掌握模型可解释性:全面了解部分依赖图
Understanding Model Interpretability Comprehensive Understanding of Partial Dependence Plots.
开始你在可解释AI世界的旅程。
了解如何解释你的模型是理解它是否有奇怪行为的关键。你对模型的了解越多,当它投入生产时,你就越不会对它的行为感到惊讶。
此外,你对模型的掌握越深,你就越能够向业务部门推销它。最糟糕的情况是他们意识到你其实不确定自己在向他们销售什么。
我从未开发过一个模型,不需要解释如何根据输入变量进行预测。至少,告诉业务部门哪些特征对预测结果产生了积极或消极的影响是必要的。
你可以使用的一种工具来理解你的模型如何工作是偏依赖图(PDP),我们将在本文中探讨。
PDP是什么
PDP是一种全局解释性方法,重点是展示模型的特征值与输出的相关性。
它不是一种了解数据的方法,它只为你的模型生成洞见,因此不能从该方法中推断目标和特征之间的因果关系。然而,它可以让你对模型进行因果推断。
这是因为该方法会探测你的模型,因此你可以看到特征变量发生变化时模型的确切行为。
工作原理
首先,PDP允许我们一次只研究一个或两个特征。在本文中,我们将重点关注单一特征分析的情况。
在训练完你的模型后,我们生成一个探测数据集。该数据集是按照以下算法创建的:
- 选择我们感兴趣的特征的每个唯一值
- 对于每个唯一值,我们复制整个数据集,并将特征值设置为该唯一值
- 然后,我们使用我们的模型对这个新数据集进行预测
- 最后,我们对每个唯一值的模型预测结果进行平均
让我们举个例子。假设我们有以下数据集:

现在,如果我们想对特征0应用PDP,我们将为该特征的每个唯一值重复数据集,例如:

然后,在应用我们的模型之后,我们将得到如下结果:

然后,我们计算每个值的平均输出,得到以下数据集:

然后,只需用线图绘制这些数据。
对于回归问题,计算每个特征值的平均输出是直接的。对于分类方法,我们可以使用每个类别的预测概率,然后对这些值进行平均。在这种情况下,我们的数据集中将有每个特征和类别对应的PDP。
数学解释
PDP的解释是,我们对一个或两个特征进行边际化,以评估它们对模型预测输出的边际效应。这由以下公式给出:

其中,$f$ 是机器学习模型,$x_S$ 是我们要分析的特征集合,$x_C$ 是我们要对其进行平均的其他特征集合。可以使用以下近似公式计算上述函数:
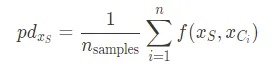
PDP 的问题
PDP 有一些限制需要注意。首先,由于我们对每个特征值的输出进行平均,即使该值只出现一次,我们也会得到一个涵盖数据集中每个值的图形。
因此,您可能会看到数据集中一些仅有少量数据的区域显示出的行为,并不代表如果该值更频繁出现时会发生的情况。因此,在查看特征的 PDP 时,始终查看该特征的分布,以了解哪些值更可能发生是有帮助的。
另一个问题是当某个特征的值相互抵消时。例如,如果您的特征具有以下分布:

计算该特征的 PDP 时,我们会得到如下结果:

请注意,该特征的影响绝对不是零,但平均值为零。这可能会让您误以为该特征是无用的,实际上并非如此。
这种方法的另一个问题是,我们要分析的特征与我们要进行平均的特征相关。这是因为如果我们有相关的特征,如果我们强制数据集的每个值都具有感兴趣特征的每个值,我们将创建出不现实的数据点。
想象一下一个包含降雨量和天空云量的数据集。当我们对降雨量的值进行平均时,我们会得到一些降雨量为零但天空中没有云的数据点,这是一个不可行的数据点。
解读 PDP
让我们看看如何分析部分依赖图。请看下面的图像:

在 x 轴上,我们有特征 0 的值,在 y 轴上,我们有模型对每个特征值的平均输出。请注意,在小于 -0.10 的值时,模型输出非常低的目标预测值,之后预测值上升,然后在约 150 左右变化,直到特征值超过 0.09,此时预测值开始急剧上升。
因此,我们可以说特征和目标预测之间存在正相关关系,但这种关系并非线性。
ICE 图
ICE 图试图解决特征值相互抵消的问题。基本上,在 ICE 图中,我们绘制模型对每个值所做的每个个体预测,而不仅仅是其平均值。
在 Python 中实现 PDP
让我们在 Python 中实现 PDP。首先,我们需要导入所需的库:
import numpy as npimport matplotlib.pyplot as pltfrom tqdm import tqdmfrom sklearn.datasets import load_diabetesfrom sklearn.ensemble import RandomForestRegressor我们将使用 sklearn 中的糖尿病数据集。我们将使用 tqdm 库为循环创建进度条。
现在,我们将加载数据集并训练一个随机森林回归器:
X, y = load_diabetes(return_X_y=True)rf = RandomForestRegressor().fit(X, y)现在,对于我们数据集中的每个特征,我们将计算模型在固定特定值的数据集上的平均预测值:
features = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]features_averages = {}for feature in tqdm(features): features_averages[feature] = ([], []) # 对于每个特征的每个唯一值 for feature_val in np.unique(X[:, feature]): features_averages[feature][0].append(feature_val) # 从数据集中删除该特征 aux_X = np.delete(X, feature, axis=1) # 将该特征值添加到数据集的每一行 aux_X = np.hstack((aux_X, np.array([feature_val for i in range(aux_X.shape[0])])[:, None])) # 计算平均预测值 features_averages[feature][1].append(np.mean(rf.predict(aux_X)))现在,我们绘制每个特征的PDP图:
for feature in features_averages: plt.figure(figsize=(5,5)) values = features_averages[feature][0] predictions = features_averages[feature][1] plt.plot(values, predictions) plt.xlabel(f'特征:{feature}') plt.ylabel('目标')例如,特征3的图表如下:

结论
现在,你有了另一个工具来改进你的工作,并帮助业务部门理解你展示给他们的黑盒模型发生了什么。
但是不要让理论消失。拿出你当前正在开发的模型,应用PDP可视化。了解模型的工作方式,并在假设中更加精确。
此外,这不是唯一的可解释性方法。实际上,我们还有其他适用于相关特征的方法。请关注我的下一篇文章,将介绍这些方法。
参考资料
https://ethen8181.github.io/machine-learning/model_selection/partial_dependence/partial_dependence.html
https://scikit-learn.org/stable/modules/partial_dependence.html
https://christophm.github.io/interpretable-ml-book/pdp.html





