应用和使用正态分布进行数据科学
使用正态分布进行数据科学
数据科学步骤
回顾正态分布在数据科学中的各种应用
介绍
在开始数据科学之旅时,有一件非常困难的事情是弄清楚这个旅程的起点和终点在哪里。就数据科学旅程的终点而言,重要的是记住,该领域每天都在取得进展,必然会有新的发展 —— 请做好大量学习的准备。数据科学不仅包括科学、统计和编程,还涉及其他几个学科。
为了减少数据科学的压力,重要的是要以小块的信息来学习。深入研究和学习领域的特定领域(如数据、编程、机器学习、分析或科学)可能非常有趣。虽然这让我兴奋,但有时候也很好将焦点集中在一个特定的主题上,并尽可能地了解所有相关内容。对于初学者来说,这些相互关联的领域可能不是一个明确的起点。我要证明的一件事是,统计学和正态分布是开始学习数据科学的好地方。我写了一篇文章,详细介绍了为什么以及如何使用正态分布。我们在这里对这篇文章进行简要总结,但会略去许多细节。
学习数据科学统计的第一件事 —— 正态分布
简单正态分布的概述和编程。
chifi.dev
如上所述,正态分布是一个简单的概率密度函数(PDF),我们可以将其应用于我们的数据。这个函数,我们将其称为 f ,计算平均值 x 是在 f(x) 中的标准偏差的数量。我们需要从平均值获得标准偏差,我们应该如何检查一个值与平均值相差多少个标准偏差呢?首先,我们需要看一下它距离平均值有多远,对吧?然后我们需要看一下这个差异是多少个标准偏差。所以这正是我们在公式中所做的。对于每个 x ,我们减去平均值,然后将差异除以标准偏差。在统计学中,小写的西格玛(σ)表示标准偏差,小写的μ表示平均值。在下面的公式中,x bar(x̄)表示观察值(上面的 x 在 f(x) 中)。
进入编程语言
在上一篇文章的结尾,我们将其转换为了一种编程语言 —— Julia。编程语言的选择完全取决于数据科学家,但也需要考虑一些权衡,并且重要的是考虑行业的发展。例如,R 是一种相对较慢的语言,但有着经过优秀开发人员多年维护的分析包和出色的仪表盘工具。目前最受欢迎的选择可能是 Python,因为它与 C 库的连接速度快且易于使用。Julia 是一种相对较新的语言,但它是我最喜欢的编程语言之一,我认为大多数数据科学家都应该了解它。尽管 Julia 的受欢迎程度飙升,但如果你同时了解这两种语言,那么你将拥有更多的工作机会。幸运的是,大多数常用于数据科学的流行语言往往有很多共同之处,它们之间的参考也很容易。这是我们用 Python 和 Julia REPL 分别编写的正态分布代码。
python
>>> from numpy import mean, std>>> x = [5, 10, 15]>>> normed = [(mean(x) - i) / std(x) for i in x]>>> print(normed)[1.224744871391589, 0.0, -1.224744871391589]julia
julia> 使用Statistics:std,meanjulia> x = [5, 10, 15]3个元素的Vector{Int64}: 5 10 15julia> normed = [(mean(x) - i) / std(x) for i in x]3个元素的Vector{Float64}: 1.0 0.0 -1.0这里还有每种编程语言的笔记本。我将使用这三种语言的笔记本,不仅是为了使教程对每个人都易于理解,而且还推广了多语言交流的理念。这些语言相当相似且很容易阅读,因此很容易对比和对比它们之间的差异,看看你喜欢哪种语言,并深入探讨每种语言的权衡。
笔记本
python
Emmetts-DS-NoteBooks/Python3/Applying the normal distribution (py).ipynb at master ·…
各种项目的随机笔记本。通过创建帐户为emmettgb/Emmetts-DS-NoteBooks做出贡献…
github.com
julia
Emmetts-DS-NoteBooks/Julia/Applying the normal distribution.ipynb at master ·…
各种项目的随机笔记本。通过创建帐户为emmettgb/Emmetts-DS-NoteBooks做出贡献…
github.com
设置我们的函数
我们首先需要一个函数,用于给出一组数字的向量的标准值。这很简单,只需要获取平均值和标准差,然后将两者和我们的xbars插入到我们的公式中。此函数将接受一个参数,即我们的向量,然后返回我们的标准化向量。当然,我们还需要平均值和标准差 – 我们可以使用依赖项来实现。在Python中,我们将使用Numpy的mean和std函数。在Julia中,我们将使用Statistics.mean和Statistics.std。但是,今天我们将从头开始完成所有操作,因此这里是我在Python和Julia中的简单平均值和标准差函数:
# pythonimport math as mtdef mean(x : int): return(sum(x) / len(x))def std(arr : list): m = mean(arr) arr2 = [(i-m) ** 2 for i in arr] m = mean(arr2) m = mt.sqrt(m) return(m)
# juliamean(x::Vector{<:Number}) = sum(x) / length(x)function std(array3::Vector{<:Number}) m = mean(array3) [i = (i-m) ^ 2 for i in array3] m = mean(array3) try m = sqrt(m) catch m = sqrt(Complex(m)) end return(m)end现在我们有了一些函数来获取我们函数所需的值,我们需要将所有这些封装到一个函数中。这很简单,我将使用上面的方法获得我们的总体均值和标准差,然后使用一个推导式来从每个观察值中减去均值,然后除以标准差。
# pythondef norm(x : list): mu = mean(x) sigma = std(x) return([(xbar - mu) / sigma for xbar in x])
# juliafunction norm(x::Vector{<:Number}) mu::Number = mean(x) sigma::Number = std(x) [(xbar - mu) / sigma for xbar in x]::Vector{<:Number}end现在让我们尝试一下我们的归一化函数。这是一个很容易测试的函数,我们只需要提供一个我们知道平均值的向量。这是因为我们的向量的平均值应该为零。所以在[5, 10, 15]这种情况下,0应该是10-[5, 10, 15]的平均值。5应该是约为-1.5,即离平均值一个标准差(在这种情况下,我们的标准差等于数值2.5)。
norm([5, 10, 15])[-1.224744871391589, 0.0, 1.224744871391589]在正态分布上,当数值接近平均值的两个标准差时通常会引起注意。换句话说,如果大多数人的身高约为10英寸,而有人的身高为20英寸,那么这将距离平均值3个标准差,具有统计学显著性。
mu = mean([5, 10, 15])sigma = std([5, 10, 15])(15 - mu) / sigma1.5811388300841895(20 - mu) / sigma3.162277660168379用于分析的正态分布
Z分布,或者正态分布,在数据分析中也有很多应用。这个分布可以用于测试,但不像T检验那样常用。这是因为正态分布的尾部较短。因此,它通常用于在样本量大且方差已知的情况下进行的测试。与T分布等进行比较,我们可以看到T分布的尾部更长。这意味着有更长的统计学显著性区域,因此更容易检测。

这种类型的测试,Z检验,将测试两个总体均值是否足够不同以至于具有统计学意义。公式与之前我们从概率密度函数中看到的公式非常相似,因此在这里并没有太多新东西。我们只需要将xbar更改为表示我们要测试的总体的均值,而不是使用每个观察值。这个测试将返回一个称为Z统计量的值。类似于T统计量,这个值将通过另一个函数转换为概率值。让我们创建一个一维的观测集合,并看看我们如何执行这样的测试。
pop = [5, 10, 15, 20, 25, 30]mu = mean(pop)sigma = std(pop)我们将从中间随机选择一个样本,并计算Z统计量:
xbar = mean(pop[3:5])现在我们只需要将它代入我们的公式…
(xbar - mu) / sigma0.5976143046671968这个新的数值就是我们的Z统计量。将这些统计值转换为概率值的数学计算相当复杂。这两种语言中都有一些库可以帮助处理这些问题。对于Julia,我推荐使用HypothesisTests,对于Python,我推荐使用scipy模块。在本文中,我们将使用一个在线的Z统计量到概率值的计算器。让我们将我们的Z统计量代入其中:
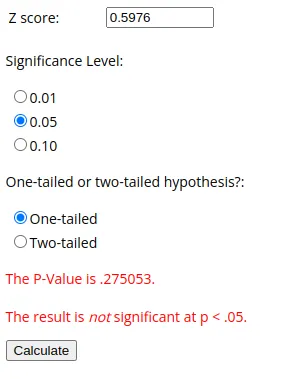
正如我们预料的那样,我们的一些样本人口与其他样本和均值非常接近,统计上并没有显著差异。也就是说,我们当然可以尝试一些更具统计显著性的实验,并拒绝我们的零假设!
xbar = mean([50, 25, 38])(xbar - mu) / sigma4.820755390982054
正态分布在测试中确实效果良好。关键在于要理解这种形式的测试需要大样本量,并不适用于所有数据。在大多数情况下,对于初学者,我建议从易于测试的分布开始,例如T分布。对于Z测试来说,数据更加重要,对于初学者来说很难找到大量的数据来源,而且即使在统计上显著时,获得统计上显著的结果也更加困难。
正态分布还可以在数据科学项目中某种程度上用于快速分析。将数据转化为与总体的关系可以极大地帮助我们从数据可视化到确定给定总体的差异程度等方面了解总体。通过调查我们的观察结果与均值的关系,我们可以了解到关于总体的很多信息。如果您想了解更多关于这个过程的信息,我有一个适合初学者的概述,可能对这种情况有所帮助,您可以在这里阅读:
一个适合初学者的应用科学简介
学习特征和统计分析的基础知识
towardsdatascience.com
数据归一化的正态分布
正态分布的另一个重要应用是利用该分布对数据进行归一化处理。连续特征可能会受到几个不同因素的干扰,其中最重要的因素之一可能是异常值。我们需要将异常值从数据中剔除,以使我们的数据具有普遍性。记住,构建优质数据的关键是构建一个优秀的总体。我所说的是,我们希望数据的完整性,例如均值等,能代表数据在某种程度上本来应该具有的特征。这样,每当有不同的东西出现时,就会变得非常明显。
鉴于正态分布告诉我们一个值与均值的偏差有多大,我们可以很容易地看出我们可以如何使用它进行数据归一化。如前所述,2.0左右是开始显著的位置。也就是说,我们可以制作一个掩码并使用它来过滤掉不良值!
# juliafunction drop_outls(vec::Vector{<:Number}) normed = norm(vec) mask = [~(x <= -2 || x >= 2) for x in normed] normed[mask]end通过这个简单的掩码过滤,我们增加了判断值是否远离均值并基于此丢弃它们的能力。在大多数情况下,我们可能还希望用均值替换这些异常值,以便不会丢失其他特征或目标的观察结果。
# pythondef drop_outls(vec : list): mu = mean(vec) normed = norm(vec) mask = [x <= -2 or x >= 2 for x in normed] ret = [] for e in range(1, len(mask)): if mask[e] == False: ret.append(vec[e]) else: ret.append(mu) return(ret)正态分布用于特征缩放
正态分布在数据科学中的最后一个常见应用是标准缩放。标准缩放就是将正态分布应用于您的数据。这种缩放器非常有帮助,因为它可以帮助将您的数据转化为更与其所属特征相关的数据。这对于机器学习非常有帮助,并且使得根据您拥有的连续特征轻松提高模型的准确性。使用标准缩放器非常简单,只需像以前一样使用我们的概率密度函数并获得归一化特征即可。
myX = [1, 2, 3, 4, 5]normedx = norm(x)这是用于提供给机器学习的数据。正态分布经常被用来处理许多机器学习模型中的连续特征,这些模型每天都在使用。
总结
总而言之,正态分布是统计学和数据科学的基本构建模块,在数据科学的许多不同应用中广泛使用。在该领域中,有许多不同的主题往往会以这种方式展开;开始相对简单,最终演变成相当复杂。深入研究一个主题确实是很好的,正态分布也不例外,因为这个基本且简单的分布确实非常有趣。感谢大家的阅读,希望这个概述对您有所帮助!





