自监督学习和Transformer?— 解读DINO论文
Understanding the DINO paper self-supervised learning and Transformers?
DINO框架如何实现自监督学习的新SOTA!
![图片来源于原始的DINO论文[1].](https://miro.medium.com/v2/resize:fit:640/format:webp/1*TKKi9sfafVv18rI0A3aWag.png)
Transformer和自监督学习。它们之间的关系如何?
有些人热爱Transformer架构,并将其引入计算机视觉领域。其他人则不愿接受新生力量的到来。让我们来看看当你在BYOLs [2]的自蒸馏自监督学习思想基础上,插入一个Vision Transformer时会发生什么!这正是Facebook AI Research的作者在第一篇DINO [1]论文中研究的问题。当两者结合时,是否会出现一些有趣的新特性?嗯,使用Transformers的一个很酷的效果就是能够查看模型的自注意力图!
这就是上面的预告图片中我们看到的。我们可以可视化最后一层的类令牌的自注意力图,基本上可以看到模型学会了识别图像中的主要对象。模型基本上在没有任何标签的情况下学会了分割图!
我觉得这非常酷!!!
- 认识QLORA:一种高效的微调方法,可以降低内存使用量,使得在单个48GB的GPU上微调一个65B参数的模型,并保持完整的16位微调任务性能
- 加州大学伯克利分校的研究人员引入了视频预测奖励(VIPER):一种利用预训练的视频预测模型作为无动作奖励信号的强化学习算法
- PID控制器优化:一种梯度下降方法
当预测第一行的第一张图片的最终表示时,模型最关注的是鸟,当预测第二行的第一张图片时,模型最关注的是船,依此类推!对于这个船的例子,在监督训练中可能特别棘手,因为模型更倾向于学习捷径,比如也关注水,因为水和金属物体意味着船。
但在继续探索这些有趣发现之前,让我们来看看他们是如何实现所有这些的!
DINO框架
![DINO框架。来源:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*9CeO-DXXq48WDHygDBmwpg.png)
这是训练流程,也是自蒸馏家族的一部分。
我们再次有了原始的源图像,应用了两组不同的随机增强,并得到了两个不同的视图,x1和x2。我们再次有了在线网络,现在称为学生网络,还有我们的目标,现在称为教师网络,它再次是学生网络的指数移动平均值。从这里开始,事情开始变得不同。我们没有进一步的投影层,也没有预测头!如果没有预测头,我们如何防止(或减少)表示坍缩的可能性?嗯,首先,我们有了这个居中操作,可以简单地将一个偏置c添加到教师预测中。
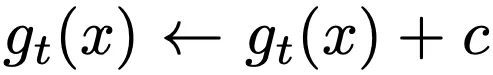
这个偏置使用批量统计信息来计算批量的均值,并且类似于指数移动平均值进行更新。
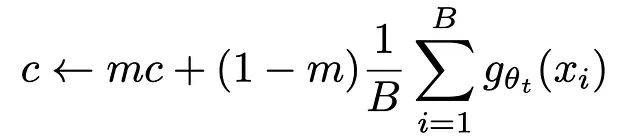
这个超参数m与EMA方程中的𝜏参数几乎相同。我们稍微调整每个批次的偏置参数c。这个居中操作可能是避免坍缩为常数函数的主要操作!居中操作可以防止某个维度主导,从而作为一种伪标签,但也鼓励坍缩为均匀分布!这就是为什么该框架在一定程度上依赖于经过加强的softmax函数,因为它具有相反的效果。
想象一下,你有一堆图片,你想教模型识别这些图片中的不同对象。现在,如果模型总是关注同一个对象,因为它最关注它,比如一只可爱的狗,那么模型只会学到关于狗的东西,而不会学到其他任何东西。居中操作就像试图公平地确保AI平等地学习所有不同的对象。就像说:“好吧,让我们将图片分成不同的组,每个组都应该平等地看待。”这样,模型将以平衡的方式学习不同的对象。该模型被鼓励学习各种特征或不同的“伪类别”,而不是专注于单一的主导特征/类别。另一方面,锐化是一种技术,用于确保在想要“分类”一个对象时,即希望沿着一个特征维度将整个特征向量强烈移动时,模型不会困惑,并且总是随机选择不同的对象,即简单地总是预测一个均匀分布。这就像确保每次模型确实趋向于选择一个对象时,它对自己的选择感到自信和确定。在将经过较少锐化的softmax函数应用于学生输出之后,最终损失是交叉熵损失。
为什么使用交叉熵而不是像BYOL中那样使用均方误差(MSE)?
![消融研究以观察管道中不同部分的效果。来源:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*0amAl9svY9FnlhQgLuiUXA.png)
如果我们看第2行,MSE居然可以在DINO中起作用,但是交叉熵(第1、3、4行)似乎更好。DINO在将进一步的预测头添加到学生网络时也能正常工作(第3行)!但是似乎并没有太多帮助。事实上,如果我们使用MSE损失,我们甚至不一定需要softmax操作。但是如果我们使用交叉熵,显然需要,因为该损失函数是定义在概率分布上的,而概率分布似乎更好!
好吧… 这是很多需要理解的内容,并且在直觉上需要建立。但是这样做希望能够展示出进行实证实验和验证哪些方法有效的重要性!
损失函数
另一个似乎更好的方法是不仅仅在所有不同视图嵌入之上使用交叉熵,而是使用一种非常特定的设置!
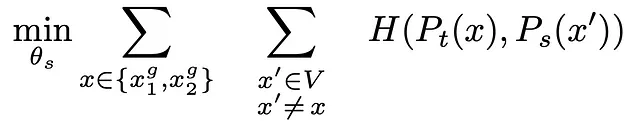
让我们看看这实际上意味着什么,并回到我们友好的小袋獾!

让我们再次生成多个视图;这次我们假设有4个视图。稍微改变它们的颜色,并进行裁剪和调整大小。现在,在裁剪时,我们希望具体有两种情况,即包含原始图像50%或更多的裁剪以及较小裁剪的情况。这些较大的裁剪称为全局裁剪,用“g”标记。
在将我们的视图分配给两个分支时,对于教师网络,我们特别只使用全局视图,而对于学生网络,我们将使用所有视图,即局部和全局裁剪。
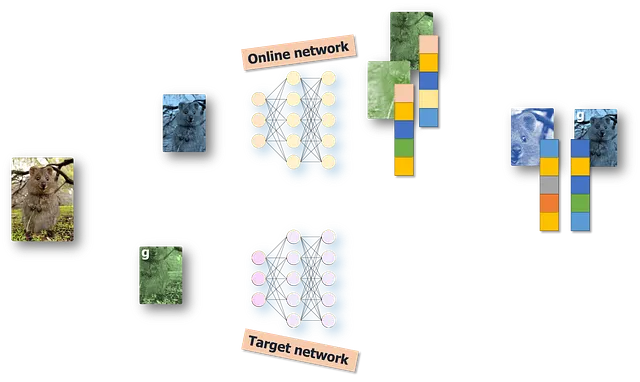
我们现在要比较的是一个全局裁剪的教师嵌入和学生网络的所有样本的所有嵌入,除了相同全局视图的嵌入。我们现在可以计算每个学生嵌入与该特定教师嵌入的交叉熵,并重复这个整个过程。就这样,我们得到了我们奇怪的交叉熵损失,它可以强制进行局部到全局的对应。
我们在SimCLR帖子中已经讨论了两种裁剪情况,其中我们有两个相邻的视图,以及这里强制的局部和全局视图的情况。显然,当学习查看较大物体的较小部分并尝试将其与其嵌入相匹配时,模型学习得更好。全局视图的嵌入具有更多信息,因此可以更好地识别对象。
建立直觉
这个假设对我来说是有道理的,前提是教师的嵌入比学生更好,并且在BYOL论文中也有这个假设,但是由于DINO的作者在实验、消融研究和建立直觉的过程中付出了很多努力,他们实际上通过观察训练过程中学生和教师网络的准确性来验证了这个假设。
![教师网络和学生网络在训练过程中的准确性。来源:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*k-QLZR3qzO7PvcbVAoiB3g.png)
老师似乎比学生更聪明,每当学生进步时,老师也会进步,因为老师是学生的更稳定版本。关键词:指数移动平均。一切都达到了一个点,老师不再有什么可以教的了,两者趋于一致。
但好吧,很酷。我们刚刚看了一下这个新颖的自我蒸馏框架,它再次与架构无关。那么,变压器在哪里?为什么它们在这个框架中特别特殊?!
让我们简单比较不同的自我监督学习框架,并插入经典的ResNet和视觉变压器。
![使用不同自我监督学习框架训练的ResNet-50和ViT模型的评估结果。来源:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*g0ZIVHQjeIegR1f01ZZQjg.png)
当观察经过训练的ResNet的验证准确率时,我们可以看到DINO框架的性能最佳,但与其他基线方法相比可以被认为是相当接近的。
然而,当用视觉变压器替换ResNet架构时,DINO释放了其潜力,并显著优于其他基线!特别是在k-NN分类的情况下。k-NN是当今自我监督学习的标准评估协议之一,但在SimCLR和BYOL开发和发布之时还不是。
唉…那时候…好像也就是2-3年前的事情…
k-NN!为什么它如此酷,它是如何工作的?你不需要进行任何微调!
显然,我们仍然需要标签,但现在我们只需将所有已标记的数据投影到我们的表示空间中以生成我们的类别聚类。

当想要对一个新的数据点进行分类,例如一张图片,我们将其通过神经网络并投影到表示空间中。然后我们只需计算k个最近邻(在本例中为3个)并进行多数表决。在这种情况下,大多数邻居属于橙色类别,所以新的图像也被分类为橙色类别。这个k是一个新的超参数(仿佛已经有足够多的超参数了),在论文中设置为11时得到最佳结果。
结果
![对线性评估和k-NN协议进行不同自我监督和监督训练方法的评估结果。来源:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*YIbAm15P96VFnKb8ZPKegA.png)
好的,很酷。这里是一个表格,展示了非常令人兴奋的结果。当只看ResNet、只看ViT以及不同架构时,DINO当然是最好的。但是,当考虑到相同大小的架构时,它仍然无法击败完全监督的模型。
很酷。但更酷的是再次深入了解并可视化注意力图。
![最后一个ViT块的前三个注意力图的可视化(来自不同的注意力头)。来源:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*v80a03EB_-09_-vqYJF6HA.png)
当查看前3个注意力头的注意力图时,我们可以看到令人印象深刻的特性!类似于CNN,其中每个卷积核负责提取特定的特征,我们可以看到不同的注意力头关注图像的不同语义区域!在第二行的第一个示例中,一个注意力头关注时钟表盘,一个关注旗帜,一个关注塔本身!或者,再往下一行的例子中,我们可以再次看到一个注意力头关注衣领,一个关注头部,一个关注斑马的白颈部。
这不是很酷吗?!
所有这些都是在没有任何标签、没有任何特定分割图的情况下学习到的!实际上,我们可以简单地将一个注意力图解释为分割输出,并使用DINO比较监督和自监督训练!
![最终层中顶部注意力头的注意力图可视化。一次是完全监督训练的模型,一次是使用DINO框架训练的模型。来源:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*uujBrRfYwA5HhbhHzKHT_A.png)
如前所述,当以自监督方式训练时,模型学会更多地关注图像中的主要对象,而不是专门为分类训练网络时。
自监督学习的学习信号更强!
在分类任务中,模型可以学会使用捷径来解决任务。当尝试将鸟的图像与鸟类匹配时,模型可以使用天空或树枝作为重要特征。最终,如果满意分类准确率,或者说优化的损失,模型实际上并不在乎它是否只看鸟,还是也看其周围的环境。而在自监督训练中,我们没有这样一个简单明了的优化任务。模型需要学会将彩色增强的局部视图与全局视图匹配。它必须学会在忽略应用于原始源图像的所有增强的同时生成嵌入。它需要学会提取的特征更加具体。
我希望这个解释有意义,尽管你的大脑可能对这些信息感到有些不知所措,特别是如果你刚刚阅读了我之前关于自监督学习的所有文章!我的意思是…在做所有这些研究后,我的大脑都炸了。而且我可能还没有掌握所有的细节!
自监督学习真的很酷、强大和有趣!但这只是表面的探索!后续论文如iBOT [3]和DINOv2 [4]使用了进一步的改进,例如遮挡图像建模,学习到的表示可以用于许多不同的下游任务!
![使用预训练的DINOv2特征提取器在不同下游任务上的定性结果。来源:[4]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*BZvLfAdQYdhzDL4qujVMhg.png)
DINOv2在iBOT基础上进行了训练和架构改进,包括正确的补丁大小、教师动量、更好的居中算法等多个微小调整。
![DINOv2对iBOT框架添加的改进列表。来源:[4]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*vlfwxvoJdSuTBMYA3EzcoA.png)
此外,DINOv2开发了一个非常复杂的数据预处理管道,生成了一个更大但经过筛选的数据集。
![来源:[4]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*FkXe2zHffRcsT8lbyqD04g.png)
自监督学习仍然是一个令人生畏的领域,有着令人眼花缭乱的方法和复杂的实现。这就是为什么Meta AI最近出版了一本长达45页的手册[5],以帮助在这个领域中进行导航。所以,如果你对这个主题感兴趣(而且既然你仍然在阅读,你可能是),我强烈推荐你阅读这篇文章。它内容很多,但读起来非常好!我希望这个系列能帮助你获得基本的理解,也能帮助你在阅读手册时更好地导航。
非常感谢你的阅读!如果你还没有,可以随时查看我的其他文章,深入了解自监督学习和最新的人工智能研究。
P.S.:如果您喜欢这篇内容和图表,您也可以关注我的YouTube频道,我会在那里发布类似的内容,但是会有更加整洁的动画效果!
参考资料
[1] 《Emerging Properties in Self-Supervised Vision Transformers》, M. Caron et. al, https://arxiv.org/abs/2104.14294
[2] 《Bootstrap your own latent: A new approach to self-supervised Learning》, J. B. Grill, F. Strub, F. Altché, C. Tallec, P. H. Richemond et al., https://arxiv.org/abs/2006.07733
[3] 《iBOT: Image BERT Pre-Training with Online Tokenizer》, J. Zhou et al., https://arxiv.org/abs/2111.07832
[4] 《DINOv2: Learning Robust Visual Features without Supervision》, M. Oquab, T. Darcet, T. Moutakanni et al., https://arxiv.org/abs/2304.07193
[5] 《A Cookbook of Self-Supervised Learning》, R. Balestiero, M. Ibrahim et. al, https://arxiv.org/abs/2304.12210





