“Transformer模型实用入门:BERT”
Introduction to Transformer Model BERT
实践教程
使用BERT构建第一个情感分析模型的实践教程
前言:本文介绍了关于给定主题的信息摘要。不应视为原始研究。本文中包含的信息和代码可能受我过去阅读或观看的各种在线文章、研究论文、书籍和开源代码的影响。
目录
- 介绍BERT
- 预训练和微调
- 实践:使用BERT进行情感分析
- 解释结果
- 结束语
在自然语言处理(NLP)中,变形金刚模型架构是一种革命性的模型,极大地增强了理解和生成文本信息的能力。
在本教程中,我们将深入探讨BERT,这是一个著名的基于变形金刚模型的模型,并提供一个实践示例,用于微调基础BERT模型进行情感分析。
介绍BERT
BERT是由Google的研究人员于2018年推出的一种强大的语言模型,它使用变形金刚架构。BERT推动了先前模型架构(如LSTM和GRU)的界限,这些模型要么是单向的,要么是顺序双向的,而BERT同时考虑了过去和未来的上下文。这是由于创新的“注意机制”,它允许模型在生成表示时权衡句子中单词的重要性。
BERT模型在以下两个NLP任务上进行了预训练:
- 掩码语言模型(MLM)
- 下一句预测(NSP)
并且通常用作各种下游NLP任务的基础模型,例如我们将在本教程中介绍的情感分析。
预训练和微调
BERT的强大之处来自于它的两步过程:
- 预训练是BERT在大量数据上进行训练的阶段。因此,它学会了在句子中预测掩码词(MLM任务)和预测一个句子是否跟随另一个句子(NSP任务)。这个阶段的输出是一个预训练的NLP模型,具有通用的对语言的“理解”
- 微调是指在特定任务上进一步训练预训练的BERT模型。模型使用预训练的参数进行初始化,并在下游任务上训练整个模型,使BERT能够将其对语言的理解微调到具体任务的细节上。
实践:使用BERT进行情感分析
完整的代码可以在GitHub上的Jupyter Notebook中找到
在这个实践练习中,我们将在IMDB电影评论数据集[4](许可证:Apache 2.0)上训练情感分析模型,该数据集标记了评论是积极的还是消极的。我们还将使用Hugging Face的transformers库加载模型。
让我们加载所有的库
import pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltfrom sklearn.metrics import confusion_matrix, roc_curve, aucfrom datasets import load_datasetfrom transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer# 设置epoch和样本数num_epochs = 10num_samples = 100 # 设置为-1以使用所有数据首先,我们需要加载数据集和模型的标记器。
# 步骤1:加载数据集和模型的标记器dataset = load_dataset('imdb')tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')接下来,我们将创建一个图表来查看积极和消极类别的分布。
# 数据探索train_df = pd.DataFrame(dataset["train"])sns.countplot(x='label', data=train_df)plt.title('类别分布')plt.show()
接下来,我们通过对文本进行标记化来预处理我们的数据集。我们使用BERT的标记器,它将文本转换为与BERT词汇表相对应的标记。
# 步骤2:预处理数据集def tokenize_function(examples): return tokenizer(examples["text"], padding="max_length", truncation=True)tokenized_datasets = dataset.map(tokenize_function, batched=True)
之后,我们准备训练和评估数据集。记住,如果您想使用所有数据,可以将num_samples变量设置为-1。
if num_samples == -1: small_train_dataset = tokenized_datasets["train"].shuffle(seed=42) small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42)else: small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(num_samples)) small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(num_samples)) 然后,我们加载预训练的BERT模型。我们将使用AutoModelForSequenceClassification类,这是一个专为分类任务设计的BERT模型。
在本教程中,我们使用了“bert-base-uncased”版本的BERT,它是在小写英文文本上训练的,适用于本教程。
# 步骤3:加载预训练模型model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)现在,我们准备定义训练参数并创建一个Trainer实例来训练我们的模型。
# 步骤4:定义训练参数training_args = TrainingArguments("test_trainer", evaluation_strategy="epoch", no_cuda=True, num_train_epochs=num_epochs)# 步骤5:创建Trainer实例并训练trainer = Trainer( model=model, args=training_args, train_dataset=small_train_dataset, eval_dataset=small_eval_dataset)trainer.train()解释结果
训练完模型后,让我们对其进行评估。我们将计算混淆矩阵和ROC曲线,以了解模型的性能。
# 步骤6:评估predictions = trainer.predict(small_eval_dataset)# 混淆矩阵cm = confusion_matrix(small_eval_dataset['label'], predictions.predictions.argmax(-1))sns.heatmap(cm, annot=True, fmt='d')plt.title('混淆矩阵')plt.show()# ROC曲线fpr, tpr, _ = roc_curve(small_eval_dataset['label'], predictions.predictions[:, 1])roc_auc = auc(fpr, tpr)plt.figure(figsize=(1.618 * 5, 5))plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC曲线 (面积 = %0.2f)' % roc_auc)plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('假阳性率')plt.ylabel('真阳性率')plt.title('接收者操作特征曲线')plt.legend(loc="lower right")plt.show()
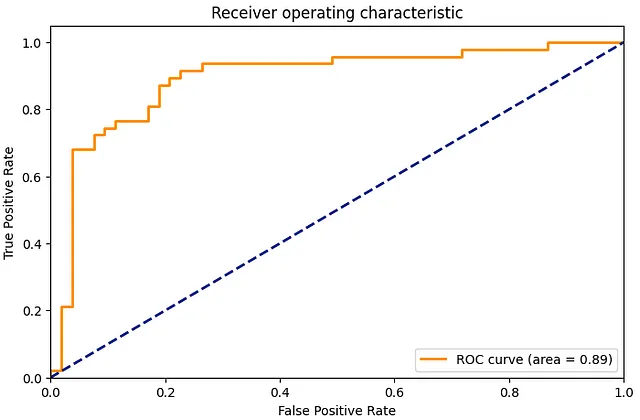
混淆矩阵提供了我们的预测与实际标签之间的详细分析,而ROC曲线则展示了在不同阈值设置下真正阳性率(敏感度)和假正性率(1 – 特异度)之间的权衡。
最后,为了看到我们的模型如何运作,让我们使用它来推断一段示例文本的情感。
# 第7步:对新样本进行推断
sample_text = "这是一部很棒的电影。我真的很喜欢它。"
sample_inputs = tokenizer(sample_text, padding="max_length", truncation=True, max_length=512, return_tensors="pt")
# 将输入移至设备(如果有GPU可用)
sample_inputs.to(training_args.device)
# 进行预测
predictions = model(**sample_inputs)
predicted_class = predictions.logits.argmax(-1).item()
if predicted_class == 1:
print("积极情绪")
else:
print("消极情绪")
结束语
通过对IMDb电影评论进行情感分析的示例,希望您对如何将BERT应用于现实世界的自然语言处理问题有了清晰的理解。我在这里提供的Python代码可以进行调整和扩展,以应对不同的任务和数据集,为更复杂和准确的语言模型铺平道路。
参考资料
[1] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805
[2] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998–6008).
[3] Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., … & Rush, A. M. (2019). Huggingface’s transformers: State-of-the-art natural language processing. ArXiv, abs/1910.03771.
[4] Lhoest, Q., Villanova del Moral, A., Jernite, Y., Thakur, A., von Platen, P., Patil, S., Chaumond, J., Drame, M., Plu, J., Tunstall, L., Davison, J., Šaško, M., Chhablani, G., Malik, B., Brandeis, S., Le Scao, T., Sanh, V., Xu, C., Patry, N., McMillan-Major, A., Schmid, P., Gugger, S., Delangue, C., Matussière, T., Debut, L., Bekman, S., Cistac, P., Goehringer, T., Mustar, V., Lagunas, F., Rush, A., & Wolf, T. (2021). Datasets: A Community Library for Natural Language Processing. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (pp. 175–184). Online and Punta Cana, Dominican Republic: Association for Computational Linguistics. Retrieved from https://aclanthology.org/2021.emnlp-demo.21
感谢阅读。如果您有任何反馈,请通过评论本文、LinkedIn消息或发送电子邮件(smhkapadia[at]gmail.com)与我联系。
如果您喜欢这篇文章,请访问我的其他文章
领域自适应:对预训练NLP模型进行微调
逐步指南:对预训练NLP模型进行微调以适应任何领域
towardsdatascience.com
自然语言处理的演变
语言模型发展的历史视角
VoAGI.com
在Python中的推荐系统:LightFM
使用LightFM在Python中构建推荐系统的逐步指南
towardsdatascience.com
评估主题模型:潜在狄利克雷分配(LDA)
逐步构建可解释的主题模型的指南
towardsdatascience.com





