被低估的宝藏之一:8个能让你成为专家的Pandas方法
8 Pandas methods that can make you an expert one of the underestimated treasures
被低估、被忽视、被探索不足
“在人群的喧嚣中,那些轻声细语的话语才蕴藏着隐藏的智慧💎”
暂时忘掉ChatGPT吧。对于我们中的一些人来说,每次想执行一个简单的Pandas操作时,不断地搜索解决方案已经让我们感到厌烦。似乎有很多种做同一件事的方式,哪个才是哪个?拥有很多可能的解决方案当然很好,但也会导致不一致和混淆,不明白代码要做什么。
到罗马有1000条可能的路线,甚至可能更多。问题是,你是选择隐藏的捷径还是走复杂的路线呢?

以下是本文的要点。我将通过对UCI机器学习¹的自行车共享数据集进行实际操作,向您展示如何将这些方法应用到实践中。通过采用这些方法,您不仅可以简化数据处理代码,还可以更深入地理解您编写的代码。让我们从导入数据集并快速查看数据框架开始!
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
bike = (pd
.read_csv("../../dataset/bike_sharing/day.csv")
)
bike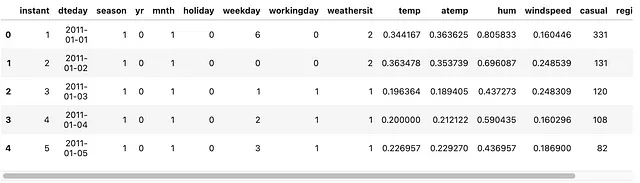
目录
- 方法1:
.assign() - 方法2:
.groupby() - 方法3:
.agg() - 方法4:
.transform() - 方法5:
.pivot_table() - 方法6:
.resample() - 方法7:
.unstack() - 方法8:
.pipe()
☕️ 方法1:.assign()
忘掉使用df["new_col"] =和df.new_col =等操作来创建新列。以下是您应该使用.assign()方法的原因:它返回一个DataFrame对象,可以继续链式操作来进一步操作您的数据框架。与.assign()方法不同,上述两个臭名昭著的操作会返回None,这意味着您不可能继续进行链式操作。
如果您还不相信,那就让我再次提醒您一个老对手——SettingWithCopyWarning。相信我们每个人在某个时候都遇到过它。

够了,我想在我的笔记本上不再看到丑陋的红色框框了!
使用.assign(),让我们添加一些新列,如ratio_casual_registered、avg_temp和ratio_squared
(bike .assign(ratio_casual_registered = bike.casual.div(bike.registered),
avg_temp = bike.temp.add(bike.atemp).div(2),
ratio_squared = lambda df_: df_.ratio_casual_registered.pow(2)))简而言之,上述方法的作用如下:
- 我们可以使用
.assign()方法创建任意数量的新列,用逗号分隔。 - 在创建
ratio_squared列时,lambda函数用于访问最新的DataFrame,之前我们添加了ratio_casual_registered列。假设我们不使用lambda函数来访问最新的DataFramedf_,而是继续使用bike.ratio_casual_registered.pow(2),我们将会得到一个错误,因为原始的DataFrame没有ratio_casual_registered列,即使在创建ratio_squared之前在.assign()方法中添加了它。如果你无法理解这个概念,无法决定是否使用lambda函数,我的建议是只使用一个! - 奖励!我留下了一些不太常见的使用方法进行算术运算的方式。
☕️ 方法2:.groupby()
嗯,.groupby()方法并不常用,但在我们深入研究下一些方法之前,它们是必不可少的。一个常常被忽视和未提及的事实是,.groupby()方法具有惰性特性。也就是说,它不会立即计算,这就是为什么在调用.groupby()方法后经常看到<pandas.core.groupby.generic.DataFrameGroupBy object at 0x14fdc3610>。
根据Pandas DataFrame文档²,参数by的值可以是映射、函数、标签、pd.Grouper或这些的列表。尽管如此,你可能遇到的最常见的是按列名分组(用逗号分隔的Series名称列表)。在.groupby()操作之后,我们可以执行诸如.mean()、.median()或使用.apply()应用自定义函数的操作。
我们在
.groupby()方法的by参数中提供的指定列的值将成为结果的索引。如果我们指定了多个分组列,那么我们将获得一个MultiIndex。
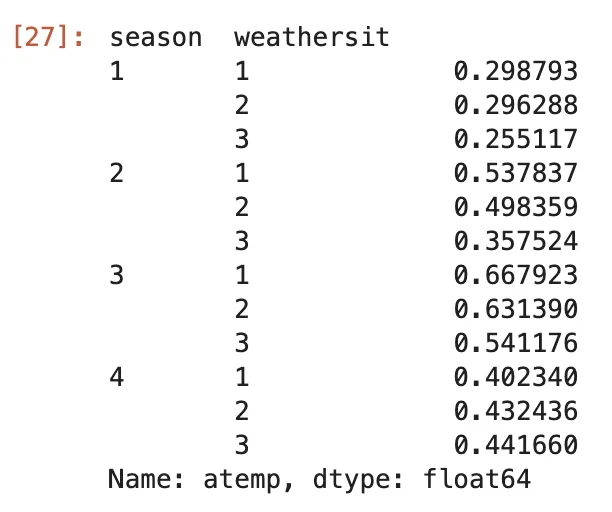
(bike .groupby(['season', 'weathersit']) .mean(numeric_only=True) #alternative version: apply(lambda df_: df_.mean(numeric_only=True)) .atemp)在这里,我们按season列和weathersit列对DataFrame进行分组。然后,我们计算平均值并仅选择列atemp。
☕️ 方法3:.agg()
如果你足够细心地查阅Pandas文档²,你可能会遇到.agg()和.aggregate()两个方法。你可能想知道它们的区别和何时使用哪个?节省你的时间!它们是相同的,.agg()只是.aggregate()的别名。
.agg()有一个func参数,它可以接受一个函数、字符串函数名称或函数列表。顺便说一下,你也可以对不同的列应用不同的函数进行聚合!让我们继续我们上面的例子!
#示例1:使用多个函数进行聚合(bike .groupby(['season']) .agg(['mean', 'median']) .atemp)#示例2:使用不同的函数对不同的列进行聚合(bike .groupby(['season']) .agg(Meann=('temp', 'mean'), Mediann=('atemp', np.median)))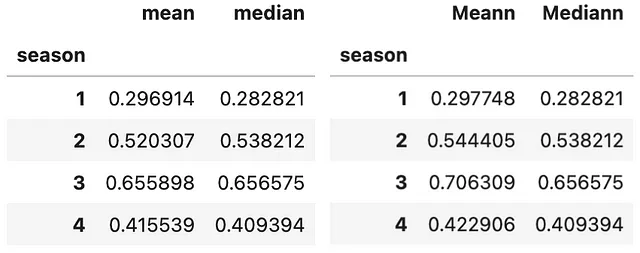
☕️ 方法 #4: .transform()
使用 .agg(),我们得到的结果与初始数据集相比,维度较低。简单来说,您的数据维度会随着行和列的减少而缩小,包含聚合信息。如果您想要总结分组数据并获得聚合值,那么 .groupby() 是解决方案。
使用 .transform(),我们也开始希望进行信息的聚合。然而,与创建信息摘要不同,我们希望输出具有与原始 DataFrame 相同的形状,而不缩小原始 DataFrame 的大小。
那些对 SQL 等数据库系统有经验的人可能会发现 .transform() 的背后思想与窗口函数类似。让我们看看 .transform() 如何在上面的示例中工作!
(bike .assign(mean_atemp_season = lambda df_: df_ .groupby(['season']) .atemp .transform(np.mean, numeric_only=True)))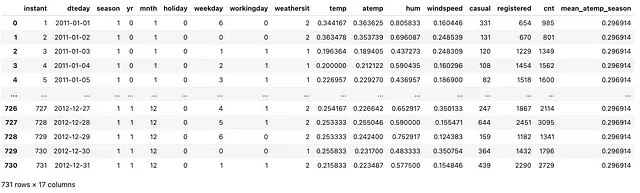
如上所示,我们创建了一个名为 mean_atemp_season 的新列,其中我们填充了 atemp 列的聚合(平均值)。因此,每当 season 为 1 时,我们都有相同的 mean_atemp_season 值。请注意,这里的重要观察是我们保留了数据集的原始维度加上一个额外的列!
☕️ 方法 #5: .pivot_table()
这是给那些痴迷于 Microsoft Excel 的人的额外福利。您可能会尝试使用 .pivot_table() 创建摘要表。当然,这种方法也可行!但是这里有一点小建议,.groupby() 更加灵活,用于更广泛的操作,超出了仅仅重塑的范围,例如过滤、转换或应用组特定的计算。
以下是如何简单使用 .pivot_table()。您在参数 values 中指定要聚合的列。接下来,使用原始 DataFrame 的一个子集指定要创建的摘要表的 索引。这可以是多个列,并且摘要表将是多级索引的 DataFrame。然后,使用未被选为索引的原始 DataFrame 的一个子集指定要创建的摘要表的 列。最后但并非最不重要的,请不要忘记指定 aggfunc!让我们快速看一下!
(bike .pivot_table(values=['temp', 'atemp'], index=['season'], columns=['workingday'], aggfunc=np.mean))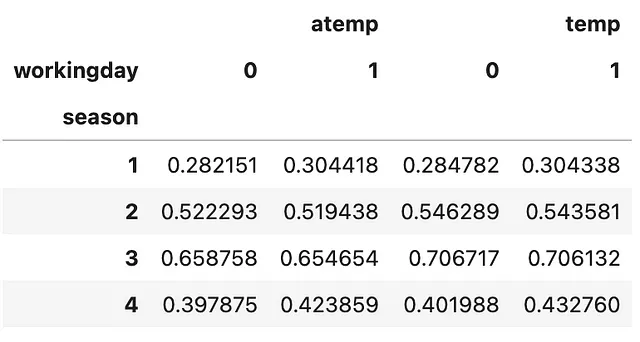
☕️ 方法 #6: .resample()
粗略地说,.resample() 方法可以视为专门用于时间序列数据的分组和聚合,其中
DataFrame 或 Series 的索引是类似日期时间的对象。
这使您能够根据不同的时间频率,如小时、日、周、月等,对数据进行分组和聚合。更一般地说,.resample() 可以接受 DateOffset、Timedelta 或 str 作为规则进行重新采样。让我们将其应用于先前的示例。
def tweak_bike(bike: pd.DataFrame) -> pd.DataFrame: return (bike .drop(columns=['instant']) .assign(dteday=lambda df_: pd.to_datetime(df_.dteday)) .set_index('dteday') )bike = tweak_bike(bike)(bike .resample('M') .temp .mean())简而言之,我们所做的是删除列instant,将dteday列从object类型转换为datetime64[ns]类型,并最终将此datetime64[ns]列设置为DataFrame的索引。
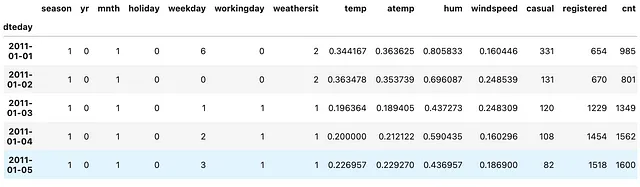
(bike .resample('M') .temp .mean())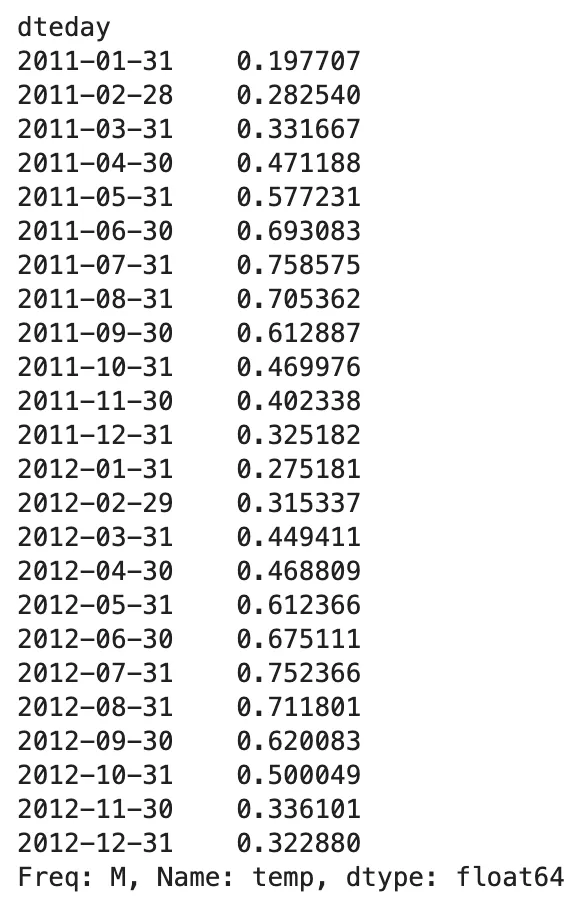
在这里,我们使用月度频率获取特征temp的描述性统计摘要(均值)。尝试使用不同的频率(如Q,2M,A等)来使用.resample()方法。
☕️ 方法 #7: .unstack()
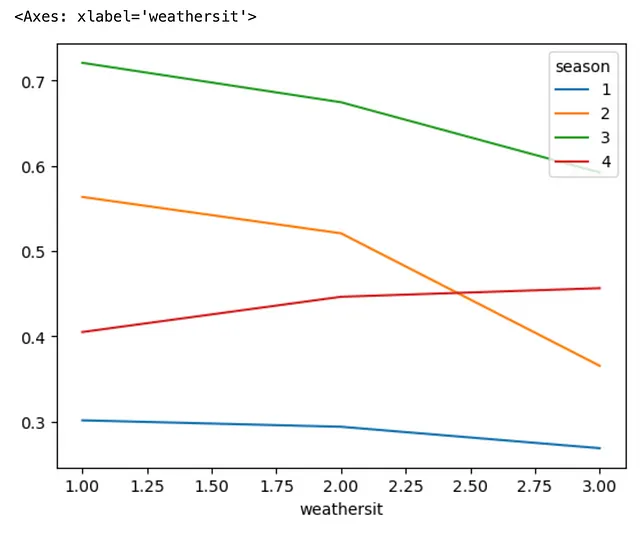
我们接近尾声了!让我向您展示为什么.unstack()既强大又有用。但在此之前,让我们回到上面的一个示例,我们想要找到不同季节和天气状况下的平均温度,方法是使用.groupby()和.agg()
(bike .groupby(['season', 'weathersit']) .agg('mean') .temp)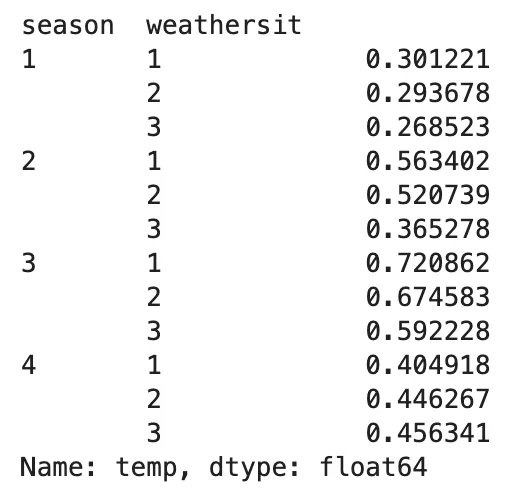
现在,让我们使用最少的代码将其可视化为线图,通过链接方法.plot和.line()到上面的代码。在幕后,Pandas利用Matplotlib绘图后端来执行绘图任务。这给出了以下结果,但我们都不想要这个结果,因为图的x轴是由MultiIndex分组的,这使得解释和意义更加困难。
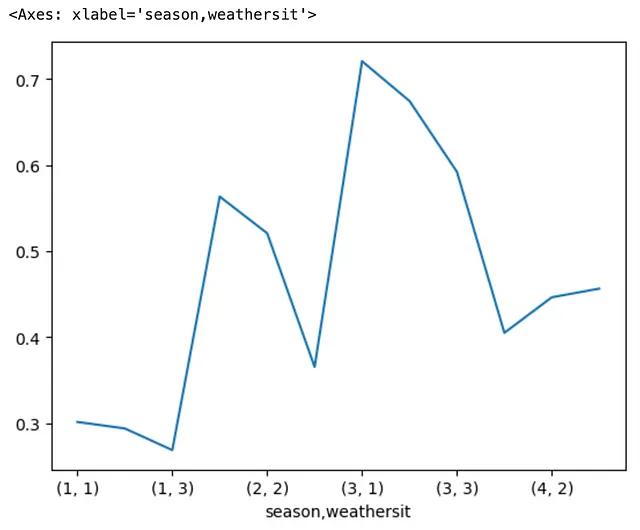
与上述图形相比,在引入.unstack()方法后,我们得到了以下图形。
(bike .groupby(['season', 'weathersit']) .agg('mean') .temp .unstack() .plot .line())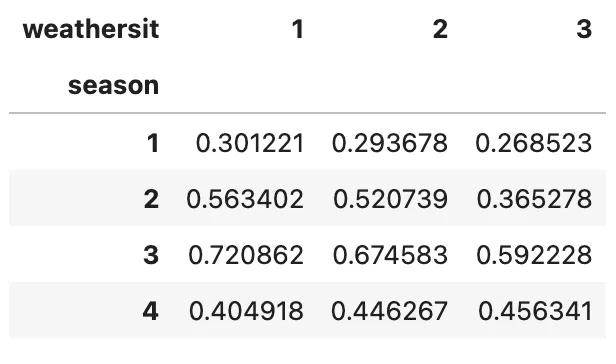
简而言之,.unstack()方法的作用是将MultiIndex DataFrame的最内层索引进行解堆叠,这在本例中是weathersit。这个所谓的解堆叠的索引成为新DataFrame的列,这允许我们绘制线图以获得更有意义的比较结果。
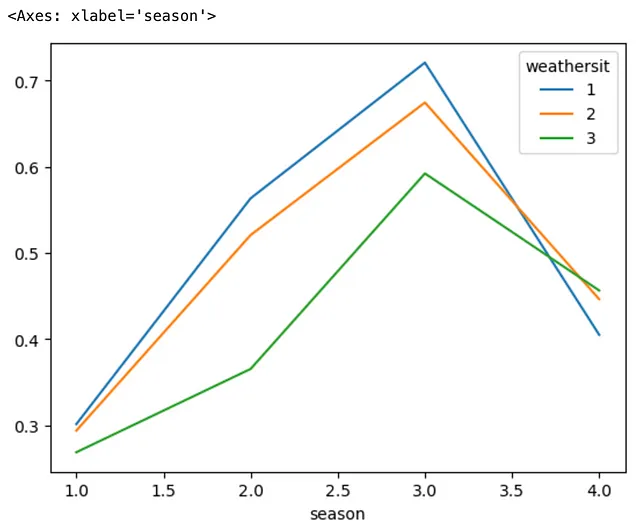
您还可以通过在.unstack()方法中指定参数level=0来解堆叠DataFrame的最外层索引,而不是最内层索引。让我们看看如何实现这一点。
(bike .groupby(['season', 'weathersit']) .agg('mean') .temp .unstack(level=0) .plot .line())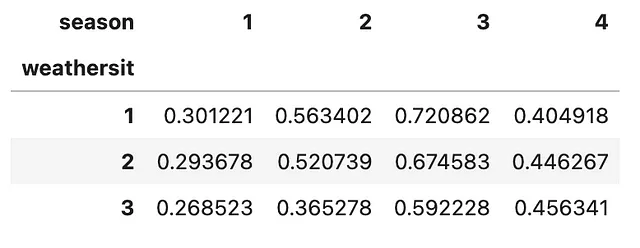
☕️ 方法 #8: .pipe()
根据我的观察,当你在网上搜索时,几乎不会看到普通人在他们的Pandas代码中实现这种方法。有一个原因是,.pipe()似乎有一种神秘的无法解释的光环,使其对初学者和中级学习者都不友好。当你查看Pandas文档²时,你会发现的简短解释是“应用预期接受Series或DataFrames的可链接函数”。我认为这个解释有点混乱,对于从未使用过链接的人来说并不真正有帮助。
简而言之,.pipe()提供给你的是使用函数继续方法链接技术的能力,在你找不到一个直接的解决方案来执行操作以返回一个DataFrame的情况下。
.pipe()方法接受一个函数,通过这个函数,你可以在链外定义一个方法,然后将该方法作为参数传递给.pipe()方法。
使用
.pipe(),你可以将DataFrame或Series作为自定义函数的第一个参数传递,并且函数将被应用于传递的对象,然后是之后指定的任何其他参数。
大多数情况下,在.pipe()方法中会看到一个一行的lambda函数,用于方便的目的(即在链接过程中的某些修改步骤之后获取最新的DataFrame)。
让我用一个简化的例子来说明。假设我们想要对以下问题进行分析:“对于2012年,相对于该年的总工作日,每个季节的工作日比例是多少?”
(bike .loc[bike.index.year == 2012] .groupby(['season']) .workingday .agg(sum) .pipe(lambda x: x.div(x.sum())))在这里,我们使用.pipe()将函数注入到我们的链接方法中。由于执行了.agg(sum)之后,我们不能继续使用.div()进行链接,下面的代码将不起作用,因为我们在链接过程中通过某些修改丢失了对最新状态的访问权。
#无法正常工作!(bike .loc[bike.index.year == 2012] .groupby(['season']) .workingday .agg(sum) .div(...))提示:如果找不到继续链接方法的方法,请考虑一下
.pipe()如何帮助!大多数情况下,它会有帮助的!
结束语
这就是低估的宝石 💎 的第一部分!它们都是我之前没有经常使用的方法,可能是因为我习惯了以“只要能工作就行!”的思维方式来强行编写代码。不幸的是,这样行不通!
只有在我花时间学习如何正确使用它们之后,它们才证明是救命的,至少可以这么说!我还要感谢Matt Harrison和他的书Effective Pandas³,它完全改变了我编写Pandas代码的方式。现在,我可以说我的代码更简洁、可读性更强,而且更有意义。
如果你从这篇文章中学到了一些有用的东西,考虑在VoAGI上关注我。每周一篇文章,让自己保持更新,走在前沿!
与我联系!
- LinkedIn 👔
- Twitter 🖊
参考资料
- Fanaee-T,Hadi. (2013). Bicycle Sharing Dataset. UCI Machine Learning Repository. https://doi.org/10.24432/C5W894.
- Pandas文档:https://pandas.pydata.org/docs/reference/frame.html
- Matt Harrison的Effective Pandas书籍:https://store.metasnake.com/effective-pandas-book






