30年数据科学:一位数据科学实践者的回顾
30年数据科学实践回顾

30年的VoAGI和30年的数据科学。大约30年的专业生涯。在同一个领域工作很长时间的一个特权 – 经验 – 是有机会作为直接目击者写下它的发展。
算法
我在90年代初开始从事当时被称为人工智能的工作,指的是一种自学习的新范式,模仿神经细胞的组织,并且不需要验证任何统计假设:是的,神经网络!在几年前刚刚发表了一个高效使用反向传播算法来解决多层神经网络中隐藏层训练问题的论文[1],使得热情的学生们能够针对许多旧的用例尝试新的解决方案。没有什么可以阻止我们…只有机器的算力。
训练一个多层神经网络需要相当大的计算能力,特别是如果网络参数的数量很多且数据集很大。然而,当时的机器并没有这样的计算能力。理论框架被发展出来,比如1988年的时间序列问题的BPTT(Back-Propagation Through Time)[2]或1997年的选择性记忆学习的LSTM(Long Short Term Memories)[3]。然而,计算能力仍然是一个问题,神经网络被大多数数据分析实践者搁置起来,等待更好的时机。
与此同时,更轻量级但表现往往相当的算法出现了。决策树以C4.5的形式在1993年变得流行,尽管CART形式的决策树早在1984年就已经存在。决策树的训练更轻松,更容易理解,并且在当时的数据集上表现良好。很快,我们还学会了将许多决策树组合在一起形成森林的随机森林算法[6],或者组合成级联的梯度提升树算法[7] [8]。尽管这些模型相当庞大,即具有大量需要训练的参数,但在合理的时间内仍然可以处理。特别是梯度提升树,通过顺序训练一系列树,随着时间的推移稀释了所需的计算能力,使其成为数据科学中一种非常实惠且非常成功的算法。
直到90年代末,所有的数据集都是相对较小的经典数据集:客户数据,患者数据,交易数据,化学数据等等。基本上,是经典的业务操作数据。随着社交媒体、电子商务和流媒体平台的扩展,数据开始以更快的速度增长,提出了全新的挑战。首先是存储和快速访问如此大量的结构化和非结构化数据的挑战。其次,需要更快的算法进行分析。大数据平台负责存储和快速访问。传统的托管结构化数据的关系数据库为新数据湖让出了空间,新数据湖可以托管各种类型的数据。此外,电子商务业务的扩展推动了推荐引擎的流行。无论是用于市场篮子分析还是视频流推荐,两种算法都变得常用:apriori算法[9]和协同过滤算法[10]。
与此同时,计算硬件的性能提高到了难以想象的速度,…我们又回到了神经网络。GPU开始被用作神经网络训练中特定操作的加速器,允许创建、训练和部署越来越复杂的神经算法和神经架构。神经网络的这第二个青春被称为深度学习[11] [12]。人工智能(AI)这个术语开始再次浮出水面。
深度学习的一个分支,生成式AI[13],专注于生成新数据:数字、文本、图像,甚至音乐。模型和数据的规模和复杂性不断增长,以实现更逼真的图像、文本和人机交互的生成。
新模型和新数据很快被连续循环中的新模型和新数据所取代。它变得越来越像一个工程问题而不是一个数据科学问题。最近,由于在数据和机器学习工程方面的令人钦佩的努力,已经开发出了用于连续数据收集、模型训练、测试、人工参与操作以及最终部署非常大型机器学习模型的自动化框架。所有这些工程基础设施是当前大型语言模型(LLMs)的基础,它们在模拟人与人之间的互动时培训以解决各种问题。
生命周期
在我看来,在过去的几年里,数据科学最大的变化不仅仅发生在算法上,而是发生在底层基础设施上:从频繁的数据获取到模型的持续平滑的重新训练和重新部署。也就是说,数据科学已经从一门研究学科转变为一项工程努力。
机器学习模型的生命周期已经从单个循环的纯创造、训练、测试和部署(如CRISP-DM [14]和其他类似的范式)变成了一个双重循环,其中一侧是创造,另一侧是生产化-部署、验证、使用和维护 [15]。
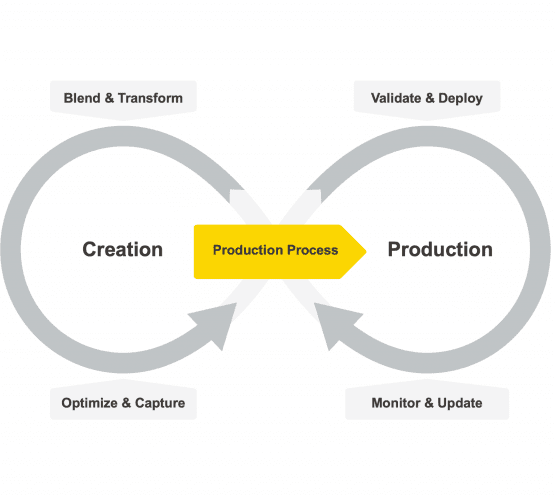
工具
因此,数据科学工具不得不进行调整。它们不仅要支持创造阶段,还要支持机器学习模型的生产化阶段。在同一个产品中必须有两个产品或两个独立部分:一个用于支持用户在数据科学模型的创造和训练过程中,另一个用于实现最终结果的平稳、无错误地生产化。虽然创造部分仍然是一种智力锻炼,但生产化部分是一项结构化的重复任务。
显然,在创造阶段,数据科学家需要一个拥有广泛机器学习算法覆盖范围的平台,从基本算法到最先进和复杂的算法都要有。你永远不知道你将需要哪个算法来解决哪个问题。当然,最强大的模型成功的几率更高,但代价是过拟合的风险更高,执行速度更慢。最终,数据科学家就像需要一个装满各种工具的工具箱来应对他们工作中的许多挑战的工匠。
基于低代码的平台也因此而受到了欢迎,因为低代码使得编程人员甚至非编程人员都能够创建和快速更新各种数据科学应用。
作为一种智力锻炼,机器学习模型的创造应该对每个人都是可接近的。这就是为什么,尽管不是严格必需的,一个开源的数据科学平台是可取的。开源允许所有有志于成为数据科学家的人自由访问数据操作和机器学习算法,并且同时允许社区对源代码进行调查和贡献。
在周期的另一侧,生产化需要一个提供可靠的IT框架,用于部署、执行和监控即将投入使用的数据科学应用。
结论
总结30年的数据科学演进不可能用不到2000个字。此外,我引用的是当时最流行的出版物,尽管它们可能不是该主题的绝对第一篇。对于在这个过程中发挥重要作用但我没有在这里提到的许多算法,我在此道歉。尽管如此,我希望这个简短的总结能让您更深入地了解我们在数据科学领域为何以及为什么会处于现在的位置30年后!
参考文献
[1] Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. (1986). “通过误差反向传播学习表示”。《Nature》,323,页码533-536。
[2] Werbos, P.J. (1988). “具有应用于循环气体市场模型的反向传播的推广”.《神经网络》,1(4):339–356。doi:10.1016/0893-6080(88)90007
[3] Hochreiter, S.; Schmidhuber, J. (1997). “长短期记忆”.《神经计算》,9(8):1735–1780。
[4] Quinlan, J. R. (1993). “C4.5: 用于机器学习的程序”。Morgan Kaufmann Publishers。
[5] Breiman, L. ; Friedman, J.; Stone, C.J.; Olshen, R.A. (1984) “分类和回归树”,Routledge。https://doi.org/10.1201/9781315139470
[6] 何, T.K.(1995)。随机决策森林。第三届国际文件分析与识别会议论文集,蒙特利尔,魁北克,1995年8月14日至16日。第278-282页
[7] 弗里德曼,J.H.(1999)。”贪婪函数近似:梯度提升机,莱茨演讲
[8] 梅森,L.; 巴克斯特,J.; 巴特利特,P.L.; 弗里恩,马库斯(1999)。”提升算法作为梯度下降”。在S.A. Solla和T.K. Leen和K. Müller(eds)的《神经信息处理系统12》中的进展。麻省理工学院出版社。第512-518页
[9] 阿格拉瓦尔,R.; 斯里坎特,R(1994年)挖掘关联规则的快速算法。第20届国际大型数据库会议,VLDB,页487-499,智利圣地亚哥,1994年9月。
[10] 布里斯,J.S .; Heckerman,D .; Kadie C.(1998年)“协同过滤的预测算法的实证分析”,第十四次不确定性人工智能会议(UAI1998)的论文集
[11] Ciresan,D .; Meier,U .; Schmidhuber,J。(2012)。”用于图像分类的多列深度神经网络”。2012年IEEE计算机视觉和模式识别会议。第3642-3649页。arXiv:1202.2745。doi:10.1109/cvpr.2012.6248110。ISBN 978-1-4673-1228-8。S2CID 2161592。
[12] Krizhevsky,A .; Sutskever,I .; Hinton,G.(2012)。”使用深度卷积神经网络的ImageNet分类”。NIPS 2012:神经信息处理系统,内华达州塔霍湖。
[13] Hinton,G.E .; Osindero,S .; Teh,Y.W.(2006)“一种用于深度信念网络的快速学习算法”。神经计算2006;18(7):1527-1554。doi:https://doi.org/10.1162/neco.2006.18.7.1527
[14] Wirth,R .; Jochen,H.。(2000)“CRISP-DM:面向数据挖掘的标准过程模型。”第4届国际实际应用知识发现和数据挖掘会议论文集(4),第29-39页。
[15] Berthold,R.M.(2021)“如何将数据科学应用于生产”,KNIME博客 Rosaria Silipo 不仅是数据挖掘,机器学习,报告和数据仓库方面的专家,她还成为了KNIME数据挖掘引擎的知名专家,关于该引擎,她出版了三本书:《KNIME入门指南》、《KNIME食谱》和《面向SAS用户的KNIME小册子》。之前,Rosaria曾在欧洲的多家公司担任自由数据分析员。她还在Viseca(苏黎世)领导了SAS开发小组,在Spoken Translation(加利福尼亚伯克利)以C#实现了语音到文本和文本到语音接口,并在Nuance Communications(加利福尼亚门洛帕克)开发了多种语言的语音识别引擎。Rosaria于1996年从意大利佛罗伦萨大学获得生物医学工程博士学位。






