训练你的第一个基于深度Q学习的强化学习智能体:一步一步指南
介绍:
强化学习(RL)是人工智能(AI)领域中一门引人入胜的技术,使机器能够通过与环境的交互来学习和做出决策。训练RL代理涉及一次试错过程,代理从其行动以及其接收到的后续奖励或惩罚中学习。在本文中,我们将探讨训练第一个RL代理所涉及的步骤,以及用于说明该过程的代码片段。
步骤1:定义环境
训练RL代理的第一步是定义其将运行的环境。环境可以是模拟或真实场景。它向代理提供观察和奖励,使其能够学习和做出决策。OpenAI Gym是一个流行的Python库,提供了各种预构建的环境。让我们以经典的“CartPole”环境为例。
import gymenv = gym.make('CartPole-v1')步骤2:了解代理-环境交互
在RL中,代理通过根据其观察结果采取行动与环境进行交互。它以奖励或惩罚的形式获得反馈,用于指导其学习过程。代理的目标是最大化随时间累积的奖励。为此,代理学习策略-从观察到行动的映射-以帮助它做出最佳决策。
步骤3:选择RL算法
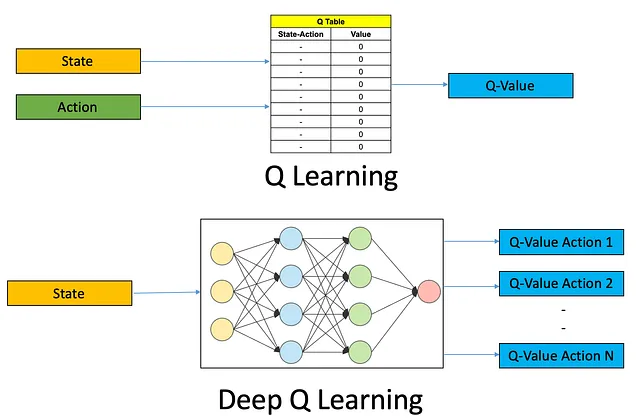
有各种RL算法可用,每种算法都有其自身的优点和缺点。一种流行的算法是Q-Learning,适用于离散行动空间。另一个常用的算法是Deep Q-Networks(DQN),它利用深度神经网络处理复杂环境。对于本例,让我们使用DQN算法。
- 深度学习在人工智能中的常见应用
- 使用 AWS Trainium 实例驱动的 Amazon ECS 扩展您的机器学习工作负载
- 使用Hugging Face和LoRA在单个Amazon SageMaker GPU上训练大型语言模型

步骤4:构建RL代理
要使用DQN算法构建RL代理,我们需要定义一个神经网络作为函数逼近器。该网络将观察结果作为输入,并为每个可能的行动输出Q值。我们还需要实现一个回放记忆以存储和采样训练经验。
import torchimport torch.nn as nnimport torch.optim as optimclass DQN(nn.Module): def __init__(self, input_dim, output_dim): super(DQN, self).__init__() self.fc1 = nn.Linear(input_dim, 64) self.fc2 = nn.Linear(64, 64) self.fc3 = nn.Linear(64, output_dim) def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x# 创建DQN代理实例input_dim = env.observation_space.shape[0]output_dim = env.action_space.nagent = DQN(input_dim, output_dim) 步骤5:训练RL代理
现在,我们可以使用DQN算法训练RL代理。代理与环境进行交互,观察当前状态,根据其策略选择一个行动,接收奖励,并相应地更新其Q值。这个过程重复指定数量的周期,或直到代理达到令人满意的性能水平。
optimizer = optim.Adam(agent.parameters(), lr=0.001)def train_agent(agent, env, episodes): for episode in range(episodes): state = env.reset() done = False episode_reward = 0 while not done: action = agent.select_action(state) next_state, reward, done, _ = env.step(action) agent.store_experience(state, action, reward, next_state, done) agent
结论:
在本博客中,我们探讨了训练您的第一个强化学习代理的过程。我们首先使用OpenAI Gym定义了环境,该环境为RL任务提供了一系列预构建的环境。然后我们讨论了代理-环境交互以及代理最大化累积奖励的目标。
接下来,我们选择了DQN算法作为我们的RL算法,它将深度神经网络与Q-learning相结合,以处理复杂环境。我们使用神经网络作为函数逼近器构建了RL代理,并实现了重放记忆以存储和采样经验进行训练。
最后,我们通过让RL代理与环境交互,观察状态,根据其策略选择动作,接收奖励并更新其Q值来训练RL代理。这个过程重复了指定的一些集数,使代理能够学习并改进其决策能力。
强化学习为训练能够在动态环境中自主学习和决策的智能代理打开了无限的可能性。通过遵循本博客中概述的步骤,您可以开始训练RL代理并探索各种算法、环境和应用。
请记住,RL训练需要实验、微调和耐心。随着您深入探索RL,您可以探索高级技术,如深度RL、策略梯度和多代理系统。因此,请继续学习、迭代并推动您的RL代理所能实现的极限。
开心训练!
LinkedIn: https://www.linkedin.com/in/smit-kumbhani-44b07615a/
我的Google学者: https://scholar.google.com/citations?hl=en&user=5KPzARoAAAAJ
关于“气胸检测和分割的语义分割”博客 https://medium.com/becoming-human/semantic-segmentation-for-pneumothorax-detection-segmentation-9b93629ba5fa