Python 中的客户细分 实用方法
Python 中的客户细分实用方法:打造有效的市场定位
客户细分可以帮助企业定制其营销活动,并提高客户满意度。以下是如何进行客户细分的方法。
在功能上,客户细分涉及将客户基础分成不同的群组或细分,这是基于共享特性和行为。通过了解每个细分的需求和偏好,企业可以提供更加个性化和有效的营销活动,从而提高客户保留率和收入。
在此教程中,我们将通过结合两种基本技术来探索Python中的客户细分:RFM(最近性,频率,货币)分析和K-Means聚类。 RFM分析提供了一个评估客户行为的结构化框架,而K-Means聚类则提供了一种数据驱动的方法,将客户分组为有意义的细分。我们将使用来自零售行业的真实数据集:UCI机器学习库中的在线零售数据集。
从数据预处理到聚类分析和可视化,我们将逐步编写代码。所以让我们开始吧!
我们的方法:RFM分析和K-Means聚类
让我们首先确定我们的目标:通过将RFM分析和K-Means聚类应用于此数据集,我们希望了解客户行为和偏好。
RFM分析是一种简单而强大的方法,用于量化客户行为。 它根据三个关键维度对客户进行评估:
- 最近性(R):某个客户最近购买了什么时候?
- 频率(F):他们购买的频率有多高?
- 货币价值(M):他们花了多少钱?
我们将使用数据集中的信息计算最近性,频率和货币价值。 然后,我们将这些值映射到通常使用的1-5的RFM分数范围。
如果愿意,您可以使用这些RFM分数进行进一步的探索和分析。 但我们将尝试识别具有类似RFM特征的客户细分。 为此,我们将使用K-Means聚类,这是一种无监督机器学习算法,可以将相似的数据点分组到类群中。
所以让我们开始编写代码吧!
步骤1-导入必要的库和模块
首先,让我们根据需要导入所需的必要库和特定模块:
代码>从import导入pandas as pd import matplotlib.pyplot as plt from sklearn.cluster import KMeans
我们需要pandas和matplotlib进行数据探索和可视化,并使用scikit-learn的聚类模块中的 KMeans 类来执行K-Means聚类。
步骤2-加载数据集
如前所述,我们将使用“在线零售数据集”。 该数据集包含客户记录:交易信息,包括购买日期,数量,价格和客户ID。
让我们从URL将数据读入原始的excel文件中的pandas数据帧。
代码>#从UCI存储库加载数据集url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00352/Online%20Retail.xlsx"data = pd.read_excel(url)
或者,您可以下载数据集,并将excel文件读入pandas数据帧。
步骤3-探索和清理数据集
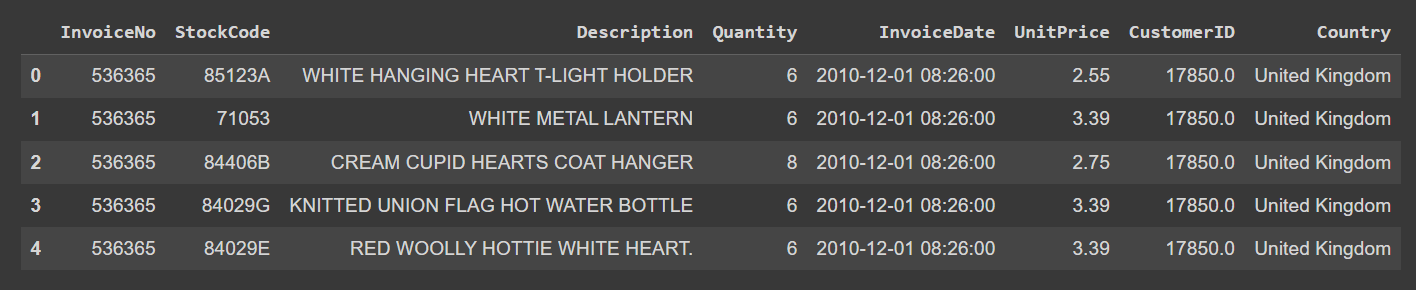
现在让我们开始探索数据集。查看数据集的前几行:
data.head()
现在在数据帧上调用describe()方法,以更好地了解数字特征:
data.describe()
我们看到,“CustomerID”列当前是浮点数值。在清洗数据时,我们将其转换为整数: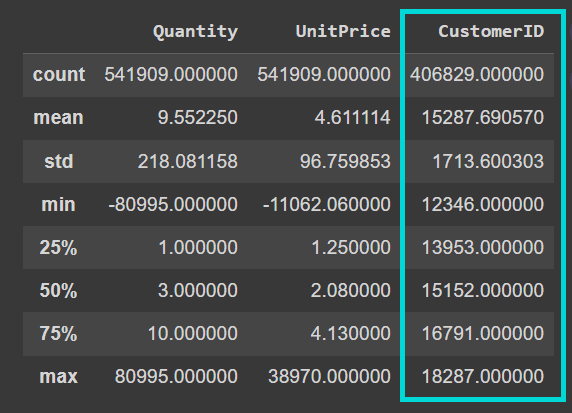
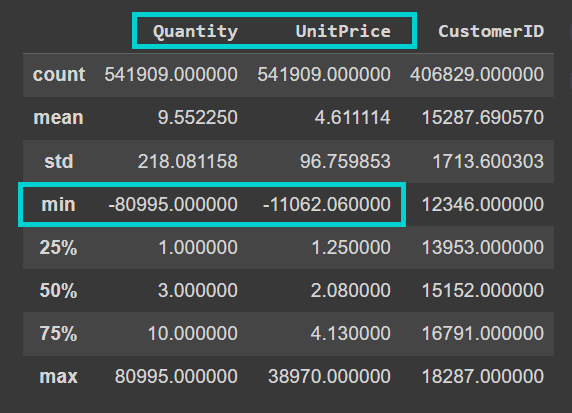
另请注意,数据集非常嘈杂。“Quantity”和“UnitPrice”列包含负值:
让我们仔细查看列及其数据类型:
data.info()
我们看到数据集有超过541K条记录,“Description”和“CustomerID”列包含缺失值: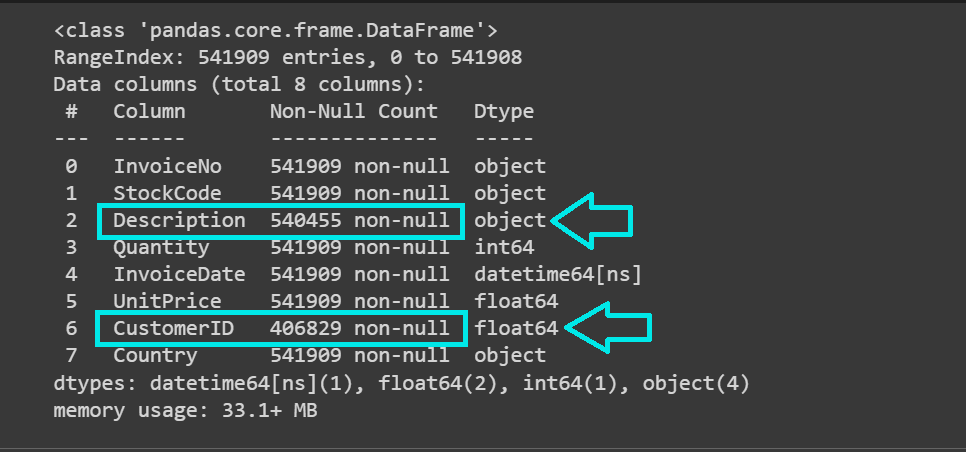 让我们统计每列中缺失值的数量:
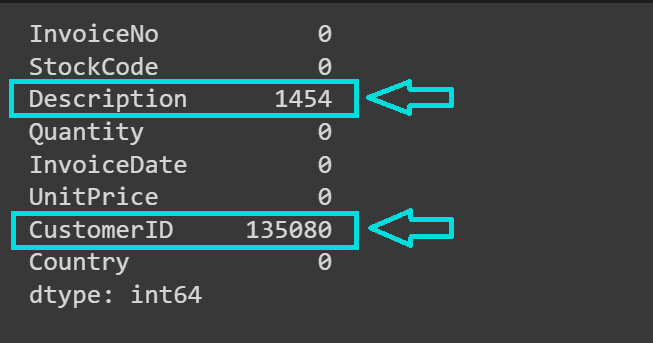
让我们统计每列中缺失值的数量:
# 检查每列中的缺失值
missing_values = data.isnull().sum()
print(missing_values)
如预期,“CustomerID”和“Description”列包含缺失值:
对于我们的分析,我们不需要“Description”列中的产品描述。然而,我们在分析的下一步中需要“CustomerID”。因此,让我们删除具有缺失“CustomerID”的记录:
# 删除具有缺失CustomerID的行
data.dropna(subset=['CustomerID'], inplace=True)
还要注意,“Quantity”和“UnitPrice”列的值应严格为非负值。但它们包含负值。因此,我们也需要删除具有负值的“Quantity”和“UnitPrice”的记录:
# 删除具有负Quantity和Price的行
data = data[(data['Quantity'] > 0) & (data['UnitPrice'] > 0)]
同时,让我们将“CustomerID”转换为整数:
data['CustomerID'] = data['CustomerID'].astype(int)
# 验证数据类型转换
print(data.dtypes) 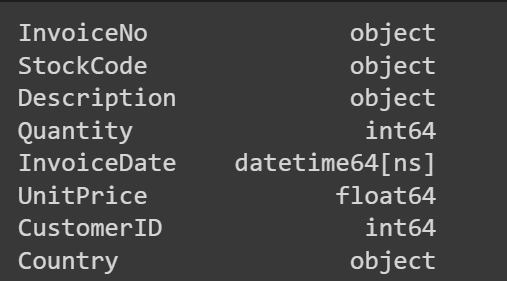
步骤4 – 计算最近性、频率和货币价值
让我们先定义一个参考日期snapshot_date,它比“InvoiceDate”列中最新日期晚一天:
snapshot_date = max(data['InvoiceDate']) + pd.DateOffset(days=1)
接下来,创建一个包含所有记录的Quantity*UnitPrice的“Total”列:
data['Total'] = data['Quantity'] * data['UnitPrice']
为了计算最近性、频率和货币价值,我们按CustomerID分组计算以下内容:
- 对于最近性,我们将计算最新购买日期与参考日期(
snapshot_date)之间的差值。这给出了客户距上次购买的天数。因此,较小的值表明客户最近进行过购买。但是在谈论最近性评分时,我们希望最近购买的客户具有较高的最近性评分,是吗?我们将在下一步处理这个。 - 由于频率衡量客户购买的频率,我们将其计算为每个客户的总唯一发票或交易数量。
- 货币价值量化客户的消费金额。因此,我们将跨交易计算总货币价值的平均值。
rfm = data.groupby('CustomerID').agg({ 'InvoiceDate': lambda x: (snapshot_date - x.max()).days, 'InvoiceNo': 'nunique', 'Total': 'sum'})
让我们重新命名列以提高可读性:
rfm.rename(columns={'InvoiceDate': 'Recency', 'InvoiceNo': 'Frequency', 'Total': 'MonetaryValue'}, inplace=True)rfm.head() 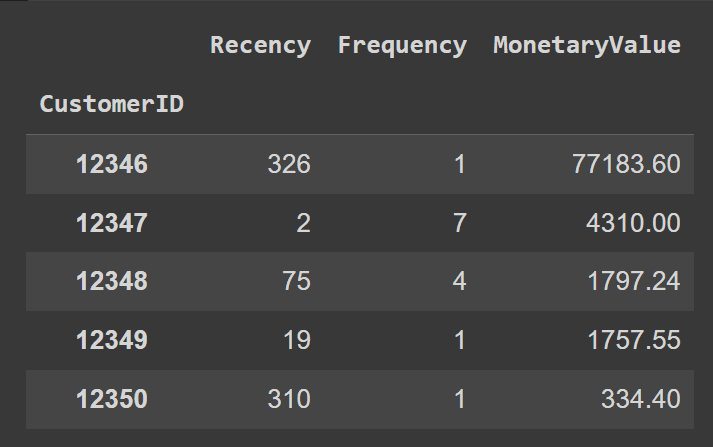
第五步 – 将RFM值映射到1-5的尺度上
现在让我们将”Recency”、”Frequency”和”MonetaryValue”列映射到1-5的尺度上,即{1,2,3,4,5}中的一个。
我们将为五个不同的箱子分配值,并将每个箱子映射到一个值。为了帮助我们修复边界,让我们使用”Recency”、”Frequency”和”MonetaryValue”列的分位数值:
rfm.describe()
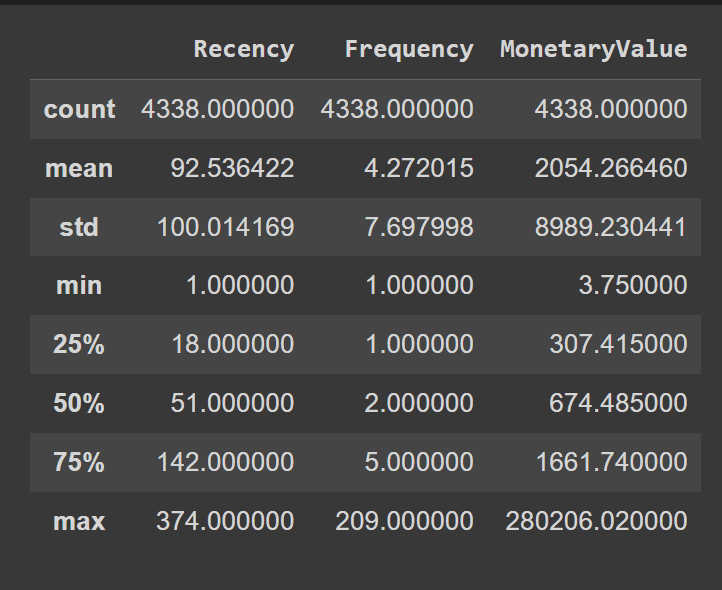
下面是自定义的箱子边界的定义:
# 计算Recency、Frequency和Monetary的自定义箱子边界recency_bins = [rfm['Recency'].min()-1, 20, 50, 150, 250, rfm['Recency'].max()]frequency_bins = [rfm['Frequency'].min() - 1, 2, 3, 10, 100, rfm['Frequency'].max()]monetary_bins = [rfm['MonetaryValue'].min() - 3, 300, 600, 2000, 5000, rfm['MonetaryValue'].max()]
现在我们已经定义了箱子边界,让我们将得分映射到1到5之间的相应标签:
# 根据自定义箱子计算Recency得分 rfm['R_Score'] = pd.cut(rfm['Recency'], bins=recency_bins, labels=range(1, 6), include_lowest=True)# 反转Recency得分,使更高的值表示更近期的购买rfm['R_Score'] = 5 - rfm['R_Score'].astype(int) + 1# 根据自定义箱子计算Frequency和Monetary得分rfm['F_Score'] = pd.cut(rfm['Frequency'], bins=frequency_bins, labels=range(1, 6), include_lowest=True).astype(int)rfm['M_Score'] = pd.cut(rfm['MonetaryValue'], bins=monetary_bins, labels=range(1, 6), include_lowest=True).astype(int)
注意,根据箱子边界,基于得分的R_Score是用于最近购买的1和250天前的所有购买的5。但是我们希望最近的购买具有R_Score为5,而250天前的购买具有R_Score为1。
为了实现所需的映射,我们执行:5 - rfm['R_Score'].astype(int) + 1。
让我们来看一下R_Score、F_Score和M_Score列的前几行:
# 打印RFM数据框的前几行以验证得分print(rfm[['R_Score', 'F_Score', 'M_Score']].head(10))
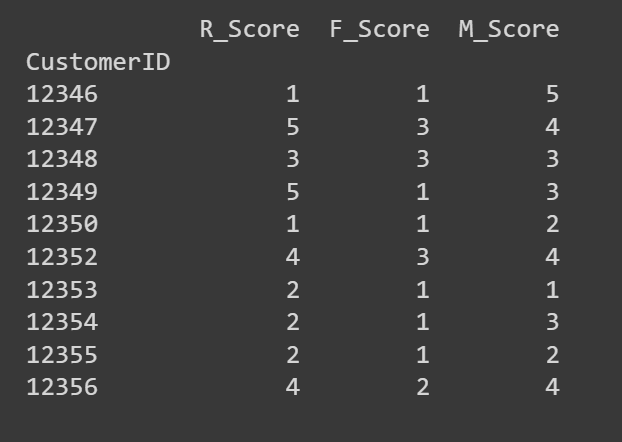
如果您愿意,您可以使用这些R、F和M得分进行深入分析。或使用聚类识别具有类似RFM特征的细分。我们选择后者!
第六步 – 进行K均值聚类
K-Means聚类对特征的尺度非常敏感。由于R、F和M的值都在相同的尺度上,我们可以继续进行聚类而无需再次缩放特征。
让我们提取R、F和M分数以进行K-Means聚类:
# 提取用于K-Means聚类的RFM分数X = rfm[['R_Score','F_Score','M_Score']]接下来,我们需要找到最佳的聚类数。为此,让我们针对一系列K值运行K-Means算法,并使用弯曲法则选择最佳的K:
#为不同的K值计算惯性(平方距离的和)inertia = []for k in range (2,11): kmeans = KMeans(n_clusters = k,n_init = 10,random_state = 42) kmeans.fit(X) inertia.append(kmeans.inertia_)#绘制弯曲曲线plt.figure(figsize =(8,6),dpi = 150)plt.plot(range(2, 11),inertia,marker ='o') plt.xlabel('Cluster数(k)')plt.ylabel('Inertia')plt.title('K-means聚类的弯曲曲线')plt.grid(True)plt.show() 我们可以看到曲线在4个聚类的位置弯曲。因此,让我们将客户群分为四个部分。
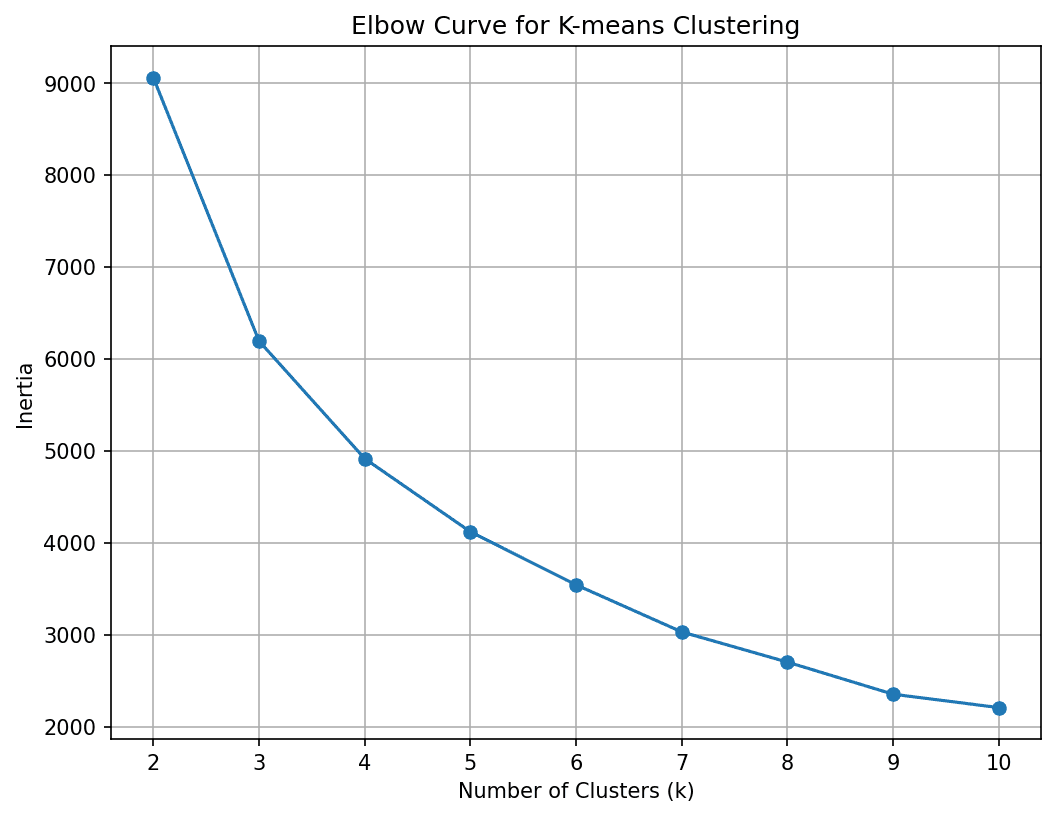
我们已将K固定为4。因此,让我们运行K-Means算法,为数据集中的所有点获取聚类分配:
# 使用最佳的K执行K-means聚类best_kmeans = KMeans(n_clusters=4, n_init=10, random_state=42)rfm['Cluster'] = best_kmeans.fit_predict(X) 第7步 – 解释聚类以识别客户群
既然我们有了聚类,让我们根据RFM分数来尝试对它们进行描述。
# 按照聚类分组并计算平均值cluster_summary = rfm.groupby('Cluster').agg({ 'R_Score': 'mean' 'F_Score': 'mean' 'M_Score': 'mean' }) .reset_index()每个聚类的平均R、F和M分数应该已经让您了解了其特点。
print(cluster_summary)但让我们将聚类的平均R、F和M分数可视化,以便易于解释:
colors = ['#3498db','#2ecc71','#f39c12','# C9B1BD']#为每个聚类绘制平均RFM分数plt.figure(figsize =(10,8),dpi = 150)#绘制Avg Recencyplt.subplot(3,1,1)bars = plt.bar(cluster_summary.index,cluster_summary['R_Score'],color = colors)plt.xlabel('Cluster')plt.ylabel('Avg Recency')plt.title('每个聚类的平均最新性')plt.grid(True,linestyle ='--',alpha = 0.5)plt.legend(bars,cluster_summary.index,title ='聚类')#绘制平均频率plt.subplot(3,1,2)bars = plt.bar(cluster_summary.index,cluster_summary['F_Score'],color = colors)plt.xlabel('Cluster')plt.ylabel('Avg Frequency')plt.title('每个聚类的平均频率')plt.grid(True,linestyle ='--',alpha = 0.5)plt.legend(bars,cluster_summary.index, title ='聚类')#绘制平均货币plt.subplot(3,1,3)bars = plt.bar(cluster_summary.index ,cluster_summary['M_Score'],color = colors)plt.xlabel('Cluster')plt.ylabel('Avg Monetary')plt.title('每个聚类的平均货币价值')plt.grid(True,linestyle ='--',alpha = 0.5)plt.legend(bars,cluster_summary.index,title ='聚类')plt.tight_layout()plt.show() 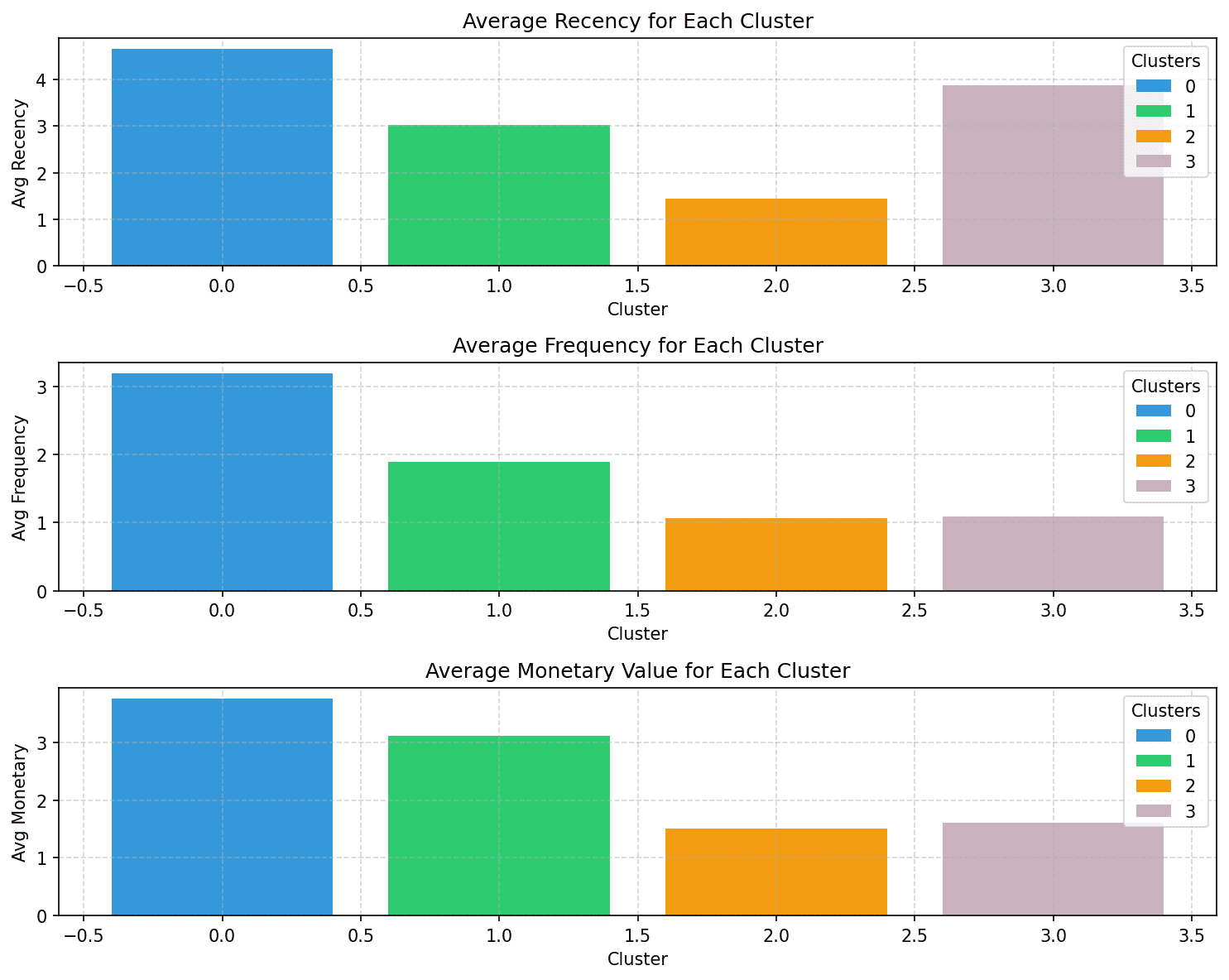
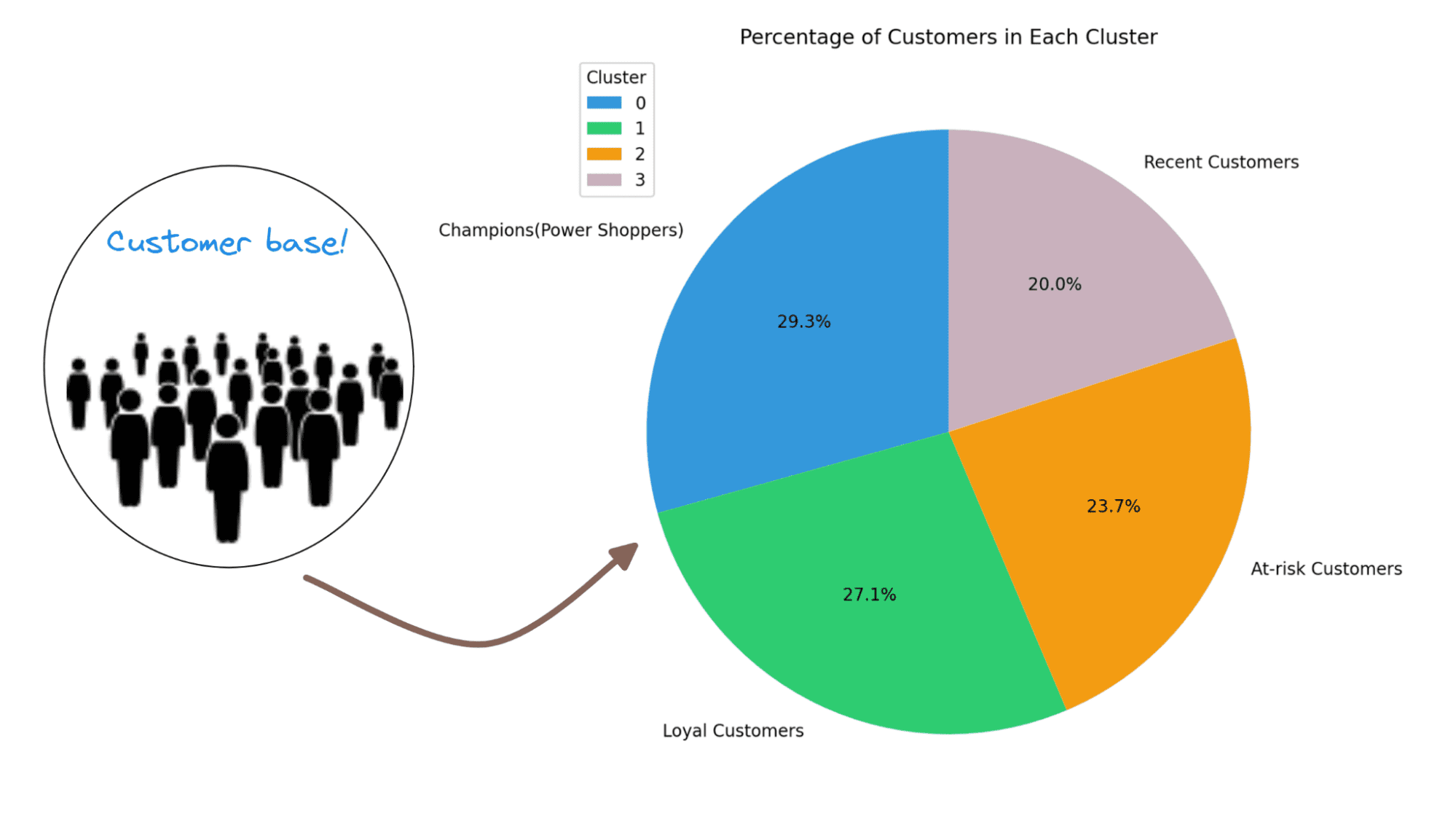
请注意,每个细分中的客户可以根据最近性、频率和金额特征进行描述:
- 聚类 0:在这四个聚类中,此聚类具有最高的最近性、频率和金额特征。我们将这个聚类的客户称为冠军(或高消费者)。
- 聚类 1:此聚类特点是中等的最近性、频率和金额特征。这些客户仍然比聚类 2 和聚类 3 更多地消费和购买。我们将他们称为忠诚的客户。
- 聚类 2:此聚类中的客户倾向于消费较少。他们不经常购买,最近也没有购买。这些客户很可能是不活跃或有风险的客户。
- 聚类 3:此聚类以高最近性、相对较低的频率和中等金额特征为特点。因此,这些是最近购买的客户,有可能成为长期客户。
以下是您可以定制营销活动的一些示例,以便针对每个细分的客户来增强客户参与和保留:
- 针对冠军/高消费者:提供个性化的特别折扣、提前访问和其他高级特权,使他们感到被重视和赏识。
- 针对忠诚的客户:感激活动、推荐奖金和忠诚度奖励。
- 针对有风险的客户:重新参与努力,包括运行折扣或促销活动以鼓励购买。
- 针对最近购买的客户:针对品牌进行定向宣传活动,并对后续购买提供折扣。
了解不同细分中客户所占的百分比也是有帮助的。这将进一步帮助您简化营销活动并发展您的业务。
让我们使用饼图来可视化不同聚类的分布:
cluster_counts = rfm['Cluster'].value_counts()colors = ['#3498db', '#2ecc71', '#f39c12','#C9B1BD']# 计算客户的总数total_customers = cluster_counts.sum()# 计算每个聚类中客户所占的百分比percentage_customers = (cluster_counts / total_customers) * 100labels = ['冠军(高消费者)','忠诚的客户','有风险的客户','最近购买的客户']# 创建一个饼图plt.figure(figsize=(8, 8),dpi=200)plt.pie(percentage_customers, labels=labels, autopct='%1.1f%%', startangle=90, colors=colors)plt.title('每个聚类中的客户百分比')plt.legend(cluster_summary['Cluster'], title='聚类', loc='upper left')plt.show()
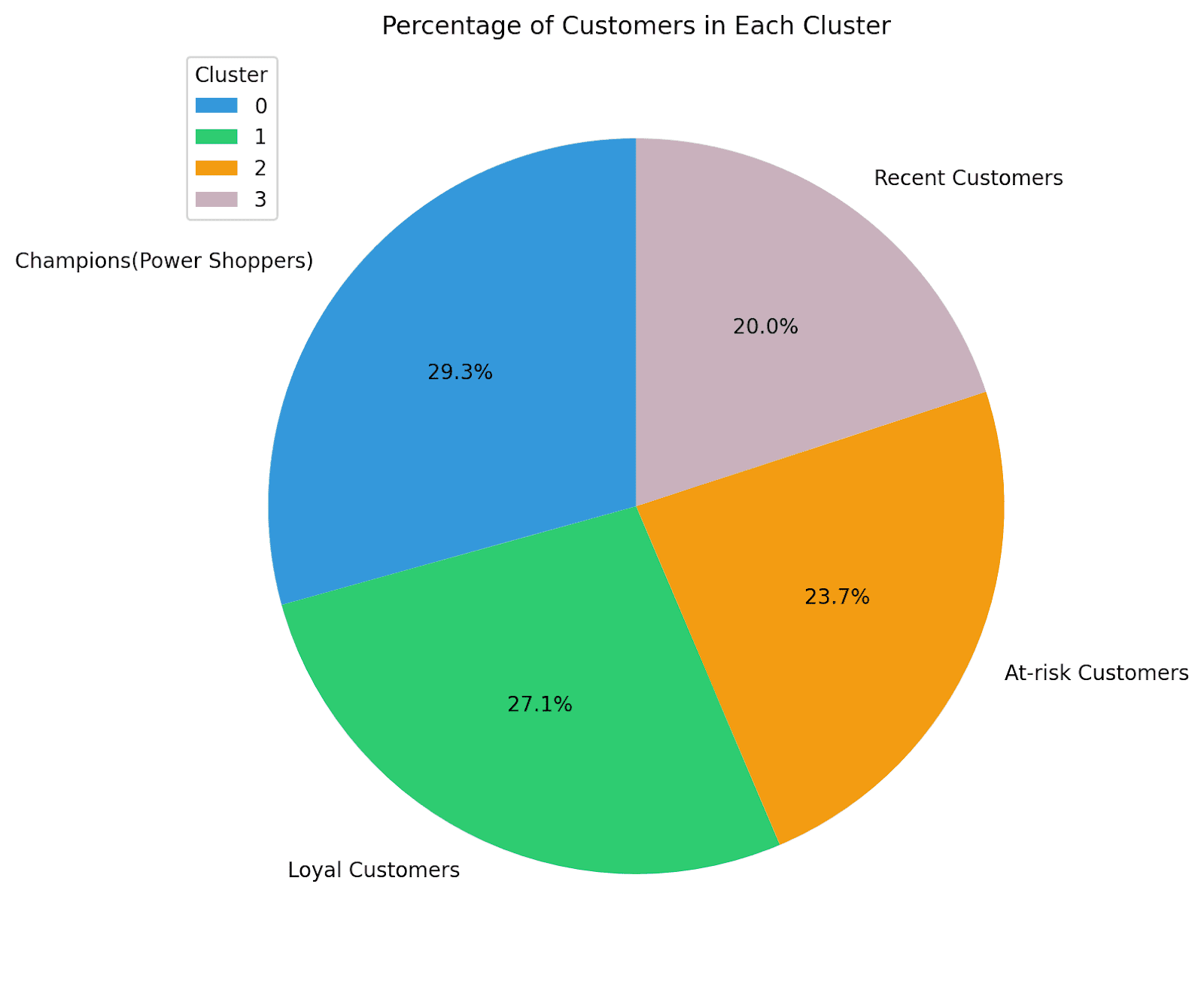
这就是我们的结果!对于这个例子来说,我们在各个细分中有相当均匀的客户分布。因此,我们可以投入时间和精力来保留现有客户,重新参与有风险的客户,并教育最近购买的客户。
总结
就是这样!我们通过 7 个简单步骤,从超过 154,000 条客户记录获得了 4 个聚类。我希望您理解客户细分如何帮助您做出基于数据的决策,影响业务增长和客户满意度,从而实现:
- 个性化:细分使企业能够根据每个客户群组的特定需求和兴趣来调整其营销信息、产品推荐和促销活动。
- 改善目标:通过识别高价值和有风险的客户,企业可以更有效地分配资源,将努力集中在最有可能产生结果的地方。
- 客户保留:细分帮助企业通过了解如何保持客户参与和满意来创建保留策略。
作为下一步,尝试将此方法应用于另一个数据集,记录您的经验,并与社区分享!但请记住,有效的客户细分和运行定向营销活动需要对客户群体及其演变有很好的理解。因此,需要定期分析以在时间上完善您的策略。
数据集来源
在线零售数据集 根据 知识共享 署名 4.0 国际许可进行许可:
在线零售。 (2015)。 UCI 机器学习库。https://doi.org/10.24432/C5BW33。 Bala Priya C来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她感兴趣和擅长的领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过撰写教程、指南、观点文章等来学习和与开发者社区分享她的知识。
[Bala Priya C](https://twitter.com/balawc27) 来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她感兴趣和擅长的领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过撰写教程、指南、观点文章等来学习和与开发者社区分享她的知识。






