使用 Sigma 规则进行异常检测:构建自己的 Spark 流式检测
轻松部署 Sigma 规则在 Spark 流水线中: 一种支持即将到来的 Sigma 2 规范的未来方案

在我们之前的文章中,我们详细阐述并设计了一个名为 flux-capacitor 的状态函数。
flux-capacitor 是一种能够记住日志事件之间的父子关系(和祖先)的有状态函数。它还可以记住在一定时间窗口内发生在同一主机上的事件,Sigma 规范将其称为时态相似性相关性。
关于 flux-capacitor 的设计的深入分析,请参阅 part 1、part 2、part 3、part 4 和 part5。但是,您无需理解函数的实现即可使用它。
在本文中,我们首先展示了一个执行离散检测的 Spark 流式作业。 离散检测是使用单个日志行(单个事件)的特征和值的 Sigma 规则。
然后,我们利用 flux-capacitor 函数来处理日志事件之间的有状态的父子关系。 flux-capacitor 还能够检测在一定时间窗口内发生在同一主机上的一些事件;这些在即将到来的 Sigma 规范中称为时态相似性相关性。这些 Spark 流式作业的完整演示可在我们的 git 仓库中找到。
离散检测
执行离散测试相当简单,这要归功于 Spark 中内置的所有功能。Spark 支持读取流式源、写入接收器、检查点、流流连接、窗口聚合等等。有关所有可能功能的完整列表,请参阅 Spark 结构化流编程指南。
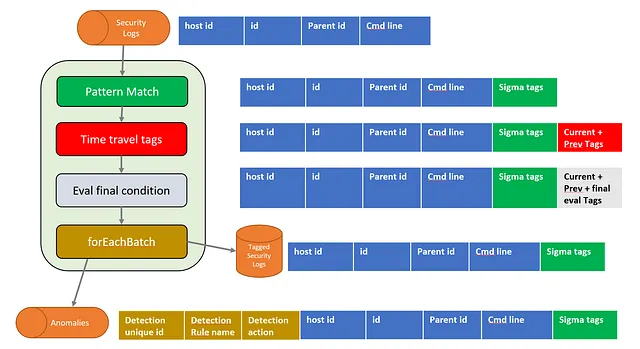
下面是一个高层次的图示,显示了一个 Spark 流式作业,该作业从“start-process”窗口事件的 Iceberg 表中消耗事件(1)。Windows 安全日志(事件 ID 4688)中就有这样的典型示例。

源表(1)名为 process_telemetry_table。Spark 作业读取所有事件,检测异常事件,标记这些事件并将它们写入名为 tagged_telemetry_table 的表(3)。被认为是异常的事件也会被写入一个包含警报的表(4)。
定期我们会轮询包含我们想应用的 Sigma 规则的 SQL 自动生成的 git 仓库(5)。如果 SQL 语句发生更改,我们会重新启动流式作业,将这些新检测添加到流水线中。
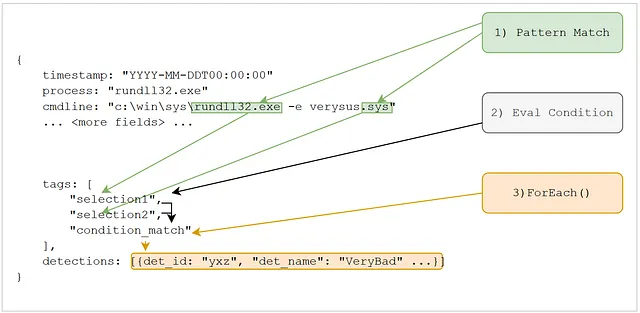
让我们以这个 Sigma 规则为例:

detection 部分是 Sigma 规则的核心,由一个 condition 和一个或多个命名测试组成。 selection1 和 selection2 是命名的布尔测试。 Sigma 规则的作者可以为这些测试赋予有意义的名称。 condition 是用户可以在其中将测试组合成最终评估的地方。有关编写 Sigma 规则的更多详细信息,请参阅 Sigma 规范。
从现在开始,我们将把这些命名的布尔测试称为标签。
Spark 流式作业的内部工作分为 4 个逻辑步骤:
- 读取源表
process_telemetry_table - 执行模式匹配
- 评估最终条件
- 写入结果
模式匹配步骤包括评估Sigma规则中找到的标签,评估最终条件评估condition。
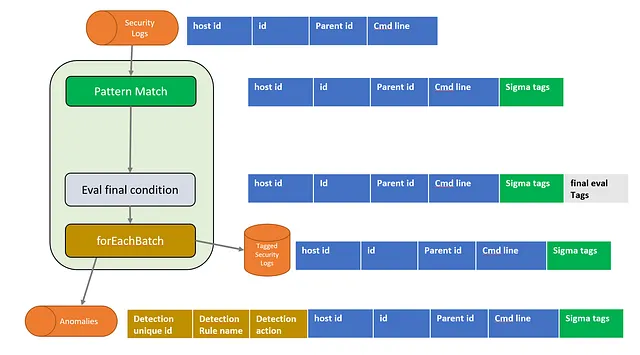
在图表的右侧,我们展示了此处理阶段的行表示形式。蓝色的列代表从源表中读取的值。模式匹配步骤添加了一个名为Sigma tags的列,其中包含执行的所有测试和测试是否通过的映射。灰色的列包含最终的Sigma规则评估。最后,棕色的列是在foreachBatch函数中添加的。生成GUID,从Sigma标签映射中提取为True的规则名称并从规则名称到规则类型的查找映射中检索检测action。这为生成的警报提供了上下文。
此图表描述了将事件的属性组合成标签、最终评估和最终上下文信息的过程。
现在让我们看看实际的pyspark代码。首先,我们使用readStream函数将Spark连接到源表,并指定从中读取冰山表的名称。load函数返回一个数据框,我们使用它来创建一个名为process_telemetry_view的视图。
spark .readStream .format("iceberg") .option("stream-from-timestamp", ts) .option("streaming-skip-delete-snapshots", True) .option("streaming-skip-overwrite-snapshots", True) .load(constants.process_telemetry_table) .createOrReplaceTempView("process_telemetry_view")process_telemetry_view中的数据如下:
+-------------------+---+---------+---------------------+ |timestamp |id |parent_id|Commandline |+-------------------+---+---------+---------------------+|2022-12-25 00:00:01|11 |0 | ||2022-12-25 00:00:02|2 |0 |c:\win\notepad.exe ||2022-12-25 00:00:03|12 |11 | ||2022-12-25 00:00:08|201|200 |cmdline and args ||2022-12-25 00:00:09|202|201 | ||2022-12-25 00:00:10|203|202 |c:\test.exe |+-------------------+---+---------+---------------------+在这个视图上,我们应用了一个模式匹配步骤,它由Sigma编译器生成的自动生成的SQL语句组成。 patern_match.sql文件如下:
select *, -- regroup each rule's tags in a map (ruleName -> Tags) map( 'rule0', map( 'selection1', (CommandLine LIKE '%rundll32.exe%'), 'selection2', (CommandLine LIKE '%.sys,%' OR CommandLine LIKE '%.sys %'), ) ) as sigmafrom process_telemetry_view我们使用spark.sql()将此语句应用于process_telemetry_view视图。
df = spark.sql(render_file("pattern_match.sql"))df.createOrReplaceTempView("pattern_match_view")请注意,Sigma规则中找到的每个标签的结果都存储在布尔值的映射中。 sigma列保存了每个Sigma规则中找到的每个标签的结果。通过使用MapType,我们可以轻松地引入新的Sigma规则,而不会影响表的模式。添加新规则只需在sigma列(MapType)中添加新条目即可。
+---+---------+---------------------+----------------------------------+|id |parent_id|Commandline |sigma+---+---------+---------------------+----------------------------------+|11 |0 | |{rule0 -> { selection1 -> false, selection2 -> false }, }类似地,评估最终条件步骤应用Sigma规则中的条件。将condition编译成SQL语句,使用map、map_filter、map_keys构建名为sigma_final的列。该列保存所有具有condition为真的规则的名称。
select *, map_keys( -- 仅保留规则名为真的规则 map_filter( -- 过滤映射条目,仅保留评估为真的规则 map( -- 在映射中存储每个规则的条件结果 'rule0', -- rule 0 -> condition: all of selection* sigma.rule0.selection1 AND sigma.rule0.selection2) ) , (k,v) -> v = TRUE)) as sigma_finalfrom pattern_match_view使用spark.sql()应用自动生成的语句。
df = spark.sql(render_file("eval_final_condition.sql"))这是新添加的sigma_final列的结果,一个触发的规则数组。
+---+---------+-------------------------------------+-------------+|id |parent_id|sigma | sigma_final |+---+---------+-------------------------------------+-------------+|11 |0 |{rule0 -> { | [] | selection1 -> false, selection2 -> false } }我们现在准备为DataFrame启动流作业。请注意,我们将回调函数for_each_batch_function传递给foreachBatch。
streaming_query = ( df .writeStream .queryName("detections") .trigger(processingTime=f"{trigger} seconds") .option("checkpointLocation", get_checkpoint_location(constants.tagged_telemetry_table) ) .foreachBatch(foreach_batch_function) .start() )streaming_query.awaitTermination()for_each_batch_function在每个微批次中调用,并给出评估的batchdf数据框。 for_each_batch_function将batchdf的整体写入tagged_telementry_table,并为任何评估为真的Sigma规则编写警报。
def foreach_batch_function(batchdf, epoch_id): # Transform and write batchDF batchdf.persist() batchdf.createOrReplaceGlobalTempView("eval_condition_view") run("insert_into_tagged_telemetry") run("publish_suspected_anomalies") spark.catalog.clearCache()有关insert_into_tagged_telemetry.sql和publish_suspected_anomalies.sql的详细信息可以在我们的git repo中找到。
如上所述,使用Spark中的内置功能编写流异常检测处理离散测试相对简单。
基于过去事件的检测
到目前为止,我们展示了如何使用离散Sigma规则检测事件。在本节中,我们利用flux-capacitor函数使标签缓存和测试过去事件的标签。如我们之前的文章所讨论的,flux-capacitor函数允许我们检测过去事件的父子关系以及过去事件的仲裁特征序列。
这些类型的Sigma规则需要同时考虑当前事件和过去事件的标签。为了执行最终规则评估,我们引入了一个时间旅行标签步骤,以检索事件的所有过去标签,并将其与当前事件合并。这就是flux-capacitor函数的设计目的,它缓存和检索过去的标签。现在,过去的标签和当前的标签在同一行,评估最终条件就像我们在上面的离散示例中所做的那样进行评估。
检测现在看起来像这样:
flux-capacitor给出了由Pattern Match步骤产生的Sigma tags。flux-capacitor将这些标签存储以供以后检索。红色列具有与之前使用过的Sigma tags列相同的架构。但是,它结合了当前和过去的标签,这些标签是flux-capacitor从其内部状态中检索的。
添加缓存和检索过去标记非常容易,这得益于flux-capacitor函数。以下是我们如何在Spark异常检测中应用flux-capacitor函数的步骤。首先,将Pattern Match步骤产生的数据框传递给flux_stateful_function,该函数返回另一个数据框,其中包含过去的标记。
flux_update_spec = read_flux_update_spec()bloom_capacity = 200000# reference the scala codeflux_stateful_function = spark._sc._jvm.cccs.fluxcapacitor.FluxCapacitor.invoke# group logs by host_idjdf = flux_stateful_function( pattern_match_df._jdf, "host_id", bloom_capacity, flux_update_spec)output_df = DataFrame(jdf, spark)为了控制flux_stateful_function的行为,我们传入一个flux_update_spec。flux-capacitor规范是由Sigma编译器生成的yaml文件。规范详细说明了应缓存和检索哪些标记以及如何处理它们。action属性可以设置为parent、ancestor或temporal。
让我们从Sigma HQ proc_creation_win_rundll32_executable_invalid_extension.yml中使用一个具体的例子。

再次提醒,检测的核心由标记和最终的condition组成,该condition将所有这些标记放在一起。但请注意,此规则(我们将其称为规则1)涉及对CommandLine的测试以及对父进程ParentImage的测试。ParentImage不是在启动进程日志中找到的字段。相反,它指的是父进程的Image字段。
如前所述,该Sigma规则将编译成SQL来评估标记并将它们组合成一个最终条件。
为了传播父标记,Sigma编译器还会生成flux-capacitor规范。规则1是一个parent规则,因此规范必须指定哪些是父字段和子字段。在我们的日志中,这些对应于id和parent_id。
该规范还指定了哪些tags应由flux-capacitor函数缓存和检索。以下是自动生成的规范:
rules: - rulename: rule1 description: proc_creation_win_run_executable_invalid_extension action: parent tags: - name: filter_iexplorer - name: filter_edge_update - name: filter_msiexec_system32 parent: parent_id child: id请注意,规则0不包含在flux-capacitor函数中,因为它没有时间标记。
说明标记传播
为了更好地理解flux-capacitor的作用,您可以在流分析外部使用该函数。这里我们展示一个简单的ancestor示例。我们要传播标记pf。例如,pf可以表示包含rundll32.exe的CommandLine。
spec = """ rules: - rulename: rule2 action: ancestor child: pid parent: parent_pid tags: - name: pf """df_input = spark.sql(""" select * from values (TIMESTAMP '2022-12-30 00:00:05', 'host1', 'pid500', '', map('rule1', map('pf', true, 'cf', false))), (TIMESTAMP '2022-12-30 00:00:06', 'host1', 'pid600', 'pid500', map('rule1', map('pf', false, 'cf', false))), (TIMESTAMP '2022-12-30 00:00:07', 'host1', 'pid700', 'pid600', map('rule1', map('pf', false, 'cf', true))) t(timestamp, host_id, pid, parent_pid, sigma) """)打印数据框 df_input 我们可以看到pid500启动并具有具有pf特征的CommandLine。然后,pid500启动pid600.稍后pid600启动pid700。Pid700有一个子特征cf。
+-------------------+------+----------+--------------+-------------------------------------+|timestamp |pid |parent_pid|human_readable|sigma |+-------------------+------+----------+--------------+-------------------------------------+|2022-12-30 00:00:05|pid500| |[pf] |{rule2 -> {pf -> true, cf -> false}} ||2022-12-30 00:00:06|pid600|pid500 |[] |{rule2 -> {pf -> false, cf -> false}}||2022-12-30 00:00:07|pid700|pid600 |[cf] |{rule2 -> {pf -> false, cf -> true}} |+-------------------+------+----------+--------------+-------------------------------------+Sigma规则是pf和cf的组合。为了将pf标记带回到当前行,我们需要对pf标记进行时间旅行。对df_input数据框应用flux-capacitor函数,
jdf = flux_stateful_function(df_input._jdf, "host_id", bloom_capacity, spec, True)df_output = DataFrame(jdf, spark)我们获得了df_output数据框。请注意,pf标记如何通过时间传播。
+-------------------+------+----------+--------------+------------------------------------+|timestamp |pid |parent_pid|human_readable|sigma |+-------------------+------+----------+--------------+------------------------------------+|2022-12-30 00:00:05|pid500| |[pf] |{rule2 -> {pf -> true, cf -> false}}||2022-12-30 00:00:06|pid600|pid500 |[pf] |{rule2 -> {pf -> true, cf -> false}}||2022-12-30 00:00:07|pid700|pid600 |[pf, cf] |{rule2 -> {pf -> true, cf -> true}} |+-------------------+------+----------+--------------+------------------------------------+此笔记本TagPropagationIllustration.ipynb包含更多类似于此的父子和时间接近性示例。
建立具有上下文的警报
flux-capacitor函数缓存所有过去的标记。为了节省内存,它使用布隆过滤器段缓存这些标记。布隆过滤器具有极小的内存占用量,查询和更新速度快。然而,它们确实会引入可能的误报。因此,我们将怀疑的异常放入队列(4)进行重新评估。
为了消除误报,第二个Spark流作业名为警报生成器读取疑似异常(5),并检索需要重新评估规则的事件(6)。
例如,在父子Sigma规则的情况下,警报生成器将读取疑似异常(5),检索子进程事件。接下来,在(6)中,它将检索此子事件的父进程。然后使用这两个事件重新评估Sigma规则。但是,这次flux-capacitor被配置为将标记存储在哈希映射中,而不是在布隆过滤器中。这消除了误报,并且作为奖励,我们拥有所有涉及此检测的事件。我们将此警报与证据行(父事件和子事件)一起存储到警报表(7)中。
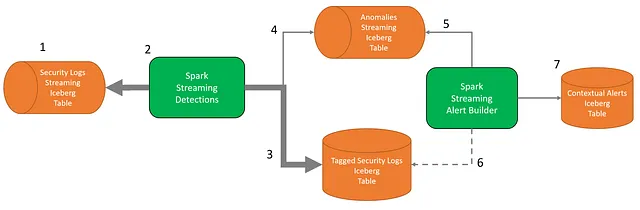
警报生成器(Alert Builder)处理的数据量仅为(2)流式检测的一小部分。由于将(5)历史搜索中读取的数据量低,因此可以对标记的遥测进行搜索(6)。
要进行更深入的了解,请查看流式检测streaming_detections.py和警报生成器streaming_alert_builder.py的Spark作业。
性能
为了评估此概念验证的性能,我们在具有 16 个 CPU 和 64G 内存的机器上运行了测试。我们编写了一个简单的数据生成器,每秒创建 5,000 个合成事件,并在 30 天内运行了实验。
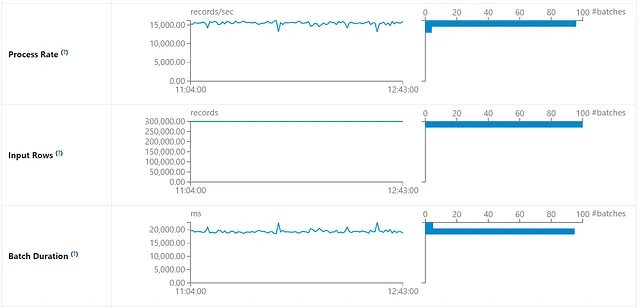
Spark 流式检测作业在一台机器上运行。该作业配置为每分钟触发一次。每个微批次(触发器)读取 300,000 个事件,平均需要 20 秒来完成。该作业可以轻松跟上传入事件的速度。
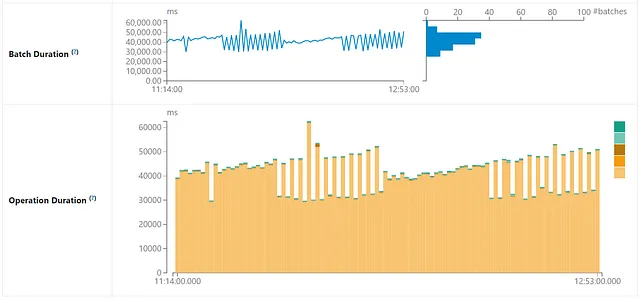
Spark Alert Builder 也在单台机器上运行,并配置为每分钟触发一次。该作业需要 30 到 50 秒钟才能完成。此作业对的组织非常敏感。这里我们看到维护作业的效果,每小时组织和排序最新数据。因此,每小时,Spark Alert Builder 的微批次执行时间会降至 30 秒。
表维护
我们的 Spark 流式作业每分钟触发一次,因此每分钟产生小型数据文件。为了允许在此表中进行快速搜索和检索,定期压缩和排序数据非常重要。幸运的是,Iceberg 自带用于组织和维护表的内置过程。
例如,此脚本maintenance.py每小时运行一次,以对Iceberg中的tagged_telemetry_table 的新添加的文件进行排序和压缩。
CALL catalog.system.rewrite_data_files( table => 'catalog.jc_sched.tagged_telemetry_table', strategy => 'sort', sort_order => 'host_id, has_temporal_proximity_tags', options => map('min-input-files', '100', 'max-concurrent-file-group-rewrites', '30', 'partial-progress.enabled', 'true'), where => 'timestamp >= TIMESTAMP \'2023-05-06 00:00:00\' ' )最后,我们也重新对此表进行排序,从而在长时间搜索期间(数月的数据)获得最大的搜索性能。
CALL catalog.system.rewrite_data_files( table => 'catalog.jc_sched.tagged_telemetry_table', strategy => 'sort', sort_order => 'host_id, has_temporal_proximity_tags', options => map('min-input-files', '100', 'max-concurrent-file-group-rewrites', '30', 'partial-progress.enabled', 'true', 'rewrite-all', 'true'), where => 'timestamp >= TIMESTAMP \'2023-05-05 00:00:00\' AND timestamp < TIMESTAMP \'2023-05-06 00:00:00\' ' )我们进行的另一个维护任务是从流式表中删除旧数据。这些表仅用作生产者和消费者之间的缓冲区。因此,每天我们都会过期流式表,保留 7 天的数据。
delete from catalog.jc_sched.process_telemetry_tablewhere timestamp < current_timestamp() - interval 7 days最后,每天我们执行标准的 Iceberg 表维护任务,例如过期快照和删除孤立的文件。我们在所有表上运行这些维护作业,并在 Airflow 上安排这些作业。
结论
本文展示了如何构建一个Spark流异常检测框架,通用地应用Sigma规则。新的Sigma规则可以轻松地添加到系统中。
这个概念验证在合成数据上进行了广泛测试,以评估其稳定性和可扩展性。它显示出巨大的潜力,将在生产系统上进行进一步的评估。
除非另有说明,所有图片均由作者提供