“在存在代表性不足的群体中进行学习”
Learning in underrepresented groups
改变是困难的:深入研究子群体转变(ICML 2023)
让我向您介绍我们的最新工作,已被ICML 2023接受:《改变是困难的:深入研究子群体转变》。机器学习模型在许多应用中展现了巨大的潜力,但它们往往在训练数据中代表性不足的子群体上表现不佳。了解导致这种子群体转变的机制变化以及算法在不同规模的多样化转变下的泛化能力仍然是一个挑战。在这项工作中,我们旨在通过对子群体转变及其对机器学习算法的影响进行细致分析来填补这一空白。
我们首先提出了一个统一的框架,以分解和解释子群体中的常见转变。此外,我们还引入了一个包含20种最先进算法的全面基准,并在覆盖视觉、语言和医疗等领域的12个真实数据集上进行评估。通过我们的分析和基准测试,我们提供了关于子群体转变的有趣观察和对机器学习算法在这些真实转变下的泛化能力的理解。代码、数据和模型已在GitHub上开源:https://github.com/YyzHarry/SubpopBench。
背景和动机
在存在分布转变的情况下,机器学习模型经常表现出性能下降。这种转变发生在基础数据分布发生改变时(例如,训练分布与测试分布不同),导致在部署模型时性能下降。构建对这些转变具有鲁棒性的机器学习模型对于在实际世界中安全地部署这些模型至关重要。一种普遍存在的分布转变类型是子群体转变,其特征是训练和部署之间某些子群体的比例发生变化。在这种情况下,模型可能在整体性能上表现出色,但在罕见的子群体上表现不佳。
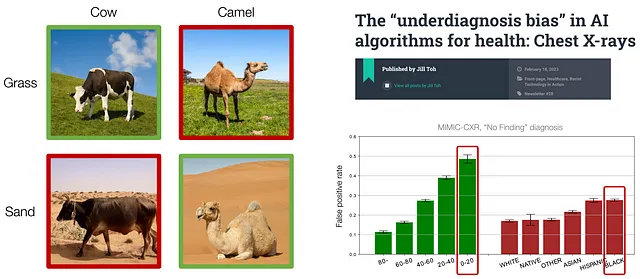
例如,在牛和骆驼分类任务中,牛通常出现在有绿草的地方,而骆驼通常出现在有黄沙的地方。然而,这种相关性是虚假的,因为牛或骆驼的存在与背景颜色无关。因此,训练模型在上述图像上表现良好,但无法泛化到训练数据中罕见的具有不同背景颜色的动物,例如沙地上的牛或草地上的骆驼。
此外,在医学诊断方面,研究发现机器学习模型在代表性不足的年龄或种族群体上通常表现较差,引发了重要的公平性关注。
所有这些转变通常被称为子群体转变,但对导致子群体转变的机制变化以及算法在这种多样化转变下的泛化能力了解甚少。那么,如何对子群体转变建模呢?
子群体转变的统一框架
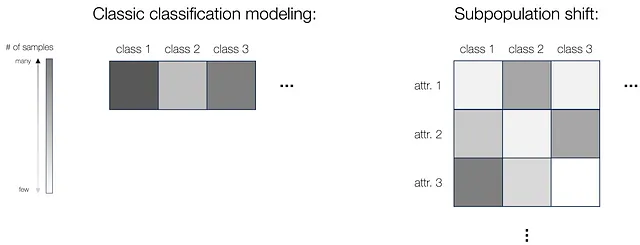
我们首先提供了子群体转变建模的统一框架。在经典分类设置中,我们有来自多个类别的训练数据(我们使用不同颜色密度来表示每个类别中的样本数量)。然而,在子群体转变中,除了类别之外还存在属性,例如牛骆驼问题中的背景颜色。在这种情况下,我们可以基于属性和标签定义离散的子群体,同一类别中不同属性的样本数量也可能不同(参见下图)。自然地,在测试模型时,类似于评估所有类别的分类设置,我们在子群体转变中测试模型的所有子群体,以确保在所有子群体中最差的性能足够好,或确保在所有群体之间具有相同的良好性能。
具体来说,为了提供一个通用的数学表达式,我们首先使用贝叶斯定理重写了分类模型。我们进一步将每个输入x视为完全由一组基本核心特征(X_core)和一系列属性(a)来描述或生成。这里,X_core表示与标签相关且支持稳健分类的基本不变组件,而属性a可能具有不一致的分布且与标签无关。因此,我们可以将这种建模集成到方程中,并将其分解为三个术语,如下所示:
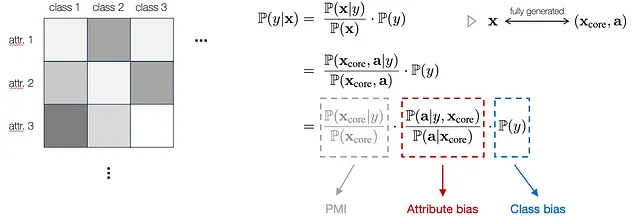
具体而言,第一个术语表示X_core和y之间的点对点互信息(PMI),它是与潜在类别标签相关的稳健指标。第二个和第三个术语分别对应于属性分布和标签分布中可能出现的偏差。这种建模解释了在子群体转变下属性和类别如何影响结果。因此,给定训练和测试分布之间的不变X_core,我们可以忽略第一个术语的变化,重点关注在子群体转变下属性和类别如何影响结果。
基于这个框架,我们正式定义和描述了四种基本类型的子群体转变:虚假相关、属性不平衡、类别不平衡和属性泛化。每种类型都构成了可能出现在子群体转变中的基本转变组件。
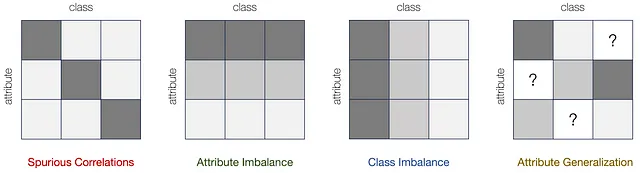
首先,当某个属性在训练中与标签y呈虚假相关,但在测试数据中不相关时,这意味着虚假相关。此外,当某些属性的采样概率远小于其他属性时,会导致属性不平衡。类别标签同样可以呈现不平衡的分布,导致对少数类别的偏好较低。这将导致类别不平衡。最后,某些属性在训练中可能完全缺失,但在测试中对某些类别存在,这促使了属性泛化的需求。每种转变的属性/类别偏差来源以及对分类模型的影响在下表中总结如下:

这四种情况构成了基本的转变组件,并且是解释真实数据中复杂子群体转变的重要要素。而在实践中,数据集通常同时包含多种类型的转变,而不是仅有一种。
SubpopBench:子群体转变基准测试
现在在建立了这个表达式之后,我们提出了SubpopBench,这是一个包括在12个真实数据集上评估的最先进算法的全面基准测试。特别地,这些数据集来源于各种模态和任务,包括视觉、语言和医疗应用,数据模态涵盖了自然图像、文本、临床文本和胸部X光。它们还展示了不同的转变组件。
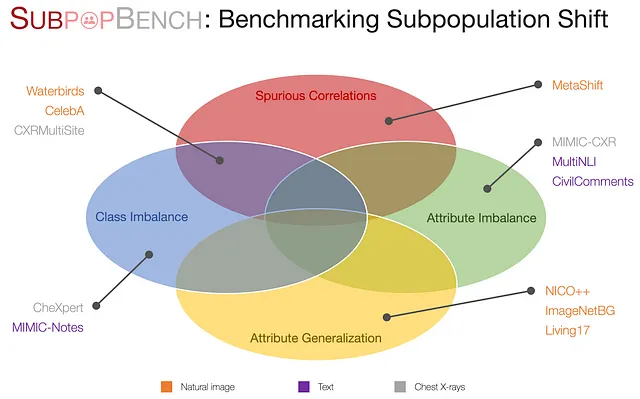

关于这个基准测试的详细信息,请参考我们的论文。通过建立基准测试并使用20种最先进的算法训练了超过10K个模型,我们揭示了未来研究领域中的有趣观察结果。
对亚群体转移进行细粒度分析
最先进算法只能改善特定类型的转移
首先,我们观察到最先进算法只能改善某些类型的转移的子群体稳健性,而不能改善其他类型。
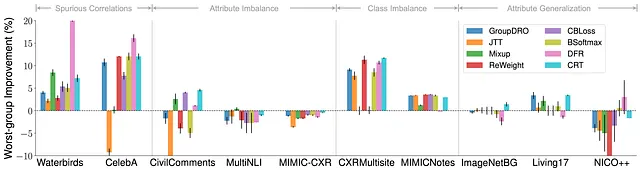
我们在此绘制了各种最先进算法相对于ERM的最差组准确率改进。对于虚假相关和类别不平衡,现有算法可以提供一致的相对于ERM的最差组增益,表明在应对这两种特定转移时取得了进展。
然而有趣的是,当涉及到属性不平衡时,在数据集之间几乎没有改进。此外,在属性泛化方面,性能甚至变得更差。
这些发现强调了目前的进展只针对特定的转移,而对于更具挑战性的转移(如AG)没有取得进展。
表示和分类器的作用
此外,我们被激发来探索表示和分类器在子群体转移中的作用。特别地,我们将整个网络分为两个部分:特征提取器f和分类器g,其中f从输入中提取潜在特征,g输出最终预测结果。我们问一个问题,表示和分类器如何影响子群体的性能?
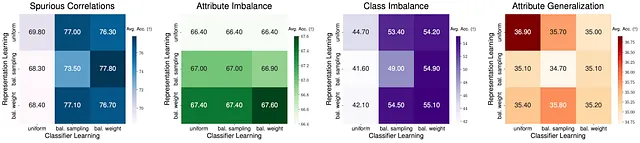
首先,给定一个基本ERM模型,当仅优化分类器学习而固定表示时,可以显著提高虚假相关和类别不平衡的性能,表明ERM学习到的表示已经足够好。然而有趣的是,改进表示学习而不是分类器可以为属性不平衡带来显著的增益,表明我们可能需要更强大的特征来处理某些转移。最后,没有分层学习方式在属性泛化下提供了性能增益。这强调了当面对不同类型的转移时,需要考虑模型流程设计。
关于模型选择和属性可用性
此外,我们观察到模型选择和属性可用性对子群体转移评估有很大影响。
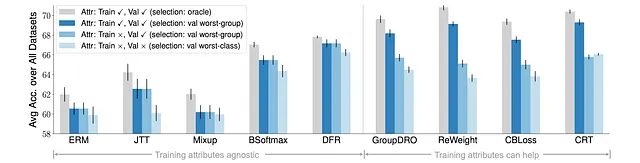
具体而言,当逐渐删除训练和/或验证数据中的属性标注时,所有算法都经历了显著的性能下降,尤其是当训练和验证数据中没有可用属性时。
这表明获得属性的访问在获得合理的子群体转移性能方面仍起着重要作用,并且未来的算法应该考虑更现实的场景来进行模型选择和属性可用性。
超越最差组准确率的指标
最后,我们揭示了评估指标之间的基本权衡。最差组准确率,或WGA,在子群体评估中被认为是金标准。然而,改善WGA是否总能提高其他有意义的指标?

首先,我们展示了改进WGA(子群体权重分配)可以导致某些指标(例如调整准确性)的改进性能。然而,如果我们进一步考虑最坏情况下的精确度,令人惊讶的是它与WGA呈现出非常强的负线性相关性。这揭示了在子群体转移中仅使用WGA作为评估模型性能的唯一指标的基本局限性:一个性能良好且具有较高WGA的模型可能具有较低的最坏类别精确度,这在关键应用(如医学诊断)中尤其令人担忧。
我们的观察强调了在子群体转移中需要更多现实和更广泛的评估指标。我们在论文中还展示了许多与WGA呈反相关的其他指标。
结束语
总结一下本文,我们系统地调查了子群体转移问题,形式化了一个统一的框架来定义和量化不同类型的子群体转移,并在真实世界数据中建立了一个全面的基准。我们的基准包括20个最先进的方法和12个不同领域的真实世界数据集。基于超过10K个训练模型,我们揭示了子群体转移中有意思的特性,这对未来的研究具有影响。我们希望我们的基准和发现能够促进现实和严格的评估,并激发子群体转移领域的新进展。最后,我附上了我们论文的几个相关链接;感谢阅读!
代码: https://github.com/YyzHarry/SubpopBench
项目页面: https://subpopbench.csail.mit.edu/
演讲: https://www.youtube.com/watch?v=WiSrCWAAUNI






