“开源模型与商业AI/ML API之间的区别”
Differences between Open Source Models and Commercial AI/ML APIs
超越模型性能的多维分析
在过去的几个月中,你可能遇到了无数关于是否应该使用开源或商业API来进行大型语言模型(LLMs)的辩论。然而,这并不仅限于LLMs,这个问题适用于机器学习(ML)的一般情况。在过去5年中,作为AWS的ML架构师,我被很多客户问到这个问题。
在本文中,我将分享我采用的方法,帮助ML工程师、决策者和ML团队在使用开源ML模型或商业ML API之间进行选择。
这种方法不仅仅考虑模型性能,还考虑到了成本、工程时间、所有权和维护等多个分析维度,在生产环境中使用ML时非常关键,甚至更重要。
1. 在开始之前,让我们弄清楚一些定义!
开源ML模型是模型架构(模型设计)和权重(模型的知识)的组合。你可以在像Hugging Face、Pytorch Hub、Tensorflow Hub这样的公共模型库中获取这些模型。
商业ML API(例如OpenAI API)是通过API端点访问的服务,封装了ML模型,以及我们将很快讨论的其他内容。这些ML API可以在云服务提供商(AWS、Azure、GCP等)或专门从事某个领域/ML任务子集的较小公司(Mindee、Lettria、Gladia等)的服务中找到。
表面上看,它们看起来非常相似:你输入数据,然后得到所需的输出,比如文本生成。但让我们深入探讨一下它们的不同之处。
2. ML API不仅仅是一个“封装在API中的ML模型”
让我们看一下模型周围的组成部分以及它们的用途:
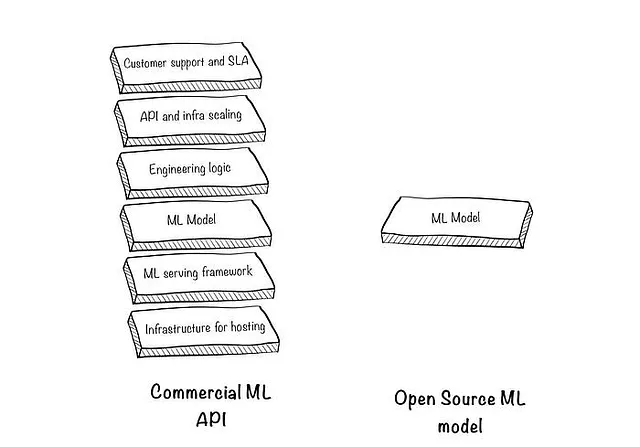
2.1 托管基础设施:当你选择一个ML模型时,你首先要决定在哪里运行它。如果你只是在做实验,并且模型相对较小,你可以在自己的机器上运行它。但这并非总是可行的或可扩展的,所以你需要通过云服务提供商(AWS、GCP、Azure)租用服务器。
2.2 ML服务框架:一个模型不仅仅是一个“python函数”。为了以最优的方式提供预测结果,你需要使用一个服务框架(如TorcheServe、TFServing以及更多面向LLM的框架)。这些框架是为了实现优化的延迟和处理高并发而必不可少的,但它们也有一个学习曲线。
2.3 工程逻辑:这非常依赖于具体情况,有时可能会消耗大量的ML工程师的时间(魔鬼就在细节中)。
以情感分析为例,一个简单的用例。下面是来自Hugging Face的一个示例:

如果你只需要生成几行文本的情感,那就这样结束了。
然而,如果你有10k个文档(不同的格式:pdf、word、文本),并且你想检测它们的情感。你需要:
- 首先,将PDF文件通过光学字符识别(OCR)模型进行处理。
- 处理任何边缘情况(多页、页面方向不正确等)
- 根据文档类型可能使用不同的模型,并构建一个编排工作流程以将所有数据转换为正确的格式
- 将所有内容传递给情感分析模型。但你注意到你不能顺序地做这件事,因为这将花费很长时间
- 实现一个并行处理的流水线,将X个文档分割成多个进程(可能是多个服务器),运行预测并返回结果
- 创建测试和自动化流程,以确保上述解决方案的稳定性
这些组件是通过商业机器学习API抽象出来的细节的魔鬼。API提供者将雇佣团队中的工程师来完成上述工作、进行维护和更新,因此您可以使用类似以下的代码:
#伪代码(不是真正的库)import providerx#您设置一个API密钥以便访问提供者providerx.api-key = "123452" #这将将数据传递给提供者,执行上述步骤并返回情感结果sentiments = providerx.detect_sentiment('./folder-containing-documents/', document_types=["pdf","word", "txt"]))2.4 API和基础设施扩展:这包括两个方面。首先,将以上所有组件打包成一个API,使您的模型预测能够被您的技术堆栈和产品访问。其次,确保它能够处理并发和突然的流量增加。示例如下:
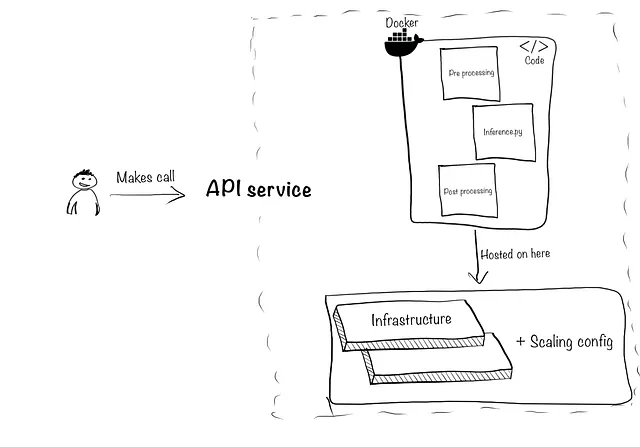
要打包您的模型,您需要将推断代码(inference.py脚本)、任何其他预处理/后处理文件组合起来,创建一个Docker容器,并使用FastAPI、Amazon API网关、Apigee API管理等工具创建API。
然后是扩展,您越多的用户或预测,您创建的API背后所需的基础设施就越多。您可以从一个小型服务器(约30美元/月)开始,根据用户流量的情况可能需要扩展到(约200美元/月)。然后,在没有人使用您的API时再进行缩减。
这就是事情变得混乱的地方,您不再只是进行机器学习预测,而是在团队内创建了一个小型软件/服务。
如果这是您的核心业务(例如,您正在构建公司零售网站的推荐系统),那就没问题。但如果这个项目是用于支持功能(例如,从操作文档中提取文本以便于在Excel中输入数据),那就完全是冒险的
2.5 客户支持和SLA:最后但同样重要的是,当事情不按预期工作或出现故障时,谁来修复?
当您在团队内部使用开源机器学习模型构建解决方案时,您还应该至少有一名工程师专门负责支持和故障修复。
当您使用商业机器学习API时,获得支持是服务的一部分,而且有服务级别协议(SLAs)。例如,SLA可能是“如果我们的服务出现故障,我们将指派一名工程师在6小时内修复它”。
最后,请注意,商业机器学习API可以通过设计来完成更多的任务,并不意味着您不能自己完成这些任务。重要的是,您知道这些是您最终需要构建的元素,如果希望达到商业机器学习API的相同服务水平。
3. 在比较成本时,请使用总拥有成本(TCO)
大多数人停留在“机器学习模型是免费的”或“API调用太贵”的观点上,让我们来看看其中有多少是真实的。
首先从生成预测的成本开始:
1/使用开源模型:在g4dn.xlarge实例上托管一个ResNet50(用于图像分类)的成本为每小时0.526美元,该模型可以实现每秒约75个预测(表格在这里的结尾)。假设您需要确保对用户实时响应,所以您需要将实例保持运行24/7,这将花费约400美元,如果您可以不停地使用API,则可以进行约2亿次(75*60*60*24*31)预测。
2/使用Amazon Rekognition API:每次预测的成本为0.00025美元,如果您想在一个月内实现2亿次预测,那将是惊人的50000美元
所以很明显,您应该选择选项1,对吗?好吧,这要取决于您每月进行多少次调用:
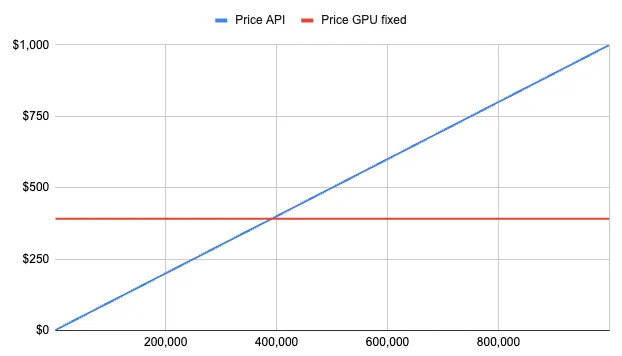
请注意,该图表不考虑流量中的“突发”情况。当您同时有更多用户调用您的ML模型时,您需要启动更多的服务器来处理负载。因此,GPU的价格并不完全固定,但为了简化起见,让我们专注于稳定的工作负载并得出以下结论:
-> 如果您每月的预测次数少于400,000次,最好选择付费的商业ML API。如果您的量超过这个数量,请每月选择开源版本并自行托管。
注意:这里还进行了有关LLMs的类似研究。
到目前为止,我们只看了预测的成本。然而,在考虑成本时,您应该看总拥有成本(TCO)。它基本上回答了以下问题:
如果我们包括模型、基础设施、工程时间、运营和维护工作,这将花费多少钱?
工程逻辑、框架配置、基础设施的可扩展性、维护和支持等等,这些都需要人力成本。这是最难估计的部分,因为它取决于您想要实现什么样的ML任务,您想要提供什么级别的服务以及您拥有的资源。
假设您雇佣了两个人,一个是ML专家,另一个是后端/云专家。美国软件工程师的平均年薪是12万美元(欧洲为6万美元),所以最低为24万美元(欧洲为12万美元)*(确实,glassdoor)
简而言之,商业ML API雇用工程师,租用基础设施,并通过其API的服务互通的力量,能够“租用”其基础设施和工程能力的一部分,因此您不必在自己一方承担重大责任。
4. 精调
“是的,但我喜欢将模型调整到我的数据和用例”。您可以使用开源模型和商业ML API来完成这个操作。不同之处在于定制程度和定制所需的工作量。
请记住,在这两种情况下,最困难的部分是获取数据并准备好用于精调。
对于开源模型,您肯定有更多的灵活性。因为您可以访问模型,所以您可以深入研究,甚至更改模型的架构。然而,这需要您有ML知识的人,不仅要了解如何正确地对模型进行精调,还要了解模型的结构和参数。
对于商业ML API,您将获得较少的灵活性,但在您这方面的工作量也较少。最好的例子是最近发布的GPT-3.5精调商业API。其他例子是使用Amazon Rekognition的自定义标签,如果您使用特定图像或Mindee的OCR精调API用于自定义文档,则非常有用。
商业ML API会要求您通过其API/界面提供数据和标签,然后他们会处理剩下的事情:为您训练、优化和部署定制模型,使用与通用模型相同的堆栈。
从精调API开始,提供输入和输出,如果性能不佳,请首先联系提供者。他们可以评估您的用例并告诉您是否可行。如果不可行,则考虑雇佣一个能深入研究开源模型细节并进行适应的ML专家。
5. 安全和隐私
安全是指系统对抗攻击的能力。除非您的团队中有安全专家,否则您建立的系统可能比商业ML API的系统更不安全。他们有专门的安全团队,实施行业标准,并对其系统进行持续检查。
除非您采取相同的措施,否则您不能仅仅因为您自己管理它们就将开源和自托管的模型标记为“安全”。
另一方面,隐私是不同的;一旦您的数据离开您的数据中心/服务器并通过API传输,您就有可能将数据读取给除您之外的其他人。当这与监管规定相关联(例如:如果您的公司数据通过服务x,则需要执行操作y),那么只需要遵守这些规定并通过批准的程序即可。
当隐私与“提供者会查看我的数据”的关系相关时,请记住他们的业务是销售API调用,如果不能信任他们,他们就无法做到这一点。在使用API之前,请查看提供API的人是谁,他们到底是谁,以及他们的隐私规则是什么。知名供应商清楚地说明他们如何处理您的数据,在传输和静止时加密您的数据,有时甚至提供选择取消使用您的数据进行培训等选项。
总结和要点
下面是一张表格,提供了选择何时选择什么的指南
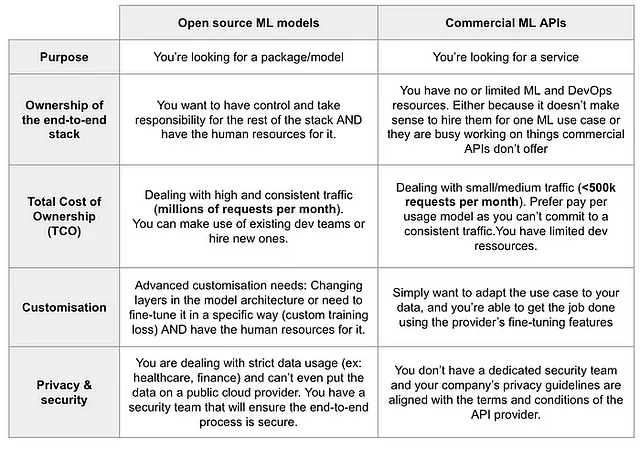
最重要的是要记住,开源ML模型和商业ML API都是必需的,它们只是服务于不同的目的。哪个更好取决于我们上面提到的标准和你的情况。以下是一些建议的摘要:
- 预测月交易量越高(> ~400-500k),您越有可能更适合使用开源模型并进行托管。
- 首先尝试商业ML API。如果它们能胜任工作并且价格符合您的预算,请坚持使用。如果价格稍高,请考虑雇佣人员来构建和维护类似的服务将花费多少。
- 如果结果不好,请尝试优化商业ML API的功能,处理您的数据,并/或与提供者联系寻求帮助。如果仍然不好,请考虑投资于ML专家;如果ML性能很好,请投资于ML工程师/DevOps来帮助将模型投入生产。
感谢阅读!如果我们还没有见面,我是Othmane,曾在AWS工作5年,担任ML工程师,帮助30多家公司将ML嵌入到其产品/业务中。
如果您有任何问题,请随时通过Twitter(@OHamzaoui1)或Linkedin(hamzaouiothmane)与我联系。






