揭开OpenAI(Python)API的奥秘
Unveiling the mystery of OpenAI (Python) API
一个完整的面向初学者友好的介绍,附带示例代码
这是一系列有关在实践中使用大型语言模型(LLMs)的第二篇文章。在这里,我将向您介绍OpenAI API的初学者友好的入门方式。这样,您就可以超越像ChatGPT这样的限制性聊天界面,并更好地利用LLMs来满足您独特的用例。下面提供了Python示例代码,并且可以在GitHub存储库中找到。
目录:
- 什么是API?
- OpenAI的(Python)API
- 入门(4个步骤)
- 示例代码
在该系列的第一篇文章中,我将“Prompt Engineering”描述为在实践中使用LLMs的最易于接触的方式。最简单(也是最受欢迎)的方法是通过像ChatGPT这样的工具来实现,这些工具提供了一种直观、无成本和无代码的方式与LLM进行交互。
LLMs的实际介绍
实际使用LLMs的3个层次
towardsdatascience.com
然而,这种易用性是有代价的。换句话说,聊天界面的限制性使其不适用于许多实际用例,例如构建自己的客户支持机器人、实时分析客户评论的情感等。
在这些情况下,我们可以进一步进行Prompt Engineering,并通过API与LLMs进行交互。我们可以通过API的一种方式来实现这一点。
1)什么是API?
应用程序编程接口(API)允许您以编程方式与远程应用程序进行交互。虽然这听起来可能很技术化和可怕,但其实思想很简单。请考虑以下类比。
想象一下,您对在萨尔瓦多度过的那个夏天吃的pupusas有强烈的渴望。不幸的是,您回到了家,不知道在哪里找到好的萨尔瓦多美食。然而,幸运的是,您有一个超级美食家的朋友,他知道城里的每家餐馆。
所以,您发送了信息给您的朋友。
“城里有好的pupusa餐馆吗?”
然后,几分钟后,您收到了回复。
“是的!Flavors of El Salvador有最好的pupusas!”
虽然这似乎与API无关,但这本质上就是它们的工作原理。您向远程应用程序发送一个请求,即给超级美食家朋友发短信。然后,远程应用程序发送回一个响应,即您朋友的回复。

API与上述类比的区别在于,您不是使用手机的短信应用程序发送请求,而是使用您喜欢的编程语言(例如Python、JavaScript、Ruby、Java等)。如果您正在开发需要某些外部信息的软件,这样做非常棒,因为信息检索可以自动化。
2)OpenAI的(Python)API
我们可以使用API与大型语言模型进行交互。其中一个热门的API是OpenAI的API,您可以使用Python将提示发送给OpenAI,并从中接收响应,而不是在ChatGPT的Web界面中键入提示。
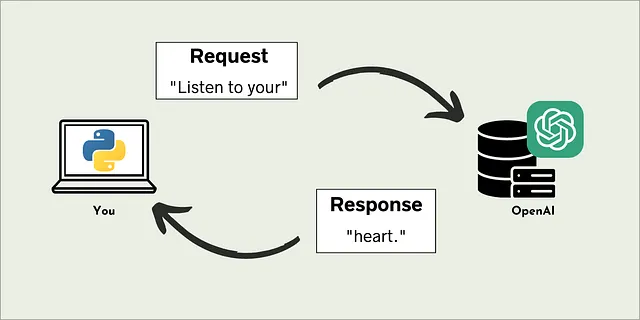
这使几乎任何人都能够访问最先进的LLMs(以及其他ML模型),而无需提供运行它们所需的计算资源。当然,缺点是OpenAI并非慈善机构。每个API调用都需要花费金钱,但稍后会详细介绍。
下面列出了API的一些显着特点(ChatGPT不具备)。
- 可自定义的系统消息(ChatGPT的设置大致如“我是ChatGPT,一个由OpenAI训练的大型语言模型,基于GPT-3.5架构。我的知识基于2021年9月之前的信息。今天是2023年7月13日。”)
- 调整输入参数,例如最大响应长度、响应数量和温度(即响应的“随机性”)。
- 在提示中包含图像和其他文件类型
- 提取有用的词嵌入用于下游任务
- 输入音频以进行转录或翻译
- 模型微调功能
OpenAI API有几个可供选择的模型。选择最佳模型取决于您的特定用例。以下是当前可用模型的列表[1]。
![2023年7月OpenAI API可用模型列表。图片由作者提供。[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*DDldra_REDf4A_bBdW0McA.png)
注意:上述每个项目都附有一组大小和成本不同的模型。请查看最新的文档以获取信息。
定价和令牌
尽管OpenAI API为开发人员提供了易于访问的SOTA ML模型,但一个明显的缺点是它需要花钱。定价是基于每个令牌的基础(不,我不是指NFT或您在游乐场使用的东西)。
令牌在LLMs的上下文中,实际上是一组表示一组单词和字符的数字。例如,“The”可以是一个令牌,“ end”(带有空格)可以是另一个令牌,“.”是另一个令牌。
因此,文本“The End.”将由3个令牌组成,例如(73,102,6)。
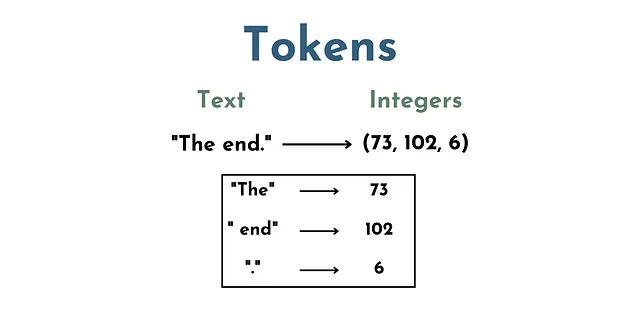
这是一个关键步骤,因为LLMs(即神经网络)不能直接“理解”文本。文本必须转换为数值表示,以便模型可以对输入进行数学运算。因此,进行令牌化步骤。
API调用的价格取决于提示中使用的令牌数量和被提示的模型。每个模型的价格可以在OpenAI的网站上找到。
3)入门(4个步骤)
现在我们对OpenAI API有了基本了解,让我们看看如何使用它。在开始编码之前,我们需要设置四个事项。
3.1)创建帐户(您将获得首三个月的5美元API信用额度)
- 访问OpenAI API概述页面,并点击右上角的“注册”以创建帐户
- 注意 – 如果您以前使用过ChatGPT,则可能已经拥有OpenAI帐户。如果是这样,请点击“登录”
3.2) 添加付款方式
- 如果您的账户已经超过3个月,或者免费的5美元API信用不足以满足您的需求,在进行API调用之前,您需要添加一种付款方式。
- 点击您的个人资料图片,并选择管理账户选项。
- 然后点击“计费”选项卡,再点击“付款方式”,添加一种付款方式。
3.3) 设置使用限制
- 接下来,我建议您设置使用限制,以免超出预算。
- 要做到这一点,进入“计费”选项卡下的“使用限制”。在这里,您可以设置“软”限制和“硬”限制。
- 如果您达到了每月的软限制,OpenAI将向您发送电子邮件通知。
- 如果您达到了硬限制,任何额外的API请求将被拒绝(因此,您不会被收取超过此限制的费用)。
3.4) 获取API秘钥
- 点击“查看API秘钥”
- 如果这是您第一次,您需要创建一个新的秘钥。要做到这一点,点击“创建新的秘钥”
- 接下来,您可以给您的秘钥起一个自定义的名称。这里我使用了“我的第一个秘钥”。
- 然后,点击“创建秘钥”
4) 示例代码:聊天补全API
完成所有设置后,我们(终于)可以进行第一次API调用了。在这里,我们将使用openai Python库,它可以轻松地将OpenAI的模型集成到您的Python代码中。您可以通过pip下载该包。以下示例代码(以及额外的代码)在本文章的GitHub仓库中可用。
关于补全API的快速说明 — OpenAI正在从自由格式提示范式转向基于聊天的API调用。根据OpenAI的一篇博客,基于聊天的范式提供了更好的响应,因为它具有结构化的提示界面,相较于之前的范式[2]。
虽然旧版OpenAI(GPT-3)模型仍然可通过“自由格式”范式使用,但较新(且更强大)的模型(例如GPT-3.5-turbo和GPT-4)仅可通过基于聊天的调用使用。
让我们从一个非常简单的API调用开始。在这里,我们将向openai.ChatCompletions.create()方法传递两个输入,即model和messages。
- model — 定义我们要使用的语言模型的名称(我们可以从本文的前面列出的模型中选择)。
- messages — 将“前置”的聊天对话设置为字典的列表。字典有两个键值对(例如{“role”: “user”, “content”: “Listen to your”})。首先,“role”定义谁在说话(例如“role”:“user”)。这可以是“user”、“assistant”或“system”。其次,“content”定义角色在说什么(例如“content”: “Listen to your”)。尽管这可能比自由格式的提示界面更具限制性,但我们可以通过输入信息的创造性使用来优化特定用例的响应(稍后详细介绍)。
以下是我们在Python中的第一个API调用。
import openaifrom sk import my_sk # 从外部文件导入秘钥import time# 导入秘钥(或直接复制粘贴到这里)openai.api_key = my_sk # 创建一个聊天补全chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "Listen to your"}])API的响应存储在chat_completion变量中。打印chat_completion,我们可以看到它是一个包含6个键值对的字典。
{'id': 'chatcmpl-7dk1Jkf5SDm2422nYRPL9x0QrlhI4', 'object': 'chat.completion', 'created': 1689706049, 'model': 'gpt-3.5-turbo-0613', 'choices': [<OpenAIObject at 0x7f9d1a862b80> JSON: { "index": 0, "message": { "role": "assistant", "content": "心。" }, "finish_reason": "停止" }], 'usage': <OpenAIObject at 0x7f9d1a862c70> JSON: { "prompt_tokens": 10, "completion_tokens": 2, "total_tokens": 12 }}下面是每个字段的含义。
- ‘Id’ = API响应的唯一ID
- ‘Object’ = 发送响应的API对象的名称
- ‘Created’ = API请求被处理的Unix时间戳
- ‘Model’ = 使用的模型的名称
- ‘Choices’ = 以JSON格式(类似于字典)格式化的模型响应
- ‘Usage’ = 以JSON格式(类似于字典)格式化的令牌计数元数据
然而,我们在这里关心的主要是‘Choices’字段,因为这里存储了模型的响应。在这个例子中,我们看到“assistant”角色的响应是“心。”
太棒了!我们完成了第一个API调用。现在让我们开始调整模型的输入参数。
max_tokens
首先,我们可以使用max_tokens输入参数设置模型响应中允许的最大令牌数。这可以根据使用情况有很多原因。在这种情况下,我只想要一个单词的响应,所以我将它设置为1个令牌。
# 设置最大令牌数# 创建聊天完成chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "听你的"}], max_tokens = 1)# 打印聊天完成print(chat_completion.choices[0].message.content)"""输出:>>> 心。"""n
接下来,我们可以设置我们想要从模型接收的响应数量。同样,这可以根据使用情况有很多原因。例如,如果我们想生成一组响应,然后从中选择我们最喜欢的一个。
# 设置完成数# 创建聊天完成chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "听你的"}], max_tokens = 2, n=5)# 打印聊天完成for i in range(len(chat_completion.choices)): print(chat_completion.choices[i].message.content)"""输出:>>> 心。>>> 心和>>> 心。>>>>>> 心,>>>>>> 心,"""注意,并不是所有的完成都相同。这可能是一个好事或者一个坏事,这取决于使用情况(例如,创意用例与流程自动化用例)。因此,根据给定的提示调整聊天完成的多样性可能是有优势的。
temperature
事实证明,我们可以通过调整温度参数来实现这一点。简单地说,这个参数调整了聊天完成的“随机性”。该参数的值范围从0到2,其中0使完成更可预测,而2使完成更不可预测[3]。
从概念上讲,我们可以认为temp=0将默认为最有可能的下一个单词,而temp=2将启用相对不太可能的完成。让我们看看这是什么样子。
# 温度=0# 创建一个聊天完成chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "听你的"}], max_tokens = 2, n=5, temperature=0)# 打印聊天完成for i in range(len(chat_completion.choices)): print(chat_completion.choices[i].message.content)"""输出:>>> 心.>>> 心.>>> 心.>>> 心.>>> 心."""如预期,当温度=0时,所有5个完成的结果都是相同的,产生了“非常可能”的内容。现在让我们看看当我们增加温度时会发生什么。
# 温度=2# 创建一个聊天完成chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "听你的"}], max_tokens = 2, n=5, temperature=2)# 打印聊天完成for i in range(len(chat_completion.choices)): print(chat_completion.choices[i].message.content)"""输出:>>> 判断>>> 建议>>> .内在意识>>> 心.>>>>>> ging ist"""同样,如预期,当温度为2时,聊天完成的结果更加多样化和“离经叛道”。
消息角色:歌词补全助手
最后,我们可以利用这种基于聊天的提示范式中的不同角色来进一步调整语言模型的回答。
前面提到,我们可以在提示中包含来自3个不同角色的内容:系统(system)、用户(user)和助手(assistant)。 系统(system)消息设置了模型完成的上下文(或任务),例如“你是一个友善的聊天机器人,不想毁灭所有人类”或“将用户提示总结为最多10个单词”。
用户(user)和助手(assistant)消息可以用至少两种方式使用。 一种方式是用于上下文学习的示例生成,另一种方式是用于实时聊天机器人的存储和更新对话历史。在这里,我们将同时使用这两种方式来创建一个歌词补全助手。
我们首先制作系统消息:“我是 Roxette 歌词补全助手。给出一行歌词,我将提供歌曲中的下一行。”然后,提供两个用户和助手消息的示例。接着是与之前示例中使用的相同的用户提示,即“听你的”。
以下是代码示例。
# 带有系统消息和2个任务示例的初始提示messages_list = [{"role":"system", "content": "我是 Roxette 歌词补全助手。给出一行歌词,我将提供歌曲中的下一行。"}, {"role":"user", "content": "我知道你微笑后的某种东西"}, {"role":"assistant", "content": "我从你眼神中感受到一种想法,是的"}, {"role":"user", "content": "你建立了一段爱情但这段爱情破裂了"}, {"role":"assistant", "content": "你的小天堂变得太黑"}, {"role":"user", "content": "听你的"}]# 顺序生成4个聊天完成for i in range(4): # 创建一个聊天完成 chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages_list, max_tokens = 15, n=1, temperature=0) # 打印聊天完成 print(chat_completion.choices[0].message.content) new_message = {"role":"assistant", "content":chat_completion.choices[0].message.content} # 将新消息添加到消息列表 messages_list.append(new_message) time.sleep(0.1)"""输出:>>> 当他呼唤你时的心>>> 听你的心,没有别的你能做的>>> 我不知道你要去哪里,也不知道为什么>>> 但在告别他之前,听你的心"""将输出与瑞典音乐组合Roxette的实际歌词进行比较,我们可以看到它们完全匹配。这是因为我们为模型提供了所有不同的输入。
要了解当我们“调高温度”时的效果,请查看GitHub上的附加代码。(警告:它会变得奇怪)
结论
在这里,我提供了一个适合初学者的OpenAI Python API指南,附带示例代码。使用OpenAI的API的最大优势是您可以使用强大的LLM而不必担心计算资源的配置。然而,缺点是API调用需要付费,而且与第三方(OpenAI)共享某些类型的数据可能存在安全问题。
为了避免这些缺点,我们可以转向开源LLM解决方案。这将是本系列下一篇文章的重点,我们将探索Hugging Face Transformers库。
资源
联系方式:我的网站 | 预约通话 | 问我任何问题
社交媒体:YouTube 🎥 | LinkedIn | Twitter
支持:成为会员⭐️ | 请我喝咖啡☕️
数据企业家
为数据领域的企业家提供一个社区。👉 加入Discord!
VoAGI.com
[1] OpenAI模型文档
[2] GPT-4可用性和完成API废弃
[3] 温度定义来自API参考



.jpg)


