使用LLMs增强亚马逊Lex的对话式FAQ功能
Enhancing Amazon Lex's conversational FAQ feature with LLMs
Amazon Lex是一项服务,允许您快速轻松地构建对话式机器人(“聊天机器人”)、虚拟代理和交互式语音应答(IVR)系统,用于应用程序,如Amazon Connect。
人工智能(AI)和机器学习(ML)一直是亚马逊关注的焦点超过20年,许多客户在亚马逊上使用的功能都是由ML驱动的。如今,大型语言模型(LLM)正在改变开发人员和企业解决与自然语言理解(NLU)相关的历史性复杂挑战的方式。我们最近宣布了Amazon Bedrock,它使开发人员能够使用熟悉的AWS工具和功能轻松构建和扩展基于生成式人工智能的应用程序。企业面临的挑战之一是将其业务知识纳入LLM中,以提供准确和相关的响应。有效利用企业知识库时,可以使用定制的自助服务和辅助服务体验,通过提供帮助客户独立解决问题和/或增强代理的知识的信息来提供信息。今天,机器人开发人员可以通过以下几种方式改进自助服务体验,而无需使用LLM。首先,通过创建意图、示例语句和响应,从而在Amazon Lex机器人中涵盖所有预期用户问题。其次,开发人员还可以将机器人与搜索解决方案集成,该解决方案可以索引存储在各种存储库中的文档,并找到最相关的文档来回答客户的问题。这些方法是有效的,但需要开发人员资源,使得入门变得困难。
LLM提供的好处之一是能够创建相关且引人入胜的对话式自助服务体验。它们通过利用企业知识库并提供更准确和上下文相关的响应来实现这一目标。本博文介绍了一种强大的解决方案,使用检索增强生成(RAG)增强Amazon Lex的基于LLM的FAQ功能。我们将介绍如何使用RAG方法根据您的公司数据源增强Amazon Lex FAQ响应。此外,我们还将演示Amazon Lex与LlamaIndex的集成,LlamaIndex是一个开源数据框架,为机器人开发人员提供知识源和格式的灵活性。当机器人开发人员在使用LlamaIndex进行LLM集成方面获得信心后,他们可以进一步扩展Amazon Lex的能力。他们还可以使用企业搜索服务,如与Amazon Lex本地集成的Amazon Kendra。
在这个解决方案中,我们展示了使用基于LLM的RAG增强的Amazon Lex聊天机器人的实际应用。我们以Zappos客户支持用例作为示例,演示了这个解决方案的有效性,该解决方案通过增强的FAQ体验(使用LLM),而不是将用户重定向到回退(默认,不使用LLM)。
解决方案概述
RAG结合了传统的基于检索和基于生成的问答系统的优势。该方法利用大型语言模型(如Amazon Titan或开源模型(例如Falcon))在检索系统中执行生成任务。它还更有效、更高效地考虑存储文档的语义上下文。
RAG从初始检索步骤开始,根据用户的查询检索相关文档。然后,它使用语言模型通过考虑检索到的文档和原始查询来生成响应。通过将RAG集成到Amazon Lex中,我们可以为用户查询提供准确和全面的答案,从而实现更具吸引力和满意度的用户体验。
RAG方法需要进行文档摄取,以便创建嵌入来实现基于LLM的搜索。以下图示显示了摄取过程如何创建嵌入,然后聊天机器人在回退时使用这些嵌入来回答客户的问题。
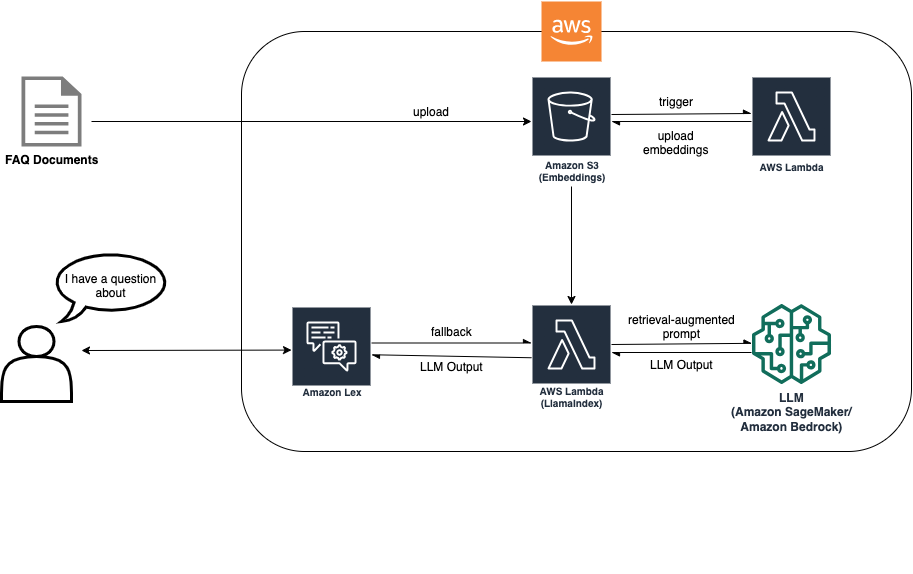
通过这个解决方案架构,您应该选择最适合您的用例的LLM。它还提供了Amazon Bedrock(有限预览版)和托管在Amazon SageMaker JumpStart上的模型之间的推断端点选择,提供了额外的LLM灵活性。
文档被上传到Amazon Simple Storage Service(Amazon S3)存储桶。S3存储桶上附加了一个事件监听器,当存储桶发生更改时调用AWS Lambda函数。事件监听器摄取新文档,并将嵌入放置在另一个S3存储桶中。然后RAG实现中的Amazon Lex机器人在回退意图期间使用这些嵌入来回答客户的问题。下图显示了在Lex中如何使用LLM和RAG增强FAQ机器人的架构。
让我们探索如何将基于LlamaIndex的RAG集成到Amazon Lex机器人中。我们提供代码示例和AWS Cloud Development Kit(AWS CDK)导入,以帮助您设置集成。您可以在我们的GitHub存储库中找到代码示例。以下各节提供了逐步指南,帮助您设置环境并部署必要的资源。
RAG 如何与 Amazon Lex 协同工作
RAG 的流程是一个迭代的过程,其中检索器组件检索相关段落,问题和段落帮助构建提示,生成组件生成响应。这种检索和生成技术的结合使得 RAG 模型能够充分利用两种方法的优势,提供准确和上下文相关的用户问题答案。该工作流提供以下功能:
- 检索器引擎 – RAG 模型从大型语料库中的检索器组件开始,负责检索相关文档。该组件通常使用诸如 TF-IDF 或 BM25 的信息检索技术来对可能包含给定问题答案的文档进行排序和选择。检索器扫描文档语料库并检索一组相关段落。
- 提示生成 – 在检索器确定相关段落之后,RAG 模型转向提示创建。提示是问题和检索到的段落的组合,作为提示的附加上下文,用作生成器组件的输入。为了创建提示,模型通常以特定格式将问题与选定的段落进行扩充。
- 响应生成 – 由问题和相关段落组成的提示被输入到 RAG 模型的生成组件中。生成组件通常是一个能够通过提示进行推理以生成连贯和相关响应的语言模型。
- 最终响应 – 最后,RAG 模型选择最高排名的答案作为输出,并将其作为对原始问题的响应呈现。选择的答案在返回给用户之前可以进一步进行后处理或格式化。此外,如果检索结果的置信度得分较低,暗示其可能超出了分布(OOD),该解决方案还可以过滤生成的响应。
LlamaIndex:用于 LLM 基于应用程序的开源数据框架
在本文中,我们演示了基于 LlamaIndex 的 RAG 解决方案。LlamaIndex 是一个专门设计用于支持 LLM 基于应用程序的开源数据框架。它提供了一个强大且可扩展的解决方案,用于管理不同格式的文档集合。借助 LlamaIndex,机器人开发人员可以轻松地将基于 LLM 的 QA(问答)功能集成到他们的应用程序中,消除了管理针对大规模文档集合的解决方案所带来的复杂性。此外,这种方法对于较小规模的文档存储库来说也是具有成本效益的。
先决条件
您需要具备以下先决条件:
- 一个 AWS 帐户
- 具有访问以下内容的 AWS Identity and Access Management(IAM)用户和角色权限:
- Amazon Lex
- Lambda
- Amazon SageMaker
- 一个 S3 存储桶
- 安装 AWS CDK
设置开发环境
主要的第三方软件包要求是 llama_index 和 sagemaker sdk。请按照我们 GitHub 存储库的 README 中指定的命令正确设置您的环境。
部署所需资源
此步骤涉及创建 Amazon Lex 机器人、S3 存储桶和 SageMaker 终端节点。此外,您需要将代码 Docker 化到 Docker 镜像目录中,并将镜像推送到 Amazon Elastic Container Registry(Amazon ECR),以便在 Lambda 中运行。请按照我们 GitHub 存储库的 README 中指定的命令部署服务。
在此步骤中,我们演示了通过 SageMaker 深度学习容器进行 LLM 托管。根据您的计算需求调整设置:
- 模型 – 要找到符合您要求的模型,您可以探索 Hugging Face 模型中心等资源。它提供了各种模型,如 Falcon 7B 或 Flan-T5-XXL。此外,您还可以找到有关各种官方支持的模型架构的详细信息,帮助您做出明智的决策。有关不同模型类型的更多信息,请参阅优化的架构。
- 模型推理终端节点 – 定义模型的路径(例如 Falcon 7B),选择实例类型(例如 g5.4xlarge),并使用量化(例如 int-8 量化)。注意:此解决方案提供了灵活性,可以选择其他模型推理终端节点。您还可以使用 Amazon Bedrock,该产品提供对其他 LLMs(例如 Amazon Titan)的访问。注意:此解决方案提供了灵活性,可以选择其他模型推理终端节点。您还可以使用 Amazon Bedrock,该产品提供对其他 LLMs(例如 Amazon Titan)的访问。
通过LlamaIndex设置文档索引
要设置文档索引,首先需要上传文档数据。我们假设您有FAQ内容的来源,比如PDF或文本文件。
文档数据上传后,LlamaIndex系统将自动启动创建文档索引的过程。这个任务由一个Lambda函数执行,它生成索引并将其保存到S3存储桶中。
为了能够高效检索相关信息,可以使用LlamaIndex检索器查询引擎来配置文档检索器。该引擎提供了一些自定义选项,例如:
- 嵌入模型 – 您可以选择嵌入模型,比如Hugging Face嵌入。
- 置信度截断 – 指定一个置信度截断阈值来确定检索结果的质量。如果置信度分数低于此阈值,您可以选择提供超出范围的响应,表示查询超出了索引文档的范围。
测试集成
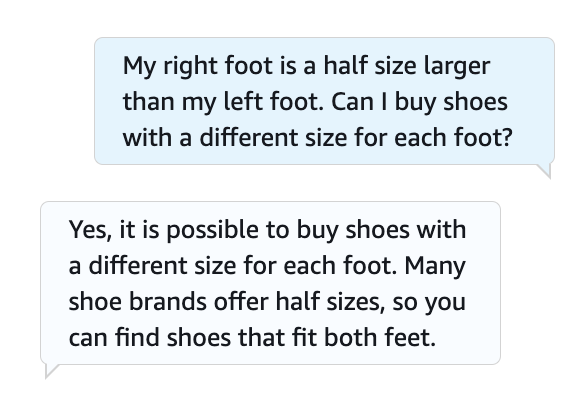
使用回退意图定义您的机器人定义,并使用Amazon Lex控制台测试FAQ请求。有关详细信息,请参阅GitHub存储库。以下屏幕截图显示了与机器人的示例对话。

提高机器人效率的提示
以下提示可能进一步提高机器人的效率:
- 索引存储 – 将索引存储在S3存储桶或具有向量数据库功能的服务中,例如Amazon OpenSearch。通过利用基于云的存储解决方案,您可以增强索引的可访问性和可扩展性,从而实现更快的检索时间和提高整体性能。此外,参考此博文中使用Amazon Kendra搜索解决方案的Amazon Lex机器人。
- 检索优化 – 尝试不同大小的嵌入模型来进行检索器。嵌入模型的选择可以显着影响您的LLM的输入需求。找到模型大小和检索性能之间的最佳平衡可以提高效率和更快的响应时间。
- 提示工程 – 尝试不同的提示格式、长度和样式,以优化机器人答案的性能和质量。
- LLM模型选择 – 为您的特定用例选择最合适的LLM模型。考虑模型大小、语言能力和与应用程序需求的兼容性等因素。选择合适的LLM模型可以确保最佳性能和系统资源的高效利用。
联系中心的对话可以从自助服务到人工互动。对于涉及Amazon Connect的人对人交互的用例,您可以使用Wisdom在多个存储库(如常见问题解答、维基、文章和处理不同客户问题的逐步说明)中搜索和查找内容。
清理
为了避免未来费用,继续删除作为本演示部署的所有资源。我们提供了一个脚本来优雅地关闭SageMaker终端节点。使用详细信息请参阅README。此外,要删除所有其他资源,您可以在与其他cdk命令相同的目录中运行cdk destroy以取消部署堆栈中的所有资源。
总结
本文讨论了使用RAG策略和LlamaIndex增强Amazon Lex的LLM-based QA功能的以下步骤:
- 安装必要的依赖项,包括LlamaIndex库
- 通过Amazon SageMaker或Amazon Bedrock(有限预览版)设置模型托管
- 通过创建索引并填充相关文档来配置LlamaIndex
- 通过修改配置并配置RAG使用LlamaIndex进行文档检索,将RAG集成到Amazon Lex中
- 通过与聊天机器人进行对话并观察其准确响应的检索和生成来测试集成
通过按照以下步骤,您可以无缝地将强大的基于LLM的问答(QA)能力和高效的文档索引功能整合到您的Amazon Lex聊天机器人中,从而实现与用户更准确、全面和上下文感知的交互。作为后续,我们还邀请您阅读我们下一篇博文,该博文探讨了使用URL摄入和LLM来增强Amazon Lex FAQ体验的方法。