甚至不一定是正交的。
另一方面,自编码器比PCA更灵活。 PCA的一个问题是它假设投影数据点的最大方差沿着由主成分表示的线。 因此,如果最大方差沿着非线性曲线,PCA无法找到它。 但是,具有非线性激活函数的自编码器能够找到非线性流形并将数据点投影到其上。
希望您喜欢阅读本文。 如果您有任何问题或建议,请告诉我。本文中的所有代码清单都可以从GitHub作为Jupyter Notebook下载:
https://github.com/reza-bagheri/autoencoders_pca
附录
找到主成分的方程:
对于第二个主成分,我们需要找到最大化的向量u ₂
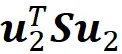
这些约束条件:
这意味着我们需要最大化
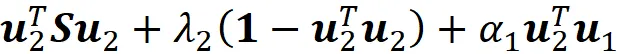
关于u₂的最大点我们可以写成:
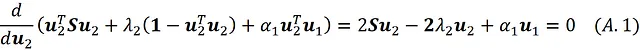
通过将此方程乘以u₁ᵀ,我们得到:
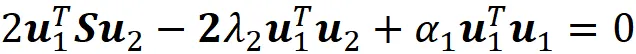
现在使用方程7和协方差矩阵是对称矩阵这个事实,我们可以写成:
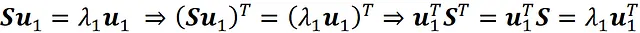
通过将此方程代入前一个方程,我们得到:
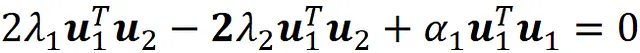
现在使用正交约束和u₁被归一化的事实,我们得到:

使用此方程和方程A.1,得出
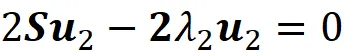
因此,我们有
我们还需要找到向量uᵢ,最大化
这些约束条件:
这相当于最大化
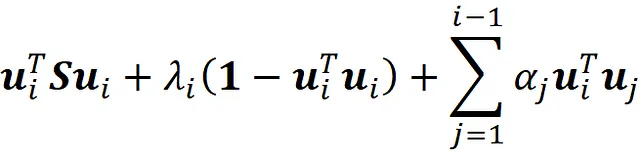
关于uᵢ的。为了找到最大值点,我们将此项关于uᵢ的导数设为零:
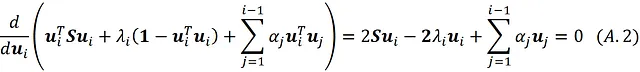
通过将此方程乘以uₖᵀ(其中1≤k≤i-1),我们得到:
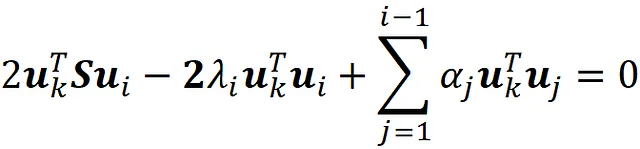
我们知道先前的主成分是S的特征向量,而S是对称矩阵。因此,我们有:
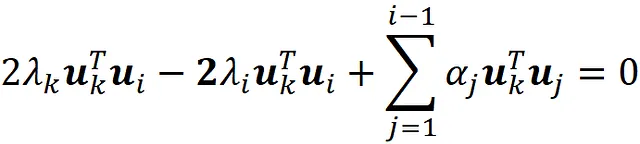
并且使用正交约束,我们得出:

通过将此方程代入方程A.2,我们得出
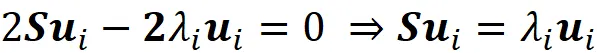
因此,uᵢ是S的特征向量,λᵢ是其对应的特征值。
方程17的证明:
假设我们有秩为r的m×n矩阵X,并且X的奇异值已排序,因此我们有:
我们要证明
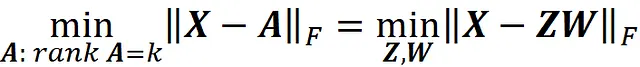
其中A是秩为k的m×n矩阵,Z和W是m×k和k×n矩阵。我们知道k < n。此外,在设计矩阵中,我们通常有m > n。因此,k小于m和n。
我们知道,矩阵的秩不能超过其行数或列数。因此,我们有:
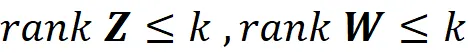
还可以证明
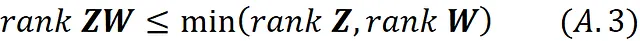
因此,我们有:
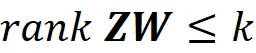
因此,ZW的秩不能超过k。此外,我们将展示,最小化||X–ZW||F的矩阵ZW的秩不能小于k。假设Z*和W*是两个矩阵,使得Z*W*是最小化所有秩为k矩阵中||X–ZW||F的矩阵,那么根据方程16:
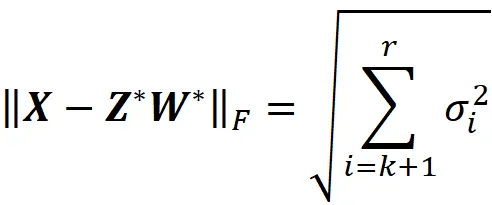
同样地,让 Z ** 和 W ** 为两个矩阵,以便Z ** W **是一个排名为m的矩阵(m < k),该矩阵在所有排名为m的矩阵中最小化|| X – Z ** W ** || _F。我们有:

很明显

因此

这意味着排名为k的矩阵始终给出较低的|| X – Z W || _F值。因此我们得出结论,ZW的排名不能小于k。因此,最小化|| X – Z W || _F的最优ZW值应该是一个排名为k的矩阵。
线性自动编码器的成本函数:
我们想要展示
为了证明它,我们首先计算矩阵 X – Z ( W^ [2])ᵀ:
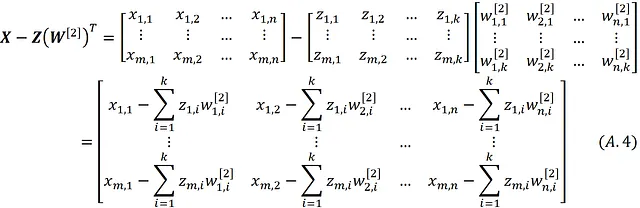
但根据方程式22,我们有:
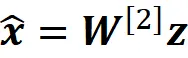
因此对于第k个观察值,我们可以写成:
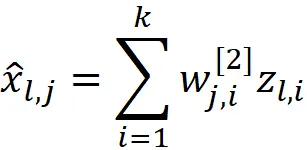
通过将此等式代入方程A.4,我们有:
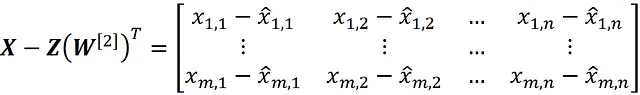
最后,使用方程式15,我们得到: