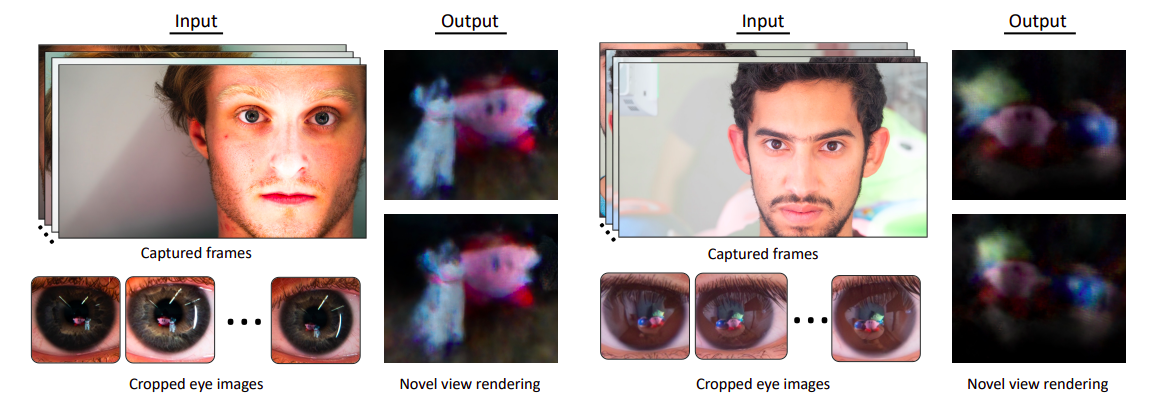
来自马里兰大学学院市分校的最新人工智能研究开发出了一种人工智能系统,可以从人眼中的反射中重建三维场景


人眼是一种奇妙的器官,允许视觉并存储重要的环境数据。它们通常将它们的眼睛用作两个镜头,以将光线引导到组成视网膜的感光细胞上。但是,如果他们看着别人的眼睛,他们也可以看到从角膜反射的光线。当他们使用照相机拍摄别人的眼睛时,他们会将他们的眼睛转化为成像系统中的一对镜子。由于到达观察者视网膜的光线和从他们的眼睛反射出来的光线来自同一源,因此他们的相机应该提供包含有关他们正在查看的环境的细节的图片。
在早期的实验中,人们恢复了两只眼睛的图像,这些图像恢复了观察者所看到的世界的全景。随后的研究包括重新照明、聚焦物体估计、检测握持位置和个人识别等应用。随着3D视觉和图形领域的最新发展,人们思考是否能够恢复观察者的现实,而不仅仅是重建单个全景环境地图或在光模式中发现模式。这项工作通过从一系列眼睛图片创建3D场景来解决这些问题。他们从头部自然移动时,他们的眼睛捕捉并反射来自多个视图的信息开始。
马里兰大学的研究人员提供了一种全新的技术,用于从眼部扫描中创建观察者环境的3D重建,将过去的开创性工作与最新的神经渲染发展融合在一起。他们的方法使用静止相机并从眼睛图片中提取多视图线索。与通常的NeRF捕获设置不同,在头部移动时,需要移动相机来获取多视图信息(通常紧随其后的是相机位置估计)。尽管在概念上简单,但实际上从眼睛图片中重建3D NeRF很困难。初始困难是来源分离。他们必须区分人眼反射和复杂的虹膜纹理。
由于这些复杂的模式,3D重建过程变得更加模糊。他们收集的视觉图像与虹膜纹理固有地混合在一起,而不是正常捕获中通常假定的场景的干净照片。这种组合使重建技术更加困难,从而使像素相关性失调。估计角膜姿势是第二个困难。眼睛小而难以从图像观察中精确定位。但是,它们的位置和3D方向的精度对于多视图重建至关重要。
为了克服这些困难,本研究的作者重新利用NeRF对眼睛图像进行训练,添加了两个必要元素:a)纹理分解,它利用短径向使虹膜纹理与整体辐射场易于区分,和b)眼睛位置细化,它提高了姿势估计的精度,尽管眼睛的小尺寸带来了一定的困难。他们创建了一个复杂的室内环境的合成数据集,其中包含从具有真实纹理的人工角膜反射的照片,以评估他们的技术的性能和有效性。他们还使用多个物品的真实世界设置拍摄眼睛的照片。他们对人工和实际收集的眼图像进行了大量研究,以支持他们方法中的几个设计决策。
这些是他们的主要贡献:
•他们提供了一种全新的技术,用于从眼部扫描中创建观察者环境的3D重建,将过去的开创性工作与最新的神经渲染发展融合在一起。
•他们通过引入径向先验来分解眼睛图片中的虹膜纹理,显着提高了重建辐射场的质量。
•他们通过开发角膜姿势细化过程来解决从人眼中收集特征的特殊问题,该过程减少了眼球嘈杂的姿势估计。
这些发展扩展了通过神经渲染进行3D场景重建的范围,以处理从眼睛反射中获得的部分受损图像观察。这为研究和开发意外成像领域中的新机会,以显示和捕获可见视线之外的3D场景。他们的网站上有几个展示他们进展的视频。