遇见 Skill-it:一种基于数据驱动的技能框架,用于理解和训练语言模型
Skill-it 一种数据驱动的技能框架,用于语言模型训练


大型语言模型(LM)在编写源代码、创作艺术作品和与人交谈方面具有非凡的能力。用于训练模型的数据使它们能够执行这些任务。通过增强这些训练数据,某些技能可以自然解锁。鉴于训练令牌数量有限,如何从庞大的语料库中选择数据以实现这些能力尚不清楚,因为大多数现有的LM数据选择算法依赖于启发式方法来过滤和组合各种数据集。他们需要一个形式化的框架来描述数据如何影响模型的能力以及如何利用这些数据来提高LM的性能。
他们从人们学习的过程中得到了启示,以创建这个框架。在教育文献中,组成学习层次结构的能力的概念是一个众所周知的主题。例如,研究发现,按特定顺序呈现数学和科学概念有助于学生更快地理解它们。他们想知道类似的基于技能的排序是否也存在于LM的训练中。如果存在这样的排序,它们可能为数据有效训练和更深入地理解LM提供一个框架。例如,他们想知道最初在类似但更容易的任务上进行训练,比如西班牙语语法和英语问题生成,是否有助于训练西班牙语问题生成的LM。
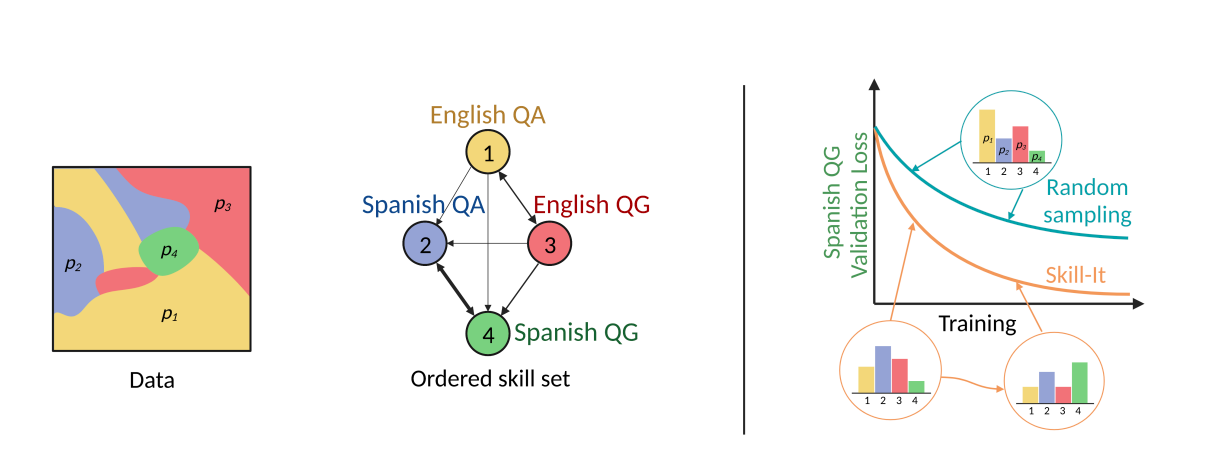
他们研究技能排序的概念是否有助于开发将数据与LM的训练和行为联系起来的框架。为了做到这一点,必须解决与数据和技能交互相关的两个问题。首先,必须使用数据来定义和测试LM技能和技能排序的操作性定义,以证明有一组能力,LM在特定顺序中学习效果最好。在他们的早期研究中,他们研究了是否语义分组的数据(如元数据属性或嵌入簇)可以充分代表一项技能并描述模型的学习过程。

例如,他们按照指令类型对Alpaca数据集进行了分区以捕捉数据的多样性。然而,他们发现基于指令类型的采样和随机采样产生的模型性能相似,这表明不是任何现有的数据分组概念都能够表征技能。为了真正增强模型训练,必须使用这些技能定义来构建样本分布。他们列出了朴素选择技术所遇到的困难,以创建一种有效学习技能的数据选择算法的标准。由于传统的随机均匀采样技术没有考虑到能力的不平衡和排序,因此无法优化学习技能。
例如,西班牙语和问题生成(QG)分别占自然指令数据集的5%和4%,而西班牙语QG仅占0.2%。技能可能在数据中分布不均,并且更复杂的技能很少见。此外,随机采样无法考虑到特定的训练顺序或技能依赖结构。更高级的策略(如课程学习)可以考虑到样本级别的排序,但不能考虑到技能或它们的依赖关系。他们的目标框架必须考虑到这些不平衡和排序问题。作为一个模型可以使用相关数据片段来学习的行为单元,他们定义了一个技能。
有序技能集是一组具有有向技能图的技能,该图既不是完整的也不是空的,如果学习该技能所需的训练时间可以通过学习先决技能来缩短,那么从先决技能到技能的边就存在(图1左、中)。使用这个操作性的定义,他们证明了人工和实际数据集中存在有序的技能集。有趣的是,这些有序的技能集揭示了快速学习一项才能需要在该技能和必要技能上进行训练,而不仅仅是该技能本身。
根据他们的观察,当模型额外学习英语QG和西班牙语时,与仅仅训练西班牙语QG相比,在总的训练步骤预算下,他们可能获得比较低的4%验证损失。然后,根据他们的理论,他们提供了两种选择数据的方法,以便语言模型更快地学习技能:技能分层采样和在线泛化技术SKILL-IT。斯坦福大学、威斯康星大学麦迪逊分校、Together AI和芝加哥大学的研究人员提出了技能分层选择方法,这是一种简单的方法,它通过均匀采样相关技能(如目标技能及其在微调中所需的技能)来解决数据集中技能分布不均匀的问题,从而明确优化学习技能。
由于技能分层采样是静态的,并且不考虑训练进程中的排序,它过度采样可能在训练过程中较早获得的能力。他们提出了SKILL-IT,一种在线数据选择技术,用于选择训练技能的组合,通过给尚未学习的技能或具有影响力的先决条件技能赋予更高的权重来解决这个问题(图1右侧)。在固定的数据预算和技能图的假设下,SKILL-IT是从在线优化问题中发展而来的,该问题针对一组评估技能最小化损失。
基于评估技能集和训练技能集之间的关联,SKILL-IT可以针对持续的预训练、微调或域外评估进行修改。它受到在线镜像下降的启发。在人工和实际数据集上,他们在两个模型规模上评估了SKILL-IT:125M和1.3B个参数。在LEGO模拟中,相对于随机选择训练数据和课程学习,他们展示了连续预训练场景下准确性提高了35.8个百分点的情况。在相同的总训练预算下,他们表明他们的算法在一组能力的组合上可以实现比仅仅在该技能上进行微调时低13.6%的损失。
他们的算法在与自然语言指令测试任务数据集中的任务类别相对应的12个评估技能中,在训练数据的随机采样和技能分层采样上可以实现11个评估技能中的最低损失,在训练技能与评估技能不完全匹配的域外设置中。最后,他们提供了一个案例研究,使用最新的RedPajama 1.2万亿标记数据集来应用他们的方法。他们持续预训练了一个30亿参数的模型,利用SKILL-IT生成的数据混合。他们发现,在具有30亿标记的数据源上,SKILL-IT在准确性方面优于均匀采样,其中使用了10亿标记。






