概率关系的反直觉性质
Probabilistic counterintuitive nature
如果y可以被估计为x的线性函数,并不意味着x也可以被估计为y的线性函数

考虑两个实值变量x和y,例如父亲的身高和儿子的身高。统计回归分析的核心问题是通过了解x来猜测y,例如根据父亲的身高猜测儿子的身高¹。
线性回归的思想是使用x的线性函数作为对y的猜测。形式上,这意味着将ŷ(x) = α₁x + α₀作为我们的猜测,并通过最小化y和ŷ之间的均方误差来找到α₀和α₁。现在,假设我们使用了一个巨大的数据集,并找到了α₀和α₁的最佳值,因此我们知道如何基于x找到y的最佳估计。我们如何使用这些最佳的α₀和α₁的值来基于y找到关于x的猜测x̂(y)呢?例如,如果我们总是知道基于儿子的身高的最佳猜测,那么基于儿子的身高,我们对父亲的身高会有什么猜测?
这些问题是“我们如何使用ŷ(x)找到x̂(y)?”的特殊情况。尽管听起来可能很平凡,但这个问题似乎很难解决。在本文中,我研究了确定性和概率性环境中ŷ(x)和x̂(y)之间的联系,并展示了在确定性环境中关于ŷ(x)和x̂(y)如何相互关联的直觉不能推广到概率性环境。
问题的正式陈述
确定性环境
确定性环境是指(i)没有随机性和(ii)每个x的值总是对应于相同的y的情况。形式上,在这些环境中,我写作y = f(x),其中f: R → R是某个函数。在这种情况下,x完全确定y(即没有随机性或噪声),则ŷ(x)的最佳选择是f(x)本身。例如,如果儿子的身高总是父亲身高的1.05倍(暂且忽略这个例子的不可能性!),那么我们关于儿子身高的最佳猜测就是将父亲的身高乘以1.05。
如果f是一个可逆函数,则x̂(y)的最佳选择等于f的反函数。在上述例子中,这意味着关于父亲身高的最佳猜测总是儿子身高除以1.05。因此,在确定性情况下,ŷ(x)和x̂(y)之间的关联是直接的,并且可以简化为找到函数f及其反函数。
概率性环境
在概率性环境中,x和y是随机变量X和Y的样本。在这种情况下,如果一个x的值可以对应于多个y的值,为了最小化均方误差,ŷ(x)的最佳选择是条件期望E[Y|X=x] — 见注释²。简单来说,这意味着如果你使用一个非常强大的神经网络来预测给定x的y(使用足够大的数据集),那么你的网络将收敛到E[Y|X=x]。
同样,x̂(y)的最佳选择是E[X|Y=y] — 如果你训练你的非常强大的网络来预测给定y的x,那么它原则上会收敛到E[X|Y=y]。因此,在概率性环境中,ŷ(x)与x̂(y)的关联问题可以重新表述为条件期望E[Y|X=x]和E[X|Y=y]如何相互关联。
本文的目标
为了简化问题,我将重点放在线性关系上,即在ŷ(x)对x是线性的情况下。线性确定性关系具有线性逆关系,意味着y = αx(其中α≠0)意味着x = βy,其中β = 1/α — 见脚注³。与确定性关系y = αx相对应的概率线性关系是
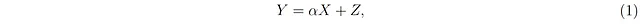
其中Z是一个额外的随机变量,通常被称为“噪声”或“误差项”,其条件平均值被假设为零,即对于所有的x,E[Z|X=x] = 0;请注意,我们并不总是假设Z与X相互独立。使用方程1,给定X=x的条件下,Y的条件期望是(见脚注⁴)

方程2说明了条件期望ŷ(x)在x上是线性的,因此它可以被看作是线性确定性关系y = αx的概率对应物。
在本文的其余部分,我将提出两个问题:
- 方程2是否意味着x̂(y) := E[X|Y=y] = βy,其中β≠0?换句话说,方程2中的线性关系是否有线性逆关系?
- 如果确实存在x̂(y) = βy,则我们是否可以像确定性情况下一样写成β = 1/α?
我将使用两个反例来展示,尽管听起来可能违反直觉,但两个问题的答案都是否定的!
例子1:当β不是α的逆时
作为第一个例子,让我考虑线性回归问题的最典型设置,总结如下三个假设(除了方程1;参见图1A进行可视化):
- 误差项Z与X相互独立。
- X具有均值为零、方差为1的高斯分布。
- Z具有均值为零、方差为σ²的高斯分布。
通过几行代数运算,很容易证明这些假设意味着Y服从均值为零、方差为α² + σ²的高斯分布。此外,这些假设还意味着X和Y联合服从均值为零、协方差矩阵为
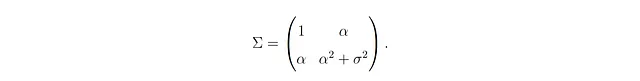
由于我们有X和Y的完整联合分布,我们可以推导出它们的条件期望(见脚注⁵):
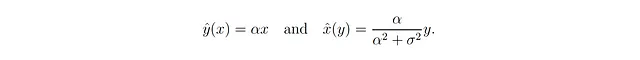
因此,根据我们第一个示例的假设,方程式2具有形式为x̂(y) = βy的线性逆,但β不等于其确定性对应物1/α —— 除非我们有σ = 0,这与确定性情况等价!
这个结果表明,我们对确定性线性关系的直觉无法推广到概率线性关系。为了更清楚地看到这个结果所暗示的真正荒谬之处,让我们先考虑α = 0.5的确定性设置(σ = 0;图2A和2B中的蓝色曲线):
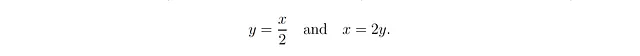
这意味着,给定一个x的值,y的值是x的一半;而给定一个y的值,x的值是y的两倍,这似乎是直觉的。重要的是,我们始终有x < y。现在,让我们再次考虑α = 0.5,但这次是在σ² = 3/4的情况下(图2A和2B中的红色曲线)。这个噪声方差的选择意味着β = α = 0.5,结果为
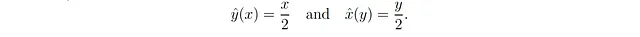
这意味着,给定一个x的值,我们对y的估计是x的一半,然而,给定一个y的值,我们对x的估计也是y的一半!奇怪的是,我们始终有x̂(y) < y 和 ŷ(x) < x —— 如果这些变量是确定性的,这是不可能的。看起来违反直觉的是,方程式1可以重写为
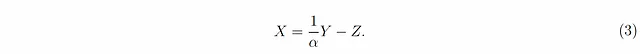
然而,这只能意味着(与方程式2相反)
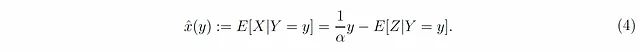
问题在于,虽然我们设计上有E[Z|X=x]=0,但我们对E[Z|Y=y]及其对y的依赖性无法做出任何结论!换句话说,使x̂(y)与y/α不同的是观测到的y还包含有关误差Z的信息,例如,如果我们观察到一个非常大的y值,那么很可能意味着误差Z也具有较大的值,在估计X时应该考虑到这一点。
这是对看似矛盾陈述的简单解释,比如“高个子父亲的儿子(平均而言)也高但不及父亲那样高,而与此同时,高个子儿子的父亲(平均而言)也高但不及儿子那样高”!
总之,我们的示例1表明,即使概率线性关系ŷ(x) = αx具有形式为x̂(y) = βy的线性逆函数,斜率β并不一定等于其确定性对应物1/α。
示例2:当x̂(y)是非线性的
只有当公式4中的E[Z|Y=y]也是y的线性函数时,才有可能存在形式为x̂(y) = βy的逆函数。在第二个示例中,为了打破这个条件,我对示例1进行了小的修改!
特别地,我假设误差项Z的方差取决于随机变量X —— 而不是示例1中的假设1。形式上,我假设(除了公式1;参见图1B进行可视化):
- X服从均值为零、方差为1的高斯分布(与示例1中的假设2相同)。
- 给定X=x,误差Z服从均值为零、方差σ² = 0.01 + 1/(1 + 2x²)的高斯分布。
这些假设实际上意味着,在给定X=x的情况下,随机变量Y服从均值为αx、方差为0.01 + 1/(1 + 2x²)的高斯分布(参见图1B)。与示例1中X和Y的联合分布是高斯分布不同,示例2中X和Y的联合分布没有一个优雅的形式(参见图1C)。然而,我们仍然可以使用贝叶斯规则,并找到相对丑陋的给定Y=y时X=x的条件密度(参见图3中一些通过数值计算得到的示例):

其中花括号N表示高斯分布的概率密度。
然后,我们可以使用数值方法评估给定y和α的条件期望
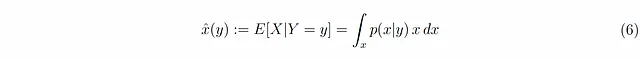
。图2C展示了α = 0.5时x̂(y)作为y的函数。尽管听起来可能不符合直觉,这种逆关系是高度非线性的——这是由图1B中显示的x相关误差方差所导致的结果。这表明,虽然y可以被很好地估计为x的线性函数,但并不意味着x也可以被很好地估计为y的线性函数。这是因为在超越类似于示例1中的标准假设时,公式4中的E[Z|Y=y]可以对y具有任何奇怪的函数依赖关系。
总结:我们的示例2表明,概率线性关系ŷ(x) = αx并不一定具有形式为x̂(y) = βy的线性反函数。重要的是,x̂(y)和y之间的反函数关系取决于误差项Z的特性。
结论
在我们的教育过程中,我们大多数人都建立了对确定性关系的丰富直觉,这是基于我们在微积分、分析等中看到的所有很酷的结果。然而,当我们思考概率关系时,了解这种直觉的局限性并且不应该信任它是至关重要的。特别是,示例1和示例2表明,即使是非常简单的概率关系也可能与我们的直觉相悖。
致谢
我感谢Johanni Brea、Mohammad Tinati、Martin Barry、Guillaume Bellec、Flavio Martinelli和Ariane Delrocq对本文内容的有用讨论和宝贵反馈。
代码:
所有分析的代码(使用Julia语言)可以在此处找到。
脚注:
¹ 有兴趣的读者可以在Towards Data Science中查看“父亲的身高如何影响儿子的身高”对这个问题的易懂处理。
² 更多细节请参见维基百科上的“最小均方误差”页面。
³ 不失一般性,我们总是假设x和y的平均值为零。因此,在父亲和儿子身高的示例中,x和y分别表示其身高与父亲和儿子平均身高的差值。
⁴ 方程1和方程2之间的关系是可逆的,即,如果只有方程2是X和Y的约束条件,那么我们总是可以写出Y为具有满足E[Z|X=x] = 0的随机变量Z的方程1。
⁵ 更多细节请参见维基百科上“多元正态分布”页面的“双变量条件期望”部分。




.jpg)

