遇见自动推理和工具使用(ART):一个使用冻结的大型语言模型(LLMs)的框架,可以快速生成推理程序的中间阶段
遇见自动推理和工具使用(ART)框架:使用冻结的大型语言模型(LLMs),快速生成推理程序的中间阶段


大型语言模型可以通过在上下文学习中提供一些演示和实际语言指令来迅速适应新任务。这样可以避免托管LLM或标注大型数据集,但在多步推理、数学、获取最新信息和其他方面存在重大性能问题。最近的研究建议给LLM提供工具来促进更复杂的推理阶段,或者要求其模拟多步推理的推理链,以缓解这些限制。然而,将链式推理和工具使用的成熟方法应用于新的活动和工具是具有挑战性的;这需要针对特定活动或工具进行微调或提示工程。
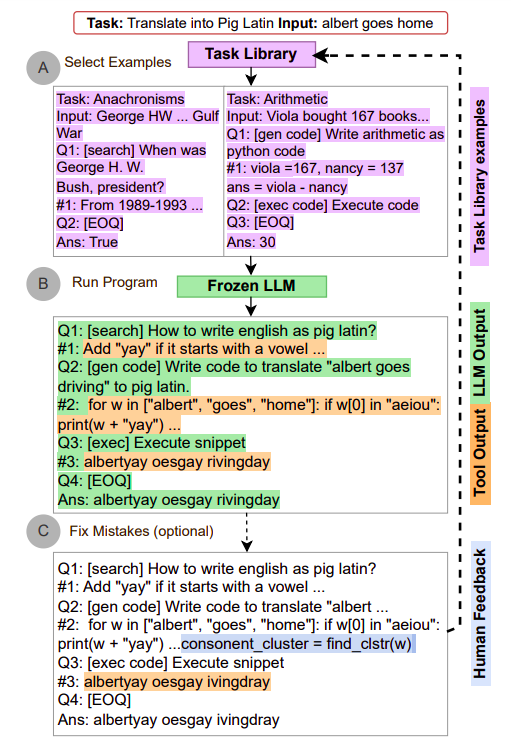
本研究介绍了来自华盛顿大学、微软、Meta、加利福尼亚大学和Allen人工智能研究所的研究人员开发的自动推理和工具使用(ART)框架。该框架可自动为新任务创建分解(多步推理),并从任务库中提取类似任务的示例,以允许少量示例的分解和工具使用。这些示例使用灵活但结构化的查询语言,可以轻松阅读中间阶段,暂停创建以使用外部工具,并在这些工具的输出包含后重新启动(图1)。此外,该框架在每个阶段选择并使用最合适的工具(如搜索引擎和代码执行)。
LLM从ART接收关于如何分解各种相关活动实例以及如何从工具库中选择和使用任何工具的演示。这有助于模型从示例中推广到分解新任务,并在工作中使用适当的工具,零样本。此外,用户可以根据需要更新任务和工具库,并添加最新的示例以纠正逻辑链中的任何错误或添加新的工具(例如,针对手头任务)。
他们为15个BigBench任务创建了一个任务库,并在19个BigBench测试任务、6个MMLU任务以及相关工具使用研究(SQUAD、TriviaQA、SVAMP、MAWPS)中的多个任务上对ART进行了测试。在32个BigBench问题中,ART的性能通常比计算机创建的CoT推理链高出22个百分点以上。当允许使用工具时,测试任务的性能平均提高了约12.3个百分点。
平均而言,ART在BigBench和MMLU任务上的直接少量示例提示性能上超过10.8个百分点。在要求数学和算法推理的未知任务上,ART的性能比直接少量示例提示提高了12.5%,并且比已知的GPT3结果(包括分解和工具使用的监督)提高了6.1个百分点。通过使用新的示例更新任务和工具库,可以进行人机交互,并改进推理过程,从而极大地简化了通过最少的人工输入提高任何给定任务性能的过程。在给予额外人工反馈的情况下,ART在12个测试任务中的性能平均超过GPT3已知结果的20个百分点以上。






