使用PyTorch 2.0在AWS上构建高性能ML模型 – 第1部分
PyTorch 是一种机器学习(ML)框架,被 AWS 的客户广泛用于各种应用,如计算机视觉、自然语言处理、内容创作等。最近发布的 PyTorch 2.0 版本使 AWS 客户可以使用与 PyTorch 1.x 相同的功能,但速度更快、规模更大,具有更快的训练速度、更低的内存使用率和增强的分布式能力。PyTorch2.0 发布包括了几种新技术,包括 torch.compile、TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor。详细信息请参见《PyTorch 2.0: Our next generation release that is faster, more Pythonic and Dynamic as ever》。
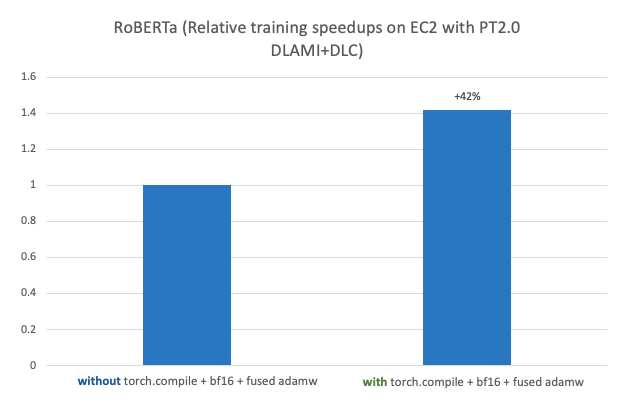
本文演示了在 AWS 上使用 PyTorch 2.0 进行大规模、高性能的分布式 ML 模型训练和部署的性能和易用性。本文进一步演示了使用 AWS Deep Learning AMI(AWS DLAMI)和 AWS Deep Learning Containers(DLCs)在 Amazon Elastic Compute Cloud(Amazon EC2 p4d.24xlarge)上对 RoBERTa(Robustly Optimized BERT Pretraining Approach)模型进行微调以进行情感分析的逐步实现,使用 PyTorch 2.0 torch.compile + bf16 + fused AdamW 时,观察到了 42% 的加速。然后,将微调的模型部署在 AWS Graviton 上基于 C7g EC2 实例的 Amazon SageMaker 上,与 PyTorch 1.13 相比观察到了 10% 的加速。
以下图显示了在 Amazon EC2 p4d.24xlarge 上使用 AWS PyTorch 2.0 DLAMI + DLC 对 RoBERTa 模型进行微调的性能基准测试。
有关 AWS Graviton 处理器上 PyTorch 2.0 的优化推理详细信息,请参见《Optimized PyTorch 2.0 inference with AWS Graviton processors》。
AWS 上的 PyTorch 2.0 支持
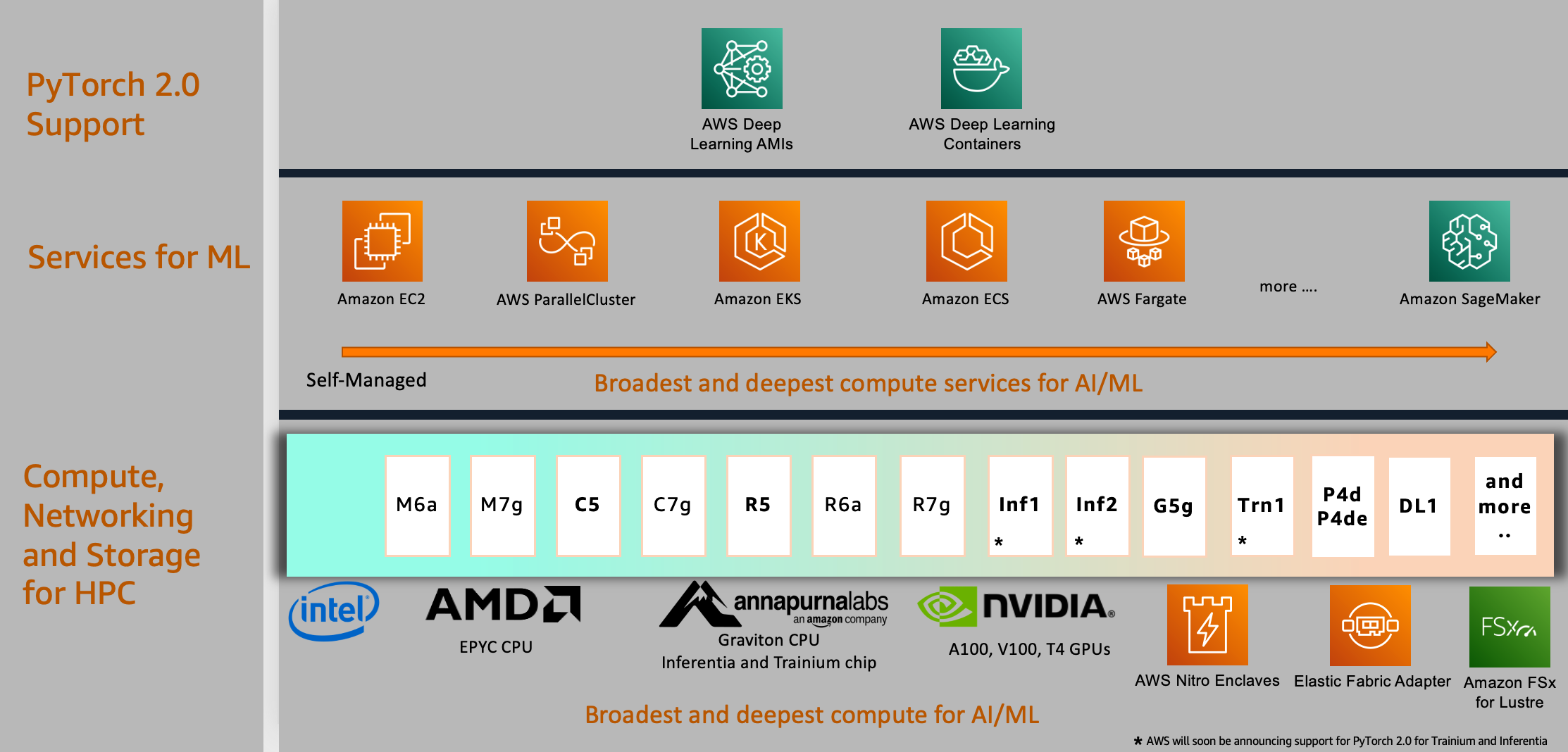
PyTorch 2.0 支持不仅限于本文示例用例中显示的服务和计算,还扩展到 AWS 上的许多其他服务,我们在本节中进行讨论。
业务需求
许多 AWS 客户,跨越各种行业,正在通过使用人工智能(AI)转变其业务,特别是在生成式 AI 和大型语言模型(LLM)方面,这些模型旨在生成类似于人类的文本。这基本上是基于深度学习技术的大型模型,使用数百亿个参数进行训练。模型大小的增长使训练时间从几天增加到几周,甚至在某些情况下为数月。这导致训练和推理成本呈指数增长,这就需要像 PyTorch 2.0 这样的框架,具有内置的加速模型训练支持和 AWS 优化的基础设施,以满足特定工作负载和性能需求。
计算选择
AWS 在强大的计算、高速网络和可扩展的高性能存储选项上提供 PyTorch 2.0 支持,可以用于任何 ML 项目或应用,并进行自定义以适应您的性能和预算要求。这在下一节的图表中得到体现;在底层层次,我们提供了由 AWS Graviton、Nvidia、AMD 和 Intel 处理器驱动的广泛选择的计算实例。
对于模型部署,您可以使用基于 ARM 的处理器,例如最近宣布推出的 AWS Graviton 基础实例,该实例提供了针对 PyTorch 2.0 的推理性能,对于 Resnet50,比之前的 PyTorch 版本提供了高达 3.5 倍的速度,对于 BERT,提供了高达 1.4 倍的速度,使 AWS Graviton 基础实例成为 AWS 上用于 CPU 模型推理解决方案的最快计算优化实例。
ML 服务选择
要使用 AWS 计算,您可以从广泛的全球云端服务中选择 ML 开发、计算和工作流编排。这种选择允许您与业务和云策略保持一致,并在您选择的平台上运行 PyTorch 2.0 作业。例如,如果您有本地限制或现有的开源产品投资,您可以使用 Amazon EC2、AWS ParallelCluster 或 AWS UltraCluster 运行基于自我管理的分布式训练工作负载。您还可以使用 SageMaker 作为成本优化、完全托管且可生产规模的培训基础结构的完全托管服务。SageMaker 还与各种 MLOps 工具集成,这使您可以扩展模型部署、降低推理成本、更有效地管理生产中的模型并减轻运营负担。
同样地,如果您已经投资于Kubernetes,您也可以在AWS上使用Amazon Elastic Kubernetes Service(Amazon EKS)和Kubeflow来实现分布式训练的ML流程,或者使用像Amazon Elastic Container Service(Amazon ECS)这样的AWS本地容器编排服务来进行模型训练和部署。构建ML平台的选项不仅限于这些服务,您可以根据您的组织要求为PyTorch 2.0作业选择不同的服务。
使用AWS DLAMI和AWS DLC启用PyTorch 2.0
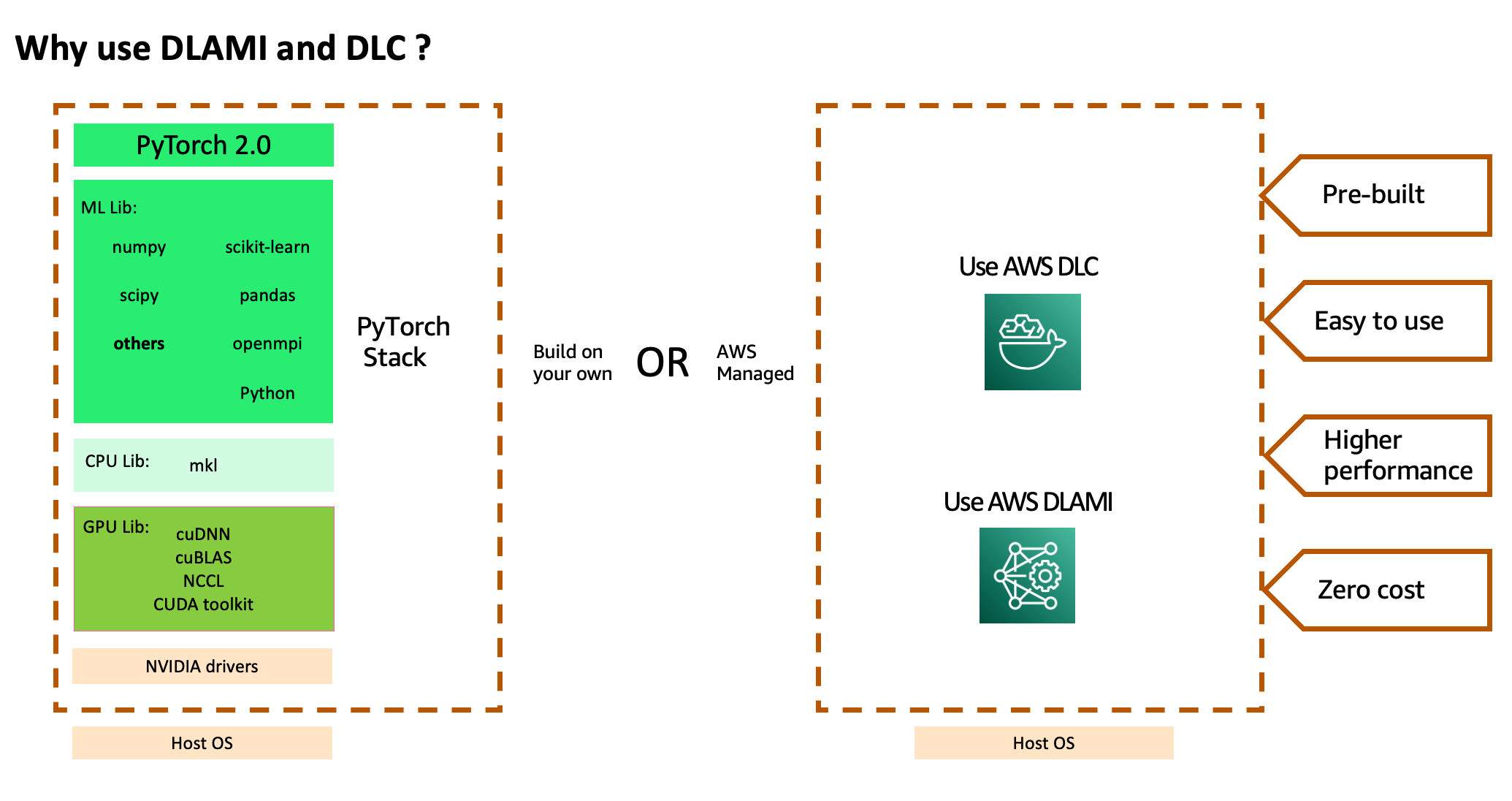
要使用上述AWS服务堆栈和强大的计算能力,您必须安装优化的PyTorch 2.0框架和其所需的依赖项,其中许多是独立项目,并进行端到端的测试。您可能还需要针对加速数学例程的CPU特定库,针对加速数学和GPU间通信例程的GPU特定库,以及需要与编译GPU库使用的GPU编译器对齐的GPU驱动程序。如果您的作业需要大规模多节点培训,则需要一个优化的网络,可以提供最低延迟和最高吞吐量。构建堆栈后,您需要定期扫描和修补它们的安全漏洞,并在每个框架版本升级后重新构建和重新测试堆栈。
AWS通过提供经过筛选和安全的一组框架,依赖项和工具来帮助减轻这一重负,以加速在云中进行深度学习,其中包括 AWS DLAMI 和 AWS DLC。这些预构建和测试的机器镜像和容器针对 EC2 加速计算实例类型进行了优化,可让您更高效地扩展到多个节点以进行分布式工作负载。它包括一个预构建的 Elastic Fabric Adapter(EFA),Nvidia GPU 栈和许多深度学习框架(TensorFlow、MXNet 和 PyTorch,最新版本为2.0),用于高性能分布式深度学习训练。您无需花费时间安装和故障排除深度学习软件和驱动程序,或构建ML基础架构,也无需承担修补这些镜像以防止安全漏洞或在每个新框架版本升级后重新创建镜像的重复成本。相反,您可以专注于以更短的时间规模化培训作业,并更快地迭代您的ML模型。
解决方案概述
考虑到在GPU上进行训练并在CPU上进行推理是AWS客户的常见用例,我们在本文中包含了混合架构的逐步实现(如下图所示)。我们将探索可能性,并使用使用已初始化了Base GPU DLAMI的P4 EC2实例,其中包括NVIDIA驱动程序、CUDA、NCCL、EFA堆栈和PyTorch 2.0 DLC,对RoBERTa情感分析模型进行微调,这使您可以控制和灵活地使用任何开源或专有库。然后,我们使用SageMaker作为完全托管的模型托管基础架构,将我们的模型托管在AWS Graviton3基础的C7g实例上。我们选择在SageMaker上使用C7g,因为与SageMaker上的实时推理可比较的EC2实例相比,它已被证明可以将推理成本降低高达50%。下面的图示说明了这种架构。
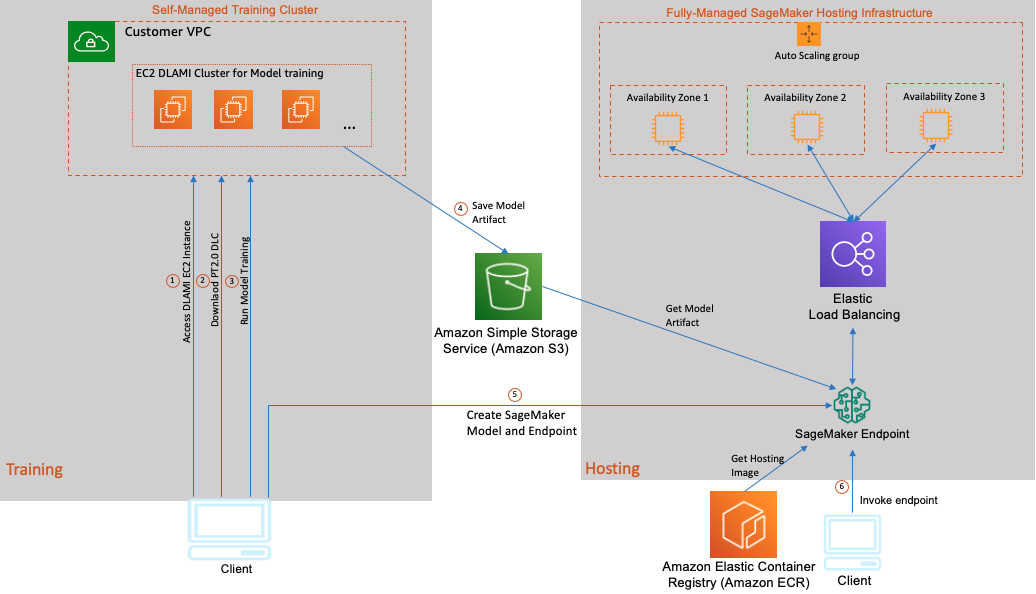
此用例中的模型训练和托管包括以下步骤:
- 在您的VPC中启动基于GPU DLAMI的EC2 Ubuntu实例,并使用SSH连接到您的实例。
- 登录到您的EC2实例后,下载AWS PyTorch 2.0 DLC。
- 使用一个模型训练脚本运行您的DLC容器,以微调RoBERTa模型。
- 模型训练完成后,将保存的模型、推理脚本和一些元数据文件打包成SageMaker推理可使用的tar文件,并将模型包上传到Amazon Simple Storage Service(Amazon S3)存储桶中。
- 使用SageMaker部署模型,并创建一个HTTPS推理端点。SageMaker推理端点包含负载均衡器和不同可用区中的一个或多个推理容器的实例。您可以在此单个端点后面部署同一模型的多个版本或完全不同的模型。在此示例中,我们托管单个模型。
- 通过发送测试数据来调用您的模型端点,并验证推理输出。
在以下部分中,我们展示了使用RoBERTa模型进行情感分析微调的过程。RoBERTa是由Facebook AI开发的,通过修改关键超参数并在更大的语料库上进行预训练,改进了流行的BERT模型。这导致相对于原始BERT的性能有所提高。
我们使用Hugging Face的transformers库获取RoBERTa模型,该模型在大约1.24亿条推文上进行了预训练,并在Twitter情感分析数据集上进行了微调。
先决条件
确保您满足以下先决条件:
- 您拥有一个AWS帐户。
- 确保您在
us-west-2区域中运行此示例。(此示例在us-west-2中进行了测试;但是,您可以在任何其他区域中运行。) - 创建名称为
sagemakerrole的角色。添加托管策略AmazonSageMakerFullAccess和AmazonS3FullAccess以授予SageMaker访问S3存储桶的权限。 - 创建名称为
ec2_role的EC2角色。使用以下权限策略:
#参考-确保EC2角色具有以下策略
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ecr:BatchGetImage",
"ecr:BatchCheckLayerAvailability",
"ecr:CompleteLayerUpload",
"ecr:GetDownloadUrlForLayer",
"ecr:InitiateLayerUpload",
"ecr:PutImage",
"ecr:UploadLayerPart",
"ecr:GetAuthorizationToken",
"s3:*",
"s3-object-lambda:*",
"iam:Get*",
"iam:PassRole",
"sagemaker:*"
],
"Resource": "*"
}
]
}1. 启动开发实例
我们创建一个p4d.24xlarge实例,该实例在us-west-2中提供8个NVIDIA A100 Tensor Core GPU:
#步骤1.1
有关启动实例的简短指南,请阅读入门Amazon EC2文档。选择AMI时,请遵循发布说明,使用AWS命令行界面(AWS CLI)运行此命令以查找要在us-west-2中使用的AMI ID:
#步骤1.2-这需要AWS CLI凭据来调用ec2 describe-images api (ec2:DescribeImages)。
aws ec2 describe-images --region us-west-2 --owners amazon --filters 'Name=name,Values=Deep Learning Base GPU AMI (Ubuntu 20.04) ????????' 'Name=state,Values=available' --query 'reverse(sort_by(Images, &CreationDate))[:1].ImageId' --output text 确保gp3根卷的大小为200 GiB。
默认情况下未启用EBS卷加密。在将此解决方案移动到生产时,请考虑更改此设置。
2. 下载深度学习容器
AWS DLC可作为Docker映像在Amazon Elastic Container Registry Public中使用,这是一个托管的AWS容器映像注册服务,安全、可扩展且可靠。每个Docker映像都是针对特定的深度学习框架版本、Python版本,具有CPU或GPU支持的训练或推断而构建的。从可用的Deep Learning Containers映像列表中选择PyTorch 2.0框架。
完成以下步骤以下载您的DLC:
a. SSH到实例。默认情况下,与EC2配合使用的安全组会打开SSH端口。如果您将此解决方案移动到生产中,请考虑这一点:
#步骤2.1-使用公共IP
ssh -i ~/.ssh/<pub_key> ubuntu@<IP_ADDR>
#参考-输出:请注意我们将用于运行和安装推理脚本的python3.9包
__| __|_ )
_| ( / Deep Learning Base GPU AMI (Ubuntu 20.04)
___|\___|___|
欢迎使用Ubuntu 20.04.6 LTS(GNU/Linux 5.15.0-1035-aws x86_64v)
* 请注意,当前DLAMI上不支持Amazon EC2 P2实例。
* 支持的EC2实例:G3、P3、P3dn、P4d、P4de、G5、G4dn。
NVIDIA驱动程序版本:525.85.12
默认CUDA版本:11.2
实用程序库已安装在/usr/bin/python3.9中。
要访问它们,请使用/usr/bin/python3.9。默认情况下,与 Amazon EC2 一起使用的安全组会向所有端口开放 SSH 端口。如果要将此解决方案移至生产环境,请考虑更改此设置。
b. 设置运行此实现的其余步骤所需的环境变量:
#步骤 2.2
从 AWS 控制台中将“ec2_role”角色附加到您的 EC2 实例。
#步骤 2.3
按照此处的步骤在 us-west-2 区域创建 S3 存储桶
#步骤 2.4 - 设置环境变量
#在步骤 2.3 中创建的存储桶
export S3_BUCKET=<your-s3-bucket>
export PYTHON_V=python3.9
export SAGEMAKER_ROLE=$(aws iam get-role --role-name sagemakerrole --output text --query 'Role.Arn')
aws configure set default.region 'us-west-2'Amazon ECR 支持使用 AWS 身份和访问管理 (IAM) 的资源权限支持公共镜像仓库,以便特定用户或服务可以访问镜像。
c. 登录到 DLC 注册表:
#步骤 2.5 - 登录
aws ecr get-login-password --region us-west-2 | docker login --username AWS --password-stdin 763104351884.dkr.ecr.us-west-2.amazonaws.com
#参考 - 输出
登录成功d. 在 us-west-2 中拉取支持 GPU 的最新 PyTorch 2.0 容器
#步骤 2.6 - 拉取最新的 DLC PyTorch 镜像
docker pull 763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-ec2
#参考 - 输出
7608715873ec: 已完成拉取
a0bad51e1731: 已完成拉取
f7778ea3b9cc: 已完成拉取
....
Digest: sha256:1ab0d477345a11970d811cc252bc461dd70859f15caa19a65198e7941953e6b8
StaRefertus: 已下载 763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-ec2 的新镜像
763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-ec2如果出现“设备上没有剩余空间”的错误,请确保将 EC2 EBS 卷增加到 200 GiB,然后扩展 Linux 文件系统。
3. 克隆适用于 PyTorch 2.0 的最新脚本
使用以下代码克隆脚本:
#步骤 3.1
cd $HOME
git clone https://github.com/aws-samples/aws-deeplearning-labs.git
cd aws-deeplearning-labs/workshop/twitter_lm/scripts/
export ml_working_dir=$PWD因为我们使用了 Hugging Face transformers API 的最新版本 4.28.1,它已经启用了 PyTorch 2.0 支持。我们在 train_sentiment.py 的训练器 API 中添加了以下参数以启用新的 PyTorch 2.0 功能:
- Torch compile – 使用一行代码在 Nvidia A100 GPU 上平均获得 43% 的加速。
- BF16 数据类型 – Ampere 或更新的 GPU 的新数据类型支持 (Brain Floating Point)。
- 融合的 AdamW 优化器 – 融合的 AdamW 实现,进一步加快训练。这种随机优化方法通过将权重衰减与梯度更新分离来修改 Adam 中的典型权重衰减实现。
#参考 - 更新的训练配置
training_args = TrainingArguments(
do_eval=True,
evaluation_strategy='epoch',
output_dir='test_trainer',
logging_dir='test_trainer',
logging_strategy='epoch',
save_strategy='epoch',
num_train_epochs=10,
learning_rate=1e-05,
# pytorch 2.0.0 specific args
torch_compile=True,
bf16=True,
optim='adamw_torch_fused',
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
load_best_model_at_end=True,
metric_for_best_model='recall',
)4. 使用依赖项构建新的 Docker 镜像
我们扩展了预构建的 PyTorch 2.0 DLC 镜像以安装 Hugging Face transformer 和我们需要微调模型的其他库。这样,您就可以使用已经测试和优化的深度学习库和设置,而无需从头创建镜像。请参见以下代码:
#步骤 4.1 - 创建具有以下内容的 Dockerfile
printf 'FROM 763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-ec2
RUN pip install scikit-learn evaluate transformers xformers
' > Dockerfile
#步骤 4.2 - 构建新的 Docker 文件
docker build -f Dockerfile -t pytorch2.0:roberta-sentiment-analysis .5. 使用容器开始训练
运行以下 Docker 命令,开始在tweet_eval情感数据集上微调模型。我们使用了 Nvidia 推荐的深度学习工作负载的 Docker 容器参数(共享内存大小、最大锁定内存和堆栈大小)。
#步骤 5.1 - 运行用于模型训练的 Docker 容器
docker run --net=host --uts=host --ipc=host --shm-size=1g --ulimit stack=67108864 --ulimit memlock=-1 --gpus all -v "/home/ubuntu:/workspace" pytorch2.0:roberta-sentiment-analysis python /workspace/aws-deeplearning-labs/workshop/twitter_lm/scripts/train_sentiment.py您应该期望看到以下输出。脚本首先下载包含七个 Twitter 中的多样化任务的 TweetEval 数据集,全部作为多类别推文分类。这些任务包括讽刺、仇恨、攻击性、立场、表情符号、情感和情感。
然后,脚本将下载基本模型并开始微调过程。在每个时期结束时报告训练和评估指标。
#参考 - 输出
{'loss': 0.6927, 'learning_rate': 9e-06, 'epoch': 1.0}
{'eval_loss': 0.6144512295722961, 'eval_recall': 0.7129473901625799, 'eval_runtime': 3.2694, 'eval_samples_per_second': 611.74, 'eval_steps_per_second': 4.894, 'epoch': 1.0}
{'loss': 0.5554, 'learning_rate': 8.000000000000001e-06, 'epoch': 2.0}
{'eval_loss': 0.5860999822616577, 'eval_recall': 0.7312511094156663, 'eval_runtime': 3.3918, 'eval_samples_per_second': 589.655, 'eval_steps_per_second': 4.717, 'epoch': 2.0}
{'loss': 0.5084, 'learning_rate': 7e-06, 'epoch': 3.0}
{'eval_loss': 0.6119785308837891, 'eval_recall': 0.730757638985487, 'eval_runtime': 3.592, 'eval_samples_per_second': 556.791, 'eval_steps_per_second': 4.454, 'epoch': 3.0}性能统计数据
在 PyTorch 2.0 和最新的 Hugging Face transformers 库 4.28.1 中,我们在单个 p4d.24xlarge 实例上使用 8 个 A100 40GB GPU 观察到了 42% 的加速。性能提升来自于 torch.compile、BF16 数据类型和融合的 AdamW 优化器的组合。以下代码是两次训练运行的最终结果:
#参考性能统计数据
没有 torch.compile + bf16 + fused adamw:
{'eval_loss': 0.7532123327255249, 'eval_recall': 0.7315191840508296, 'eval_runtime': 3.7641, 'eval_samples_per_second': 531.341, 'eval_steps_per_second': 4.251, 'epoch': 10.0}
{'train_runtime': 1891.5635, 'train_samples_per_second': 241.15, 'train_steps_per_second': 1.887, 'train_loss': 0.4372138784713104, 'epoch': 10.0}
使用 torch.compile + bf16 + fused adamw:
{'eval_loss': 0.7548801898956299, 'eval_recall': 0.7251081080195005, 'eval_runtime': 3.5685, 'eval_samples_per_second': 560.453, 'eval_steps_per_second': 4.484, 'epoch': 10.0}
{'train_runtime': 1095.388, 'train_samples_per_second': 416.428, 'train_steps_per_second': 3.259, 'train_loss': 0.44210514314368327, 'epoch': 10.0}6. 在准备 SageMaker 推理之前本地测试已训练的模型
在训练后,您可以在 $ml_working_dir/saved_model/ 下找到以下文件:
#参考 - 模型训练工件
config.json
merges.txt
pytorch_model.bin
special_tokens_map.json
tokenizer.json
tokenizer_config.json
vocab.json在准备 SageMaker 推理之前,让我们确保我们可以在本地运行推理。我们可以使用 test_trained_model.py 脚本加载保存的模型并在本地运行推理:
#步骤 6.1 - 运行测试模型推理的 Docker 容器
docker run --net=host --uts=host --ipc=host --ulimit stack=67108864 --ulimit memlock=-1 --gpus all -v "/home/ubuntu:/workspace" pytorch2.0:roberta-sentiment-analysis python /workspace/aws-deeplearning-labs/workshop/twitter_lm/scripts/test_trained_model.py您应该期望使用输入 “Covid cases are increasing fast!” 获得以下输出:
#参考 - 输出
[{'label': 'negative', 'score': 0.854185163974762}]7. 为 SageMaker 推理准备模型 tarball 包
在模型所在的目录下,创建一个名为 code 的新目录:
#步骤 7.1 - 设置权限
cd $ml_working_dir
sudo chown ubuntu:ubuntu saved_model
cd saved_model
mkdir code在新目录中,创建文件 inference.py 并添加以下内容:
#步骤 7.2 - 写入 inference.py
printf 'import json
from transformers import pipeline
REQUEST_CONTENT_TYPE = "application/x-text"
STR_DECODE_CODE = "utf-8"
RESULT_CLASS = "sentiment"
RESULT_SCORE = "score"
def model_fn(model_dir):
sentiment_analysis = pipeline(
"sentiment-analysis",
model=model_dir,
tokenizer=model_dir,
return_all_scores=True
)
return sentiment_analysis
def input_fn(request_body, request_content_type):
if request_content_type == REQUEST_CONTENT_TYPE:
input_data = request_body.decode(STR_DECODE_CODE)
return input_data
def predict_fn(input_data, model):
return model(input_data)
def output_fn(prediction, accept):
class_label = None
score = -1
for _pred in prediction[0]:
if _pred["score"] > score:
score = _pred["score"]
class_label = _pred["label"]
return json.dumps({RESULT_CLASS: class_label, RESULT_SCORE: score})' > code/inference.py在同一目录下再创建一个名为 requirements.txt 的文件,并将 transformers 放入其中。SageMaker 会为您在推理容器中安装 requirements.txt 中的依赖项。
#步骤 7.3 - 写入 requirements.txt
printf 'transformers' > code/requirements.txt最后,您应该拥有以下文件夹结构:
#参考 - 推理包文件夹结构
code/
code/inference.py
code/requirements.txt
config.json
merges.txt
pytorch_model.bin
special_tokens_map.json
tokenizer.json
tokenizer_config.json
vocab.json模型已准备好打包并上传到 Amazon S3 以用于 SageMaker 推理:
#步骤 7.4 - 创建推理包 tar 文件并将其上传到 S3
sudo tar -cvpzf ./personal-roberta-base-sentiment.tar.gz -C ./ .
aws s3 cp ./personal-roberta-base-sentiment.tar.gz s3://$S3_BUCKET8. 在 SageMaker AWS Graviton 实例上部署模型
新一代 CPU 由于具有专门的内置指令,在 ML 推理方面提供了显著的性能提升。在此用例中,我们使用 AWS Graviton3 基于 C7g 实例的 SageMaker 完全托管的托管基础设施。AWS 还测量了使用 AWS Graviton3 基于 EC2 C7g 实例的 PyTorch 推理的成本节省高达 50%,并且相对于可比较的 EC2 实例,多个 Hugging Face 模型与 Torch Hub ResNet50。
要将模型部署到AWS Graviton实例,我们使用提供对PyTorch 2.0和TorchServe 0.8.0支持的AWS DLCs,或者您可以自己带入与ARMv8.2架构兼容的容器。
我们使用我们之前训练的模型:s3://<your-s3-bucket>/twitter-roberta-base-sentiment-latest.tar.gz。如果您之前没有使用过SageMaker,请查看入门指南。
首先,请确保SageMaker包是最新的:
#步骤8.1-安装SageMaker库
cd $ml_working_dir
$PYTHON_V -m pip install -U sagemaker由于这是一个示例,因此创建一个名为start_endpoint.py的文件,并添加以下代码。这将是启动SageMaker推理端点的Python脚本:
#步骤8.2-编写start_endpoint.py
printf '#导入一些需要的模块
from sagemaker import get_execution_role, Session, image_uris
from sagemaker.model import Model
import boto3
import os
model_name = "pytorch-roberta-model"
#设置SageMaker会话
region = boto3.Session().region_name
role = os.environ.get("SAGEMAKER_ROLE")
sm_client = boto3.client("sagemaker", region_name=region)
sagemaker_session = Session()
bucket = os.environ.get("S3_BUCKET")
#选择容器。在我们的例子中,是graviton
container_uri = image_uris.retrieve(
region="us-west-2",
framework="pytorch",
version="2.0.0",
image_scope="inference_graviton")
#设置模型参数
model = Model(
image_uri=container_uri,
model_data=f"s3://{bucket}/personal-roberta-base-sentiment.tar.gz",
role=role,
name=model_name,
sagemaker_session=sagemaker_session
)
#部署模型
endpoint = model.deploy(
initial_instance_count=1,
instance_type="ml.c7g.4xlarge",
endpoint_name="sm-endpoint-" + model_name
)' > start_endpoint.py我们使用ml.c7g.4xlarge实例,并使用图像范围inference_graviton检索PT 2.0。这是我们的AWS Graviton3实例。
接下来,我们创建运行预测的文件。我们将其作为单独的脚本执行,以便可以随意运行预测。创建predict.py并添加以下代码:
#步骤8.3-编写predict.py
printf 'import boto3
from boto3 import Session, client
model_name = "pytorch-roberta-model"
data = "Writing data to analyze sentiments and see how the data is viewed"
sagemaker_runtime = boto3.client("sagemaker-runtime", region_name="us-west-2")
endpoint_name="sm-endpoint-" + model_name
print("Calling model:" + endpoint_name)
response = sagemaker_runtime.invoke_endpoint(
EndpointName=endpoint_name,
Body=bytes(data, "utf-8"),
ContentType="application/x-text",
)
print(response["Body"].read().decode("utf-8"))' > predict.py生成脚本后,我们现在可以启动端点,在端点上进行预测,完成后清理:
#步骤8.4-启动SageMaker推理端点
$PYTHON_V start_endpoint.py
#步骤8.5-进行预测,这可以运行多次
$PYTHON_V predict.py
#参考-预测输出
Calling model:sm-endpoint-pytorch-roberta-model
{"sentiment": "neutral", "score": 0.9342969059944153}9. 清理
最后,我们要清除这个示例。创建cleanup.py并添加以下代码:
#步骤9.1-清理脚本
printf 'from boto3 import client
model_name = "pytorch-roberta-model"
endpoint_name="sm-endpoint-" + model_name
sagemaker_client = client("sagemaker", region_name="us-west-2")
sagemaker_client.delete_endpoint(EndpointName=endpoint_name)
sagemaker_client.delete_endpoint_config(EndpointConfigName=endpoint_name)
sagemaker_client.delete_model(ModelName=model_name)' > cleanup.py
#步骤9.2-清理
$PYTHON_V cleanup.py结论
AWS DLAMIs和DLCs已成为在AWS上运行深度学习工作负载的首选标准,可在广泛的计算和ML服务上使用。除了在AWS ML服务上使用特定于框架的DLC之外,您还可以在Amazon EC2上使用单个框架,这消除了开发人员构建和维护深度学习应用程序所需的沉重工作。请参阅DLAMI的发布说明和可用的深度学习容器映像以开始使用。
本文展示了在AWS上训练和服务您的下一个模型的众多可能性,并讨论了几种可采用的格式,以满足您的业务目标。尝试使用此示例或使用我们的其他AWS ML服务来扩大业务的数据生产力。我们包括了一个简单的情感分析问题,以便新手客户了解在AWS上使用PyTorch 2.0开始非常简单。我们将在即将发布的博客文章中涵盖更多高级用例,模型和AWS技术。


