UC Berkeley和Meta AI研究人员提出了一种拉格朗日动作识别模型,通过融合3D姿态和上下文化外观来跟踪轨迹


在流体力学中,惯性系和欧拉系的流场表示是惯例。根据维基百科,“流场的拉格朗日描述是一种研究流体运动的方法,其中观察者跟随离散的流体粒子,在时空中流动。流体包裹物的路径线可以通过随时间记录其位置来确定。这可以被描绘为在船上漂浮时沿着河流漂流。流场的欧拉描述是一种分析流体运动的方法,其特别强调流体通过时间演化的空间位置。坐在河岸上,观察水流经过固定点会帮助您理解这一点。
这些思想对于理解如何检查人类行动记录至关重要。根据欧拉视角,他们会集中在某些位置(例如(x,y)或(x,y,z))处的特征向量,并考虑历史演变,同时在空间中保持不动。根据拉格朗日视角,他们会跟随某个人在时空中的相关特征向量。例如,早期针对活动识别的研究经常采用拉格朗日视角。然而,随着基于3D时空卷积的神经网络(如SlowFast Networks)的发展,欧拉视角已成为最前沿的方法的常态。即使在转换成transformer系统后,欧拉视角仍然被保持。
这很重要,因为它为我们提供了重新审视“在视频分析中,单词应该有什么对应物?”这个问题的机会。Dosovitskiy等人推荐图像补丁是一个不错的选择,将该概念扩展到视频意味着时空立方体可能也适合于视频。相反,他们采用拉格朗日视角来研究人类行为。这使得他们清楚地考虑到实体的时间跨度。在这种情况下,实体可能是高级别的,如人类,或低级别的,如像素或补丁。他们选择在“人类作为实体”的水平上工作,因为他们有兴趣理解人类行为。
为了做到这一点,他们使用一种技术,分析视频中的人物动作,并利用它来识别他们的活动。他们可以使用最近发布的3D跟踪技术PHALP和HMR 2.0来检索这些轨迹。图1说明了PHALP如何通过将个体提升到3D来从视频中恢复人员轨迹,从而使它们能够将人员连接到多个帧并访问其3D表示。他们使用这些人的3D表示——它们的3D姿态和位置——作为每个令牌的基本元素。这使我们能够构建一个灵活的系统,其中模型(在这种情况下是transformer)可以接受属于不同个体的令牌,并访问它们的身份、3D姿势和3D位置作为输入。通过使用场景中人物的3D位置,我们可以了解人际互动。
他们基于令牌化的模型超越了先前仅具有姿态数据访问权的基线,并且可以使用3D跟踪。尽管一个人的位置演化是一个强有力的信号,但某些活动需要有关周围环境和人的外观的其他背景知识。因此,将姿势与从像素直接派生的有关人和场景外观的数据结合起来非常重要。为此,他们还使用了最先进的行动识别模型,以拉格朗日框架为基础提供基于情境的外观的补充数据。他们通过强烈运行这些模型来记录每条轨迹的路径周围的情境化外观属性。
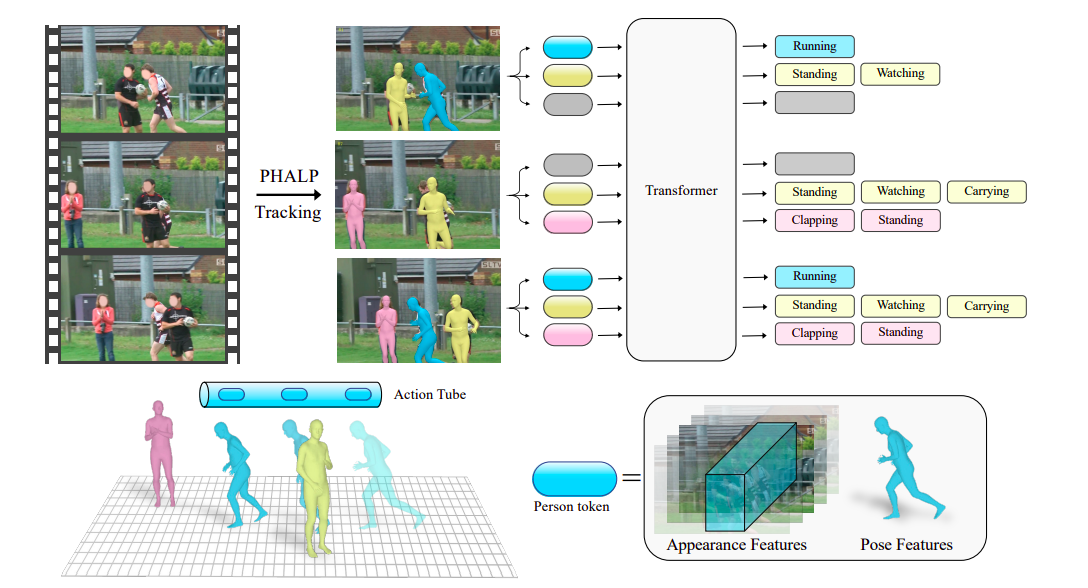
他们的标记由行动识别骨干处理,包含个体的三维立场明确信息和来自像素的高采样外观数据。在困难的AVA v2.2数据集上,他们的整个系统显著超过先前的艺术水平2.8 mAP。总体而言,他们的主要贡献是引入了一种方法论,强调了跟踪和三维姿态对于理解人类运动的好处。UC伯克利和Meta AI的研究人员提出了一种使用人的轨迹来预测他们的行动的Lagrangian Action Recognition with Tracking(LART)方法。他们的基线版本表现优于先前使用无轨迹轨迹和视频中人物的三维姿态表示的基线。此外,他们还表明,仅考虑视频中的外观和上下文的标准基线可以轻松地与建议的Lagrangian行动检测视角集成,从而在主导范式上取得显着的改进。






