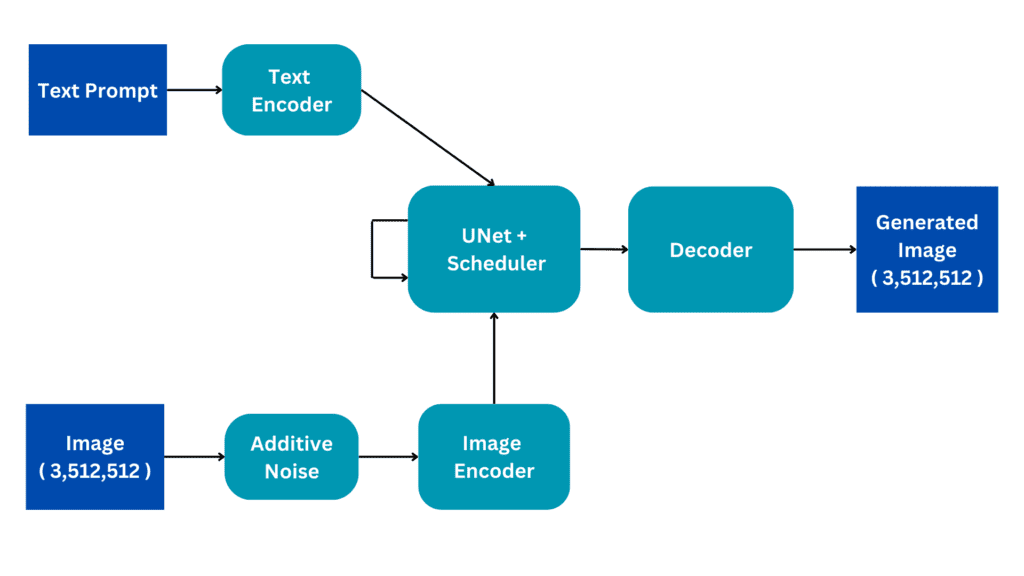
认识LOMO(LOw-Memory Optimization):一种新的AI优化器,它将梯度计算和参数更新融合为一步,以减少内存使用


大规模语言模型通过展示出色的技能,如自发性和理解力,并不断增加模型的大小,改变了自然语言处理。通过使用数十亿个参数来训练这些模型,提高了NLP研究的门槛,例如具有30B到175B个参数的模型。对于小型实验室和企业来说,参与这个研究领域是具有挑战性的,因为调整大规模语言模型经常需要昂贵的GPU资源,如880GB的机器。最近,通过诸如LoRA和Prefix-tuning等参数高效微调技术,实现了资源受限的大规模语言模型微调。
尽管完全参数微调被认为是比参数高效微调更有效的策略,但两种技术都必须提供可行的解决方案。他们希望在资源受限的情况下研究完成全面参数微调的方法。他们在LLM中研究了激活、优化器状态、梯度张量和参数这四个内存利用的特征,并通过三种方式优化训练过程:1)重新评估优化器的算法功能,发现SGD是LLM完全参数微调的合适替代品。由于SGD不维护中间阶段,可以删除优化器状态的整个部分。2)他们提出的优化器LOMO,如图1所示,将梯度张量的内存使用减少到O,即最大梯度张量的内存消耗。3)他们在训练过程中结合了梯度归一化和损失缩放,并将某些计算切换到全精度,以稳定使用LOMO进行混合精度训练。他们的方法将与参数、激活和最大梯度张量相同数量的内存结合起来。
他们严重增加了完全参数微调的内存消耗,将其降低到推理的水平。这是因为仅前向过程不应比后向过程需要更少的内存。值得注意的是,他们确保在使用LOMO节省内存时,微调功能不受影响,因为参数更新过程与SGD类似。复旦大学的研究人员通过实证评估LOMO的内存和吞吐能力,展示了如何使用LOMO成功训练一个只使用8台RTX 3090 GPU的65B模型。此外,他们使用LOMO调整了SuperGLUE数据集合上的LLMs的全部参数,以验证他们建议的方法在下游任务的性能上的表现。实证结果显示LOMO在优化具有许多参数的LLMs时的良好表现。

以下是他们的总体贡献:
• 他们提供了一项理论研究,表明SGD可以成功调整所有LLMs的参数。在优化LLMs时,曾经阻碍SGD被广泛使用的障碍可能不会那么严重。
• 他们提出了LOMO或低内存优化,大幅减少GPU内存使用量,同时保持微调过程。
• 他们通过仔细分析内存利用和吞吐性能,实证证明了LOMO在资源受限环境中优化LLMs的效率。下游任务的性能评估为此提供了额外的验证。
代码实现可在GitHub上找到。