SoundStorm:高效并行音频生成
由Google Research的研究软件工程师Zalán Borsos和高级研究科学家Marco Tagliasacchi发布
生成式人工智能的最新进展使得在多个不同领域中创建新内容成为可能,包括文本、视觉和音频。这些模型通常依赖于将原始数据首先转换为一系列令牌的压缩格式。在音频的情况下,神经音频编解码器(例如SoundStream或EnCodec)可以将波形有效地压缩为紧凑表示,该表示可以反转以重建原始音频信号的近似值。这种表示由离散音频令牌序列组成,捕捉声音的局部特性(例如音素)和它们的时间结构(例如韵律)。通过将音频表示为离散令牌序列,可以使用基于Transformer的序列到序列模型来执行音频生成 – 这已经在语音延续(例如使用AudioLM),文本转语音(例如使用SPEAR-TTS)和一般音频和音乐生成(例如AudioGen和MusicLM)方面取得了快速进展。许多生成音频模型,包括AudioLM,依赖于自回归解码,逐个生成令牌。虽然这种方法实现了高音质,但推理(即计算输出)可能很慢,特别是在解码长序列时。
为了解决这个问题,在“SoundStorm: Efficient Parallel Audio Generation”中,我们提出了一种高效且高质量的音频生成新方法。SoundStorm通过依赖于两个新颖元素来解决生成长音频令牌序列的问题:1)适应于由SoundStream神经编解码器产生的音频令牌的特定性质的架构,以及2)启发自MaskGIT的解码方案,这是一种针对音频令牌操作的方法。与AudioLM的自回归解码方法相比,SoundStorm能够并行生成令牌,因此对于长序列的推理时间减少了100倍,并且产生的音频在声音和声学条件上具有相同的质量和更高的一致性。此外,我们还展示了SoundStorm与SPEAR-TTS的文本到语义建模阶段相结合,可以综合高质量的自然对话,允许通过下面的例子控制口语内容(通过剧本)、扬声器语音(通过短语音提示)和扬声器转换(通过剧本注释):
| 输入:文本(以粗体显示的剧本用于驱动音频生成) | 今天早上发生了一件非常有趣的事情。|哦,哇!|嗯,我像往常一样醒来。|嗯嗯|下楼去吃早餐。|是啊|开始吃。然后10分钟后我意识到这是半夜。|哦不可能,太有趣了! | 昨晚我没睡好。|哦,不好。怎么了?|我不知道。我总感觉无法入睡,整晚都在翻来覆去。|太糟糕了。也许你应该早点睡觉或者读一本书。|是的,谢谢你的建议,我希望你是对的。|没问题。我希望你能睡个好觉。 | ||
| 输入:音频提示 | ||||
| 输出:音频提示+生成的音频 |
SoundStorm设计
在我们之前的AudioLM工作中,我们展示了音频生成可以分解为两个步骤:1)语义建模,从先前的语义令牌或一个调节信号(例如SPEAR-TTS中的剧本或MusicLM中的文本提示)生成语义令牌,以及2)声学建模,从语义令牌生成声学令牌。通过SoundStorm,我们专门解决了第二个声学建模步骤,用更快的并行解码替换了更慢的自回归解码。
SoundStorm依赖于双向注意力Conformer,这是一种模型架构,它将Transformer与卷积结合起来,以捕获序列令牌的局部和全局结构。具体而言,该模型被训练为在给定由AudioLM生成的语义令牌序列作为输入时,预测由SoundStream产生的音频令牌。在这样做时,重要的是要考虑到,每个时间步t,SoundStream使用最多Q个令牌来表示音频,使用一种称为残差向量量化(RVQ)的方法,如下图所示。关键的直觉是随着每个步骤生成的令牌数从1增加到Q,重建音频的质量逐步提高。
在推断时间中,给定语义令牌作为输入条件信号,SoundStorm以所有音频令牌被屏蔽的状态开始,并在多次迭代中填充屏蔽的令牌,从RVQ级别q = 1的粗略令牌开始,逐级使用更细的令牌进行处理,直到达到级别q = Q。
SoundStorm的两个关键方面使快速生成成为可能:1)在RVQ级别内,可以在单次迭代中并行预测令牌,2)模型架构的设计使得复杂性受到的影响仅较轻微,而不会因级别数Q的增加而导致复杂度大幅增加。为了支持这种推理方案,在训练期间使用了一个精心设计的屏蔽方案,以模仿推理中使用的迭代过程。
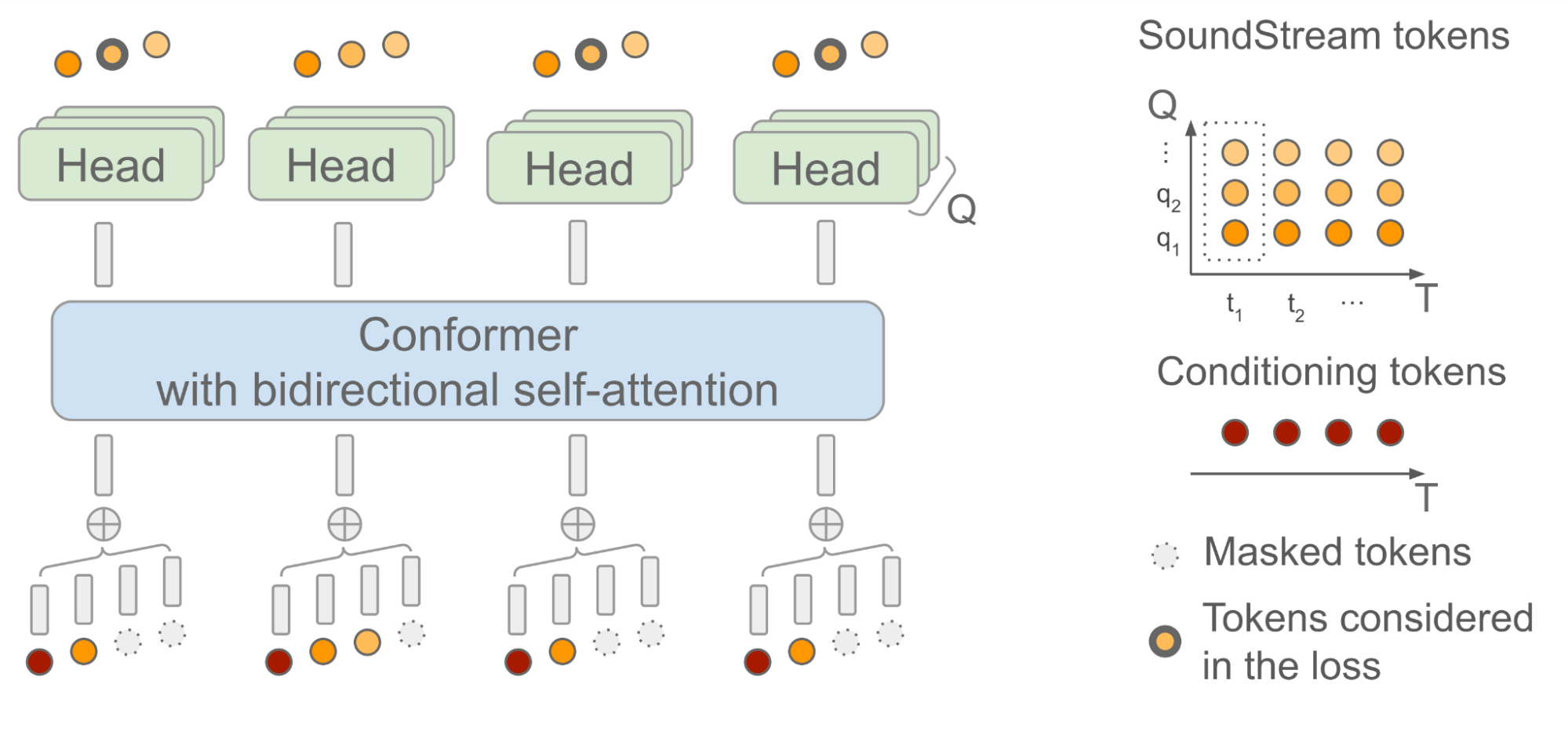 |
| SoundStorm模型架构。T表示时间步数,Q表示SoundStream使用的RVQ级别数。作为调节信号使用的语义令牌与SoundStream帧进行时间对齐。 |
测量SoundStorm性能
我们证明了SoundStorm与AudioLM的声学生成器的质量相匹配,替换了AudioLM的第二阶段(粗略声学模型)和第三阶段(细粒度声学模型)。此外,SoundStorm产生的音频比AudioLM的分层自回归声学生成器快100倍,质量相匹配,并在说话者身份和声学条件方面具有更好的一致性(下图的上半部分)。
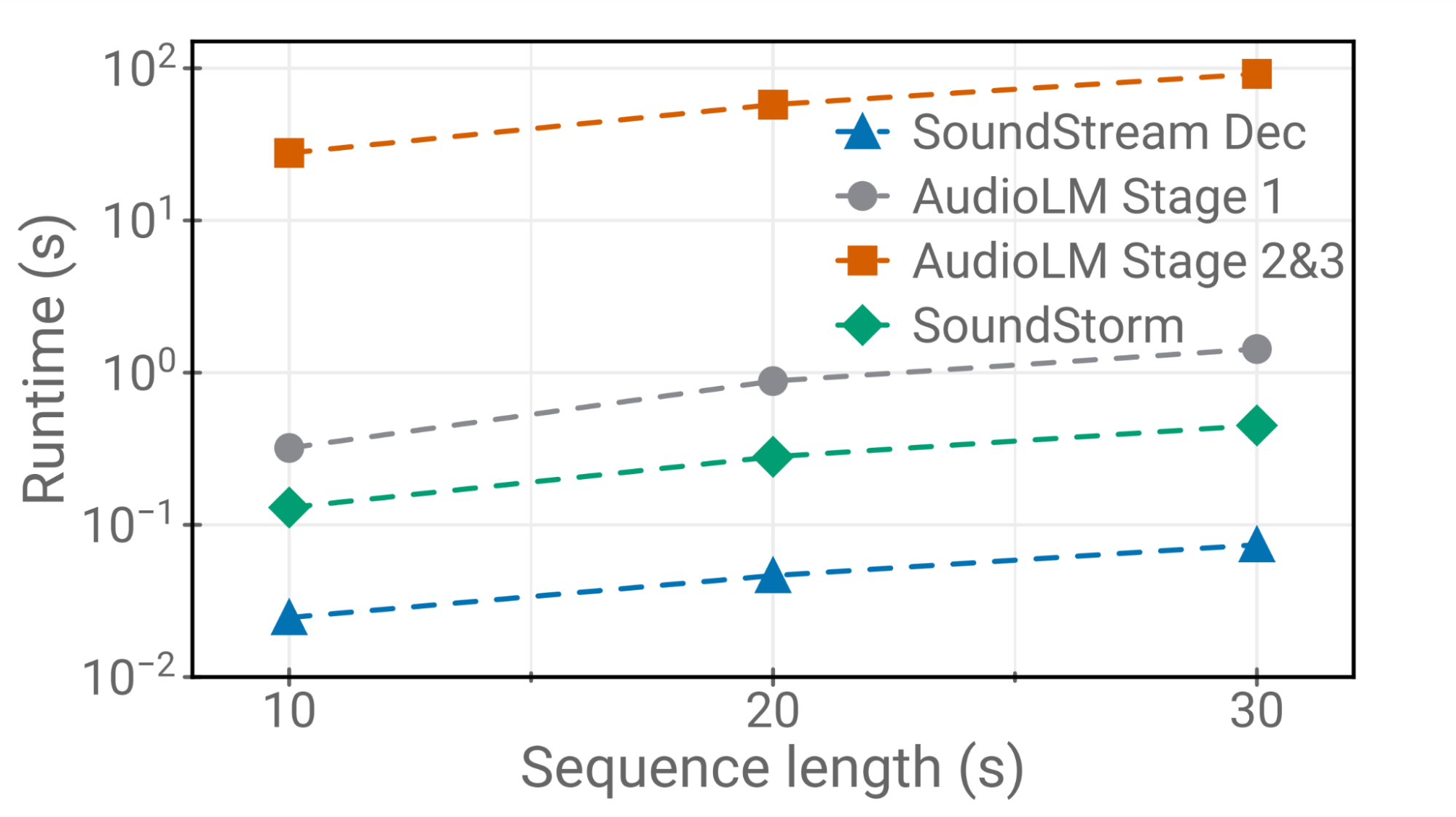 |
| SoundStream解码、SoundStorm和AudioLM不同阶段在TPU-v4上的运行时间。 |
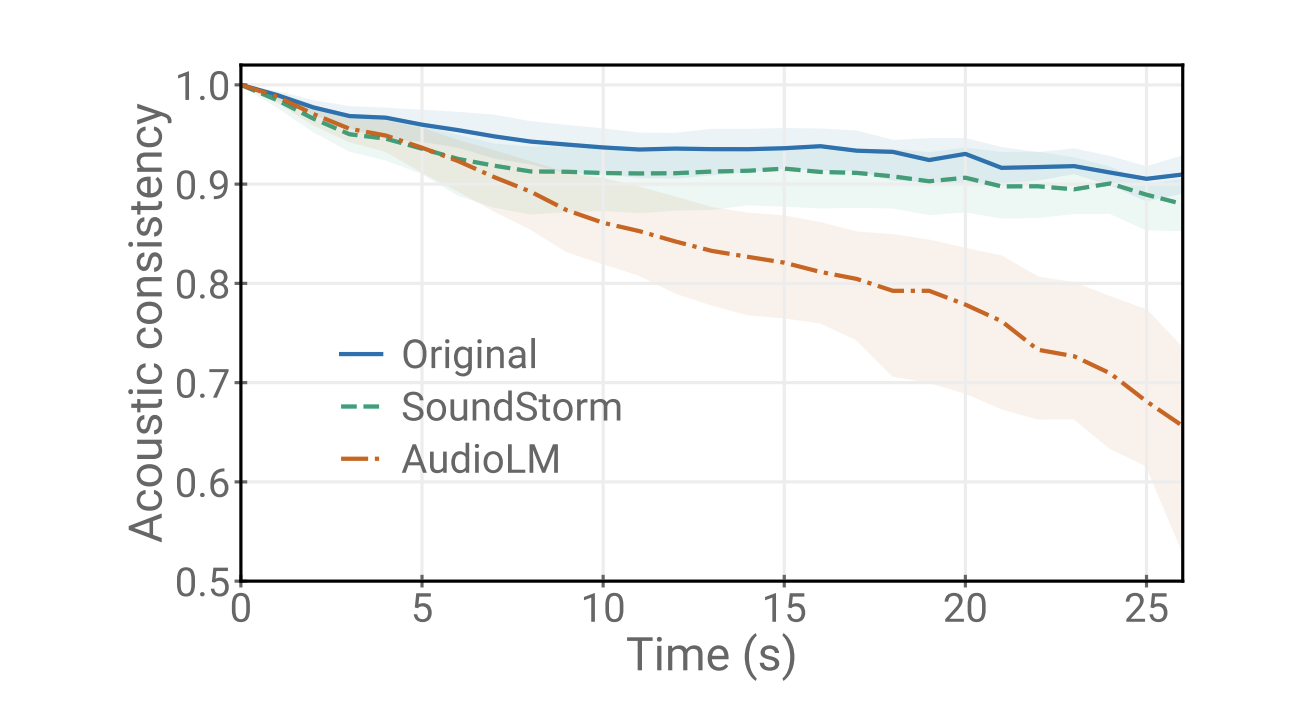 |
| 提示语音和生成音频之间的声学一致性。阴影区域表示四分位距。 |
安全和风险缓解
我们认识到,模型产生的音频样本可能会受到训练数据中存在的不公平偏见的影响,例如在代表口音和声音特征方面。在我们生成的样本中,我们展示了我们可以通过提示可靠且负责任地控制说话者特征,以避免不公平的偏见。对任何训练数据及其限制的彻底分析是未来工作的领域,符合我们的负责任AI原则。
反过来,模仿声音的能力可能有许多恶意应用,包括绕过生物识别并使用模型进行冒充。因此,必须采取防范潜在滥用的措施:为此,我们已经验证了由SoundStorm生成的音频可以通过使用与我们原始AudioLM论文中描述的相同分类器的专用分类器进行检测。因此,作为更大系统的组成部分,我们相信SoundStorm不太可能引入额外的风险,与我们早期关于AudioLM和SPEAR-TTS的论文讨论的风险相比。同时,放松AudioLM的内存和计算要求将使音频生成领域的研究更容易被更广泛的社区接受。在未来,我们计划探索其他检测合成语音的方法,例如使用音频水印技术,以便该技术的任何潜在产品使用严格遵循我们的负责任AI原则。
结论
我们介绍了SoundStorm,一种可以从离散的条件标记有效地合成高质量音频的模型。与AudioLM的声学发生器相比,SoundStorm快两个数量级,并在生成长音频样本时实现更高的时间一致性。通过将类似于SPEAR-TTS的文本到语义标记模型与SoundStorm相结合,我们可以将文本到语音合成扩展到更长的上下文,并生成具有多个说话者转换的自然对话,控制说话者的声音和生成的内容。SoundStorm不仅限于生成语音。例如,MusicLM使用SoundStorm有效地合成更长的输出(如在I/O中看到)。
致谢
这里描述的工作由Zalán Borsos、Matt Sharifi、Damien Vincent、Eugene Kharitonov、Neil Zeghidour和Marco Tagliasacchi撰写。我们感谢Google的同事们对这项工作进行的所有讨论和反馈。






