使用Streamlit进行简单调查
Streamlit的用户界面组件使构建简单调查变得容易
- 您认为人工智能的未来如何,是否应该加以监管,是否会创造新的工作或会破坏它们?
- 您认为气候变化会如何影响您的生活方式?
- 您相信宇宙中存在外星生命吗?
- 您喜欢哪种数据科学编程语言?
有时我们使用其他人的数据创建故事,而有时我们需要创建自己的数据,因此我们必须收集它。这可能是一个调查或实验结果的日志,但我们需要提出问题并记录结果数据。
当然,有些服务可以为您完成这项工作(有时需要付费,但通常也有免费选项)。或者,您可以坚持使用经过验证的剪贴板和铅笔方法。
但是,如果您是Streamlit的用户,则创建简单的调查非常容易。
存储数据
然而,有一个小问题。Streamlit的用户界面组件非常好用,易于使用,但没有内置的数据存储方法。您可以简单地将数据存储在文本文件或SQLite数据库中,这样做可以很好地工作,但仅适用于本地应用。
如果您试图在Streamlit Cloud中部署该应用程序,您会发现您创建的任何数据都会消失。
当您考虑这一点时,这是显而易见的。
当您启动Streamlit Cloud应用程序时,它会从Github复制源文件,包括任何数据文件或数据库,但当您离开应用程序时,没有任何内容被写回。因此,当您再次启动应用程序时,您从头开始。您收集和存储的任何数据仅在应用程序运行时持续存在。当您离开应用程序时,该数据会丢失。
这不是一个调查应用程序的好行为。
当然,Streamlit的人员已经想到了这一点,并在他们的文档中提供了解决方案(请参阅“知识库”中的教程部分)。其中大多数涉及连接到运行各种数据库(如MySQL、Microsoft SQL Server等)的数据库服务器,但也展示了如何使用Streamlit与基于云的服务,如Amazon S3、MongoDB和Google Cloud Storage。
还有Databutton,这是一个全面的Streamlit在线开发环境,具有一键部署、AI支持编码和方便的数据存储作为开发和部署环境的一部分,等等。
现在,我们将集中在调查部分,并单独处理存储。在这个应用程序中,我们将只使用本地文件来存储数据,但为了使我们未来的生活更容易,我们将把所有文件操作放在一个库中。这样,如果我们想要移植到另一个平台,我们只需要重新编写该库。因此,请记住,我们的初始应用程序不是设计用于部署,而是在本地机器上工作。
在Streamlit中创建调查
Streamlit提供了一系列良好的用户界面组件,可用于创建、展示和分析调查数据。特别是,我们将利用一组单选按钮来实现多项选择题,并利用可编辑数据框来显示和编辑问卷本身。

我们可以考虑更复杂的演示或不同的问题类型-但目前我们将保持简单。
应用程序有三个组成部分:问卷编辑器、调查展示和结果分析器/可视化程序。我将它们实现为一个多页面应用程序的页面。(所有这意味着它们位于名为pages的文件夹中。)
编辑器
我们将主要使用Python字典来表示我们的数据——问卷和结果——在这个本地应用程序版本中,我们将其存储为JSON文件。
问题将存储在两个字段中:text,一个包含问题文本的字符串,和responses,一个由逗号分隔的多选答案字符串。
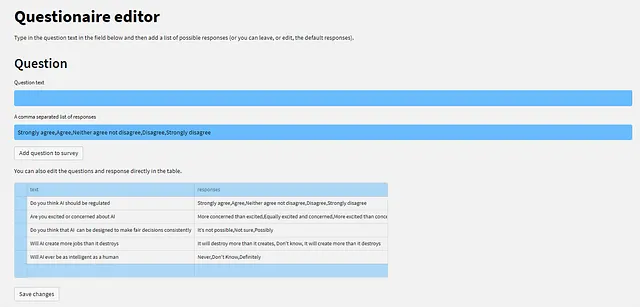
您可以在下面的屏幕截图中看到问题数据显示为Streamlit的data_editor组件。使用此组件,您可以直接编辑问卷,如果您愿意的话。
在可编辑的数据框上方有几个字段:第一个是问题,第二个是可能的答案列表。填写这些信息并点击“Add question to survey”按钮,您将在数据框中看到新问题。
正如我所说,您也可以直接编辑数据框:点击适当的字段以更改现有数据;点击行左侧选择它并使用删除键将其删除;或者点击左下角的最后一行以添加新行。
无论哪种情况,您都需要点击“Save changes”以存储数据。
您可以在下面看到实现方法。
每次用户交互时,Streamlit程序都会重新运行,因此我们使用Streamlit会话功能来存储问卷,以便其值得到正确维护。除此之外,它是一个相当直接的Streamlit程序;它显示了两个st.text_input()组件(将默认响应字符串添加到第二个组件中),然后是一个st.data_editor(),既显示了问卷,又允许对其进行修改。
程序的最后一部分是数据存储的地方。这使用了我在DButils库中编写的例程。这些本质上是基本文件存储函数的包装器——就像我之前说过的那样,我已经实现了这样的存储,以便这些程序可以在不同平台上使用替代存储选项。
DButils.get_survey()检索存储的问卷,DButils.save_survey()将整个数据框保存到文件。
import streamlit as stimport DButilsst.set_page_config(layout="wide")if 'survey' not in st.session_state: st.session_state['survey'] = DButils.get_survey()st.title("问卷编辑器")st.write("""在下面的字段中输入问题文本,然后添加可能的回答列表(您也可以保留或编辑默认的回答)。""")# 设置默认响应default_response = ( "强烈同意,同意,不同意也不反对,不同意,强烈不同意")st.header("问题")q_text = st.text_input("问题文本")q_responses = st.text_input( "逗号分隔的回答列表", value=default_response)submitted = st.button("添加问题到问卷")if submitted: st.session_state['survey'].append( { "text": q_text, "responses": q_responses, } )st.write("您也可以直接在表格中编辑问题和回答。")edited_df = st.data_editor(st.session_state['survey'], num_rows="dynamic")save = st.button("保存更改")if save: DButils.save_survey(edited_df) st.success(f"更改已保存")展示问卷
每个问题都作为一组单选按钮呈现。
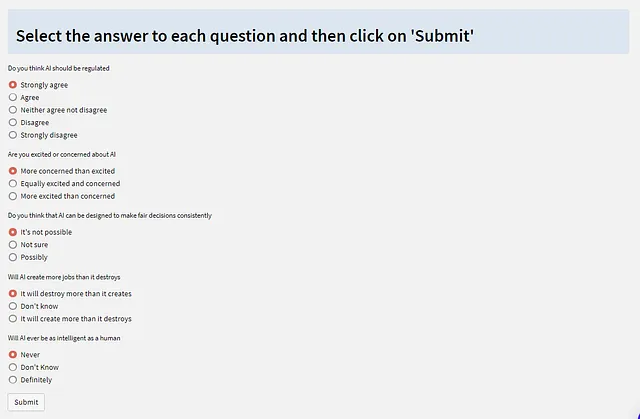
如下所示,我们遍历问卷,提取提示的text字段,并将responses字段拆分为其单独的答案,以显示按钮组。
import pandas as pdimport streamlit as stimport DButilsst.info("## 选择每个问题的答案,然后点击“提交”")questions = DButils.get_survey()responses = {}for q in questions: response = st.radio(label=q['text'], options=q['responses'].split(",")) responses[q['text']] = response.strip()if st.button("提交"): entry = responses DButils.append_results(entry) st.write("已更新")将完整记录的数据添加到存储的响应中,使用 DButils.update()。
呈现结果
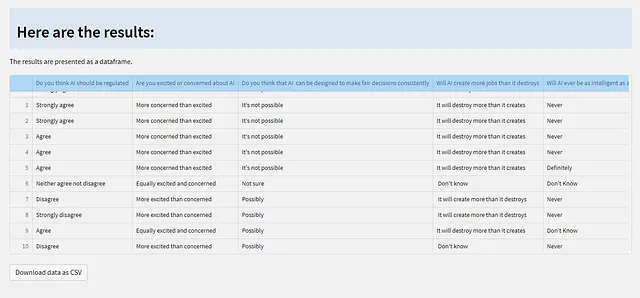
结果页面分为三个部分:第一部分显示结果作为可下载为 CSV 文件的数据表格。
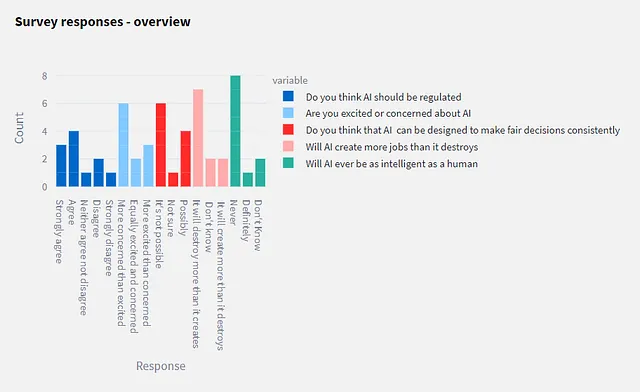
第二部分是完整调查的图形概述。条形图是使用 Plotly Express 创建的。
最后一部分允许用户选择每个问题的结果,这些结果显示为条形图(也是 Plotly)。
以下是此代码。我们使用 DButils.get_results() 加载结果数据框,然后将其显示为 st.dataframe()(当然,这次不可编辑!),并添加一个下载按钮,该按钮将数据保存在您的本地计算机上作为 CSV 文件。
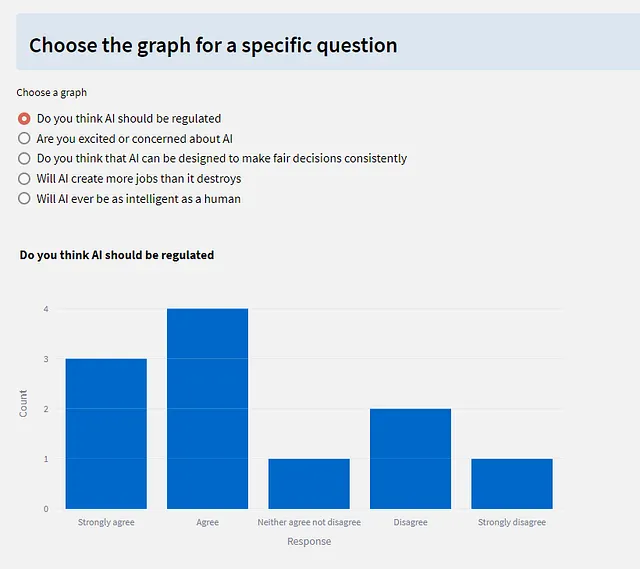
接下来是整个响应数据的条形图(每个问题的颜色不同)。由于这不一定是最容易阅读的内容,因此接下来是一个单选按钮组,可让您选择要重点关注的特定问题。每个问题的条形图都是事先在循环中绘制的,并显示为所选单选按钮的适当图表。
import streamlit as stimport plotly.express as pximport pandas as pdimport DButilsst.set_page_config(layout="wide")st.info("## Here are the results:")st.write("The results are presented as a dataframe.")# 从数据存储中读取数据results = DButils.get_results()st.dataframe(results, use_container_width=True)df = pd.DataFrame(results)st.download_button( label="Download data as CSV", data=df.to_csv().encode("utf-8"), file_name="survey_results.csv", mime="text/csv",)# 生成一个摘要条形图fig = px.bar(results, title="Survey responses - overview")fig.update_xaxes(title_text="Response")fig.update_yaxes(title_text="Count")st.plotly_chart(fig)# 创建一个条形图图像数组,每个问题一个图像figures = []for q in df.columns: fig = px.bar(df[q], title=q) fig.update_layout(showlegend=False) fig.update_xaxes(title_text="Response") fig.update_yaxes(title_text="Count") figures.append(fig)# 选择要显示的图形与一组单选按钮st.info("### Choose the graph for a specific question")f = st.radio("Choose a graph", options=df.columns)column_index = df.columns.get_loc(f)st.plotly_chart(figures[column_index])The DButils 库
如下所示,DButils 库具有多个用于读取、写入和更新 CSV 文件的函数。它还为我们上面使用的两个文件定义了常量。
该库专门为使用 JSON 文件存储数据的本地应用程序编写,但如果您想将其移植到另一个平台,则只需重新编写四个简单的函数并定义两个常量即可。
import osimport jsonSURVEY_KEY = "survey.json"RESULTS_KEY = "results.json"# 保存数据def save_dict(value, key=SURVEY_KEY): print(f"Saving: {value}") #return None out_file = open(key, "w") json.dump(value,out_file) out_file.close()def save_results(value): save_dict(value,RESULTS_KEY)def save_survey(value): save_dict(value, SURVEY_KEY)# 检索数据def retrieve(key): # 文件存在则读取并返回字典数组 if os.path.isfile(key): in_file = open(key, "r") result = json.load(in_file) in_file.close() return result else: # 文件不存在,则返回空字典数组 return []def get_survey(key=SURVEY_KEY): return retrieve(key)def get_results(key=RESULTS_KEY): return retrieve(key)# 更新结果# 这可能不是高效的,但简单def append_results(value): results = get_results() results.append(value) save_results(results)在真实世界中
我希望你会同意,这些简单的例程创建了一个相当有吸引力的应用程序,并向你展示了如何使用Streamlit创建简单的调查问卷。
但如果你想在真实世界中部署这样的应用程序,你需要考虑一些事情。
以下是你可能需要考虑的一些事情:
- 即使调查是匿名的,你可能希望能够识别出受访者,以避免重复输入。
- 你可能希望包括不同的问题类型或以不同的方式展示它们(例如
st.select_slider())。 - 随机呈现响应的方式有时可以避免引导受访者做出特定的答案。
- 你几乎肯定会想在调查中添加人口统计学问题。这些也可以实现为多项选择题,但在进行分析时需要将结果与其他结果区别对待。
但这不是一篇有关如何设计调查的教程,所以我就到这里了。
感谢阅读,希望你觉得这是一份有用的指南,告诉你如何在Streamlit中设计调查。这个应用程序故意非常简单,数据存储只在本地部署应用程序时有效。我希望在以后的文章中解决这些问题。
如果你想看更多我的作品,请查看我的网页。






