一篇新的人工智能论文解释了大型语言模型作为一般模式机器可以具有的不同专业水平
A new AI paper explains the different professional levels that large language models can have as general pattern machines.


LLMs,即大型语言模型,被教导将编织在语言结构中的许多模式纳入其中。它们在机器人学中被用作高级规划器,用于遵循指令的任务,合成代表机器人策略的程序,设计奖励函数,并推广用户偏好。它们还展示了各种开箱即用的能力,例如生成推理链、解决逻辑谜题和完成数学问题。这些设置在其输入和输出中保持语义,并依赖于在文本提示中建立领域和输入输出格式的少样本上下文示例。
他们的研究的一个重要发现是,由于LLMs表示、修改和外推更抽象的非语言模式的能力,LLMs可能是更简单类型的一般模式机器。这一发现可能与常规智慧相悖。为了说明这个话题,可以考虑抽象推理语料库。这个广泛的人工智能基准包括具有暗示抽象概念的模式的2D网格集合(例如填充、计数和旋转对象)。每个任务开始于几个输入输出关系的实例,然后继续测试输入,目标是预测相关的结果。大多数基于程序合成的方法是使用特定领域语言手动构建的,或者针对基准的压缩变体或子集进行评估。
根据他们的实验,以ASCII艺术风格(见图1)作为上下文提示的LLMs可以正确预测出多达85个(800个中的一部分)问题的解决方案,超过了迄今为止一些表现最好的方法,而无需额外的模型训练或微调。另一方面,端到端的机器学习方法只能解决少量的测试问题。令人惊讶的是,他们发现这不仅适用于ASCII数字,而且当它们的替换是从词汇表中随机选择的令牌的映射时,LLMs仍然可以产生良好的答案。这些发现引发了一个有趣的可能性,即LLMs可能具有更广泛的表示和推广能力,独立于特定的考虑令牌。
- 斯坦福大学和Mila研究人员提出了Hyena:一种不需要注意力的替代方案,可以替代许多大规模语言模型的核心构建模块
- 使用LLMs增强Amazon Lex,并通过URL摄取来改善FAQ体验
- 使用LLMs增强亚马逊Lex的对话式FAQ功能

这与之前的研究结果一致,并支持地面真实标签在上下文分类中的表现优于随机或抽象标签映射的发现。在机器人学和序贯决策制定中,许多问题涉及的模式可能难以用言语精确推理,他们假设在ARC上支撑模式推理的能力可以允许在不同抽象级别上进行一般模式操作。例如,用于在桌面上空间重新排列物品的方法可以使用随机令牌表示(见图2)。另一个例子是使用递增回报优化轨迹的状态和动作令牌序列扩展。
斯坦福大学、Google DeepMind和TU Berlin的研究人员对这项研究有两个主要目标:(一)评估LLMs可能已经具备的零样本能力,以进行某种程度的一般模式操作;(二)研究这些能力如何在机器人学中使用。这些努力与通过在大量机器人数据上进行预训练或可以用于下游任务的机器人基础模型的开发是正交且互补的。这些技能显然不足以完全取代专门的算法,但对它们进行表征可以帮助确定在训练通用机器人模型时需要重点关注的最重要领域。根据他们的评估,LLMs可以归为三类:序列转换、序列完整性或序列增强(见图2)。
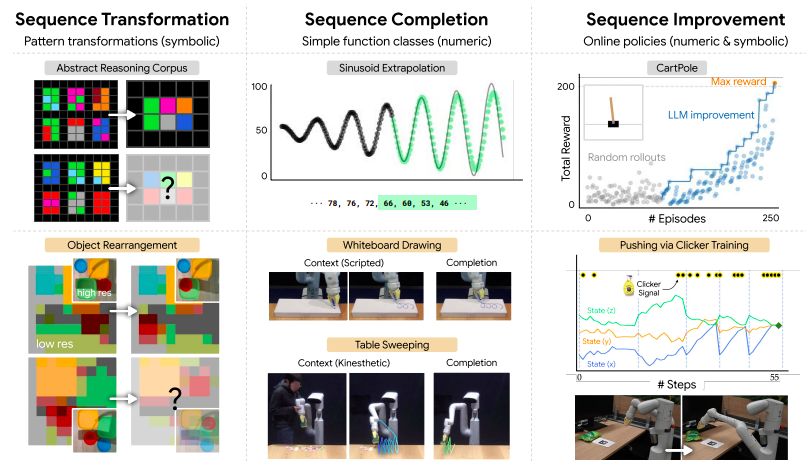
首先,他们展示了LLMs可以通过一些令牌不变性来概括一些递增复杂性的序列转换,并且他们认为这可能在需要空间思维的机器人应用中使用。接下来,他们评估了LLMs完成来自直接函数(如正弦波)的模式的能力,展示了这如何可以用于机器人活动,例如从触觉演示中延伸擦拭动作或在白板上创建模式。由于外推和上下文序列转换的组合,LLMs可以执行基本类型的序列改进。他们展示了如何使用奖励标记的轨迹上下文和在线交互,帮助基于LLM的代理学习在一个小网格中导航,找到一个稳定的CartPole控制器,并使用人机交互的“点击器”激励训练优化基本轨迹。他们已经公开了他们的代码、基准和视频。